11.15. スプリットブレインの管理
スプリットブレインは、クラスター内の異なるデータソースで、そのデータの現在の状態について、さまざまなデータソースが異なる場合に発生するデータの不整合状態です。これは、ネットワーク設計のサーバーが、サーバー間で通信せず、データを同期していないサーバーに基づく障害状態が原因で発生する可能性があります。
Red Hat Gluster Storage では、スプリットブレインは、複製設定の Red Hat Gluster Storage ボリュームに該当する用語です。レプリカペアを構成する異なるブリックにある同じファイルのコピーが、データやメタデータコンテンツが一致しなくなると、スプリットブレインが発生するとファイルがスプリットブレインしていると見なされます。このシナリオでは、バックエンドブリックの不一致を確認して、どのファイル (ソース) と、修復が必要なファイル (sink) を決定できます。
glusterFS の AFR トランスレーターは、拡張属性を使用してファイル上の操作を追跡します。これらの属性は、ファイルに修復が必要な場合に正しいソースであるブリックを決定します。ファイルがクリーンな場合、拡張属性はすべてゼロで、修復は不要であることを示します。修復が必要な場合、それらは区別可能なソースおよびシンクがある方法でマークされ、修復は自動的に行われます。ただし、スプリットブレインが発生すると、両方のブリックがそれ自体をソースとしてマークし、自動修復ができなくなります。
スプリットブレインは、同じファイルのコピーを複数コピーし、Red Hat Gluster Storage がどのバージョンが正しいかを判断できない場合に発生します。アプリケーションは、スプリットブレインが発生した場合に異議申し立てされたファイルでの read および write などの特定の操作の実行は制限されます。ファイルにアクセスしようとすると、アプリケーションが問題のファイルで入出力エラーを受信します。
Red Hat Gluster Storage で発生する 3 種類のスプリットブレインは、以下のとおりです。
- データスプリットブレイン: スプリットブレインの下にあるファイルのコンテンツはレプリカのペアで異なり、自動修復はできません。Red Hat では、マウントポイントと CLI からデータスプリットブレインを解決できます。マウントポイントからデータスプリットブレインから回復する方法は、「 マウントポイントからのファイルスプリットブレインの復旧」 を参照してください。CLIS を使用してデータをスプリットブレインからリカバリーする方法は、「gluster CLI からのファイルスプリットブレインのリカバリー」 を参照してください。
- メタデータスプリットブレイン: ユーザー定義の拡張属性などのファイルのメタデータは異なり、自動修復はできません。データのスプリットブレインと同様に、メタデータスプリットブレインは、マウントポイントと CLI の両方から解決することもできます。マウントポイントからメタデータスプリットブレインから回復する方法は、「 マウントポイントからのファイルスプリットブレインの復旧」 を参照してください。CLI を使用してメタデータスプリットブレインから回復する方法は、「gluster CLI からのファイルスプリットブレインのリカバリー」 を参照してください。
- エントリースプリットブレイン: エントリースプリットブレインには、以下の 2 つのタイプを使用できます。
- GlusterFS 内部ファイル識別子または GFID スプリットブレイン: 異なるレプリカペアのファイルまたはディレクトリーの GFID が異なる場合に発生します。
- タイプ不一致のスプリットブレイン: レプリカのペアに保存されているファイル/ディレクトリーのタイプが異なるものの、同じ名前のファイルである場合に発生します。
Red Hat Gluster Storage 3.4 以降では、gluster CLI から GFID スプリットブレインを解決できます。詳細は、「gluster CLI からの GFID スプリットブレインのリカバリー」 を参照してください。バックエンドのファイルの内容を検査し、実際のコピー (ソース) を決定し、修復が自動的に行われるように適切な拡張属性を変更することで、スプリットブレインを手動で解決できます。
11.15.1. スプリットブレインの防止
リンクのコピーリンクがクリップボードにコピーされました!
信頼できるストレージプールでスプリットブレインを防ぐには、サーバー側とクライアント側のクォーラムを設定する必要があります。
11.15.1.1. サーバー側のクォーラムの設定
リンクのコピーリンクがクリップボードにコピーされました!
信頼できるストレージプールのクォーラム設定は、信頼できるストレージプールが追跡できるサーバー障害の数を決定します。追加の障害が発生すると、信頼できるストレージプールは利用できなくなります。サーバーの障害が多すぎる場合や、信頼できるストレージプールノード間の通信に問題がある場合は、信頼できるストレージプールをオフラインにしてデータの損失を防ぐ必要があります。
信頼できるストレージプールレベルでクォーラム比率を設定したら、cluster.server-quorum-type ボリュームオプションを
server として設定して、特定のボリュームでクォーラムを有効にする必要があります。このボリュームオプションについての詳細は、「ボリュームオプションの設定」 を参照してください。
信頼できるストレージプールのネットワークパーティションを防ぐために、クォーラムを設定する必要があります。ネットワークパーティションは、一部のノードセットが、ネットワークの機能部分全体で連携できる可能性がありますが、ネットワークの別の部分にある別のノードセットと通信できないシナリオです。これにより、分散システムでスプリットブレインなどの望ましくない状況が発生する可能性があります。スプリットブレインが発生した場合は、不整合を避けるために、1 つ以上のパーティションにあるすべてのノードを停止する必要があります。
このクォーラムはサーバー側の、
glusterd サービスです。マシンの glusterd サービスがクォーラムが満たされていないことを確認するたびに、ブリックがダウンし、データのスプリットブレインを防ぎます。ネットワーク接続が切断され、クォーラムが回復すると、ボリュームのブリックが元に戻ります。クォーラムがボリュームで満たされない場合、ボリューム設定またはピアの追加または割り当てを更新するコマンドは使用できません。どちらにも記載されているように、glusterd サービスは実行されず、ダウンしている 2 つのマシン間のネットワーク接続は同等に処理されます。
信頼できるストレージプールにクォーラムの割合を設定できます。ネットワーク障害によりクォーラムの割合が満たされない場合、それらのノードのクォーラムに参加しているボリュームのブリックはオフラインになります。デフォルトでは、アクティブなノードのパーセンテージが全ストレージノードの 50% を超える場合に、クォーラムが満たされます。ただし、クォーラム比率が手動で設定されている場合、クォーラムは、合計ストレージノードのアクティブなストレージノードのパーセンテージがセット値よりも大きいか、またはこれと等しい場合にのみ満たされます。
クォーラム比率を設定するには、以下のコマンドを使用します。
# gluster volume set all cluster.server-quorum-ratio PERCENTAGE
たとえば、信頼できるストレージプールのクォーラムを 51% に設定するには、次のコマンドを実行します。
# gluster volume set all cluster.server-quorum-ratio 51%
この例では、クォーラム比率を 51% に設定すると、信頼できるストレージプールのノードの半分がオンラインになり、指定の時間におけるそのノード間のネットワーク接続が任意になります。ストレージプールでネットワークの切断が発生すると、それらのノードで実行しているブリックは停止して、さらなる書き込みを防ぐことができます。
以下のコマンドを実行して、特定のボリュームでクォーラムがサーバー側のクォーラムに参加できるようにする必要があります。
# gluster volume set VOLNAME cluster.server-quorum-type server重要
2 ノードの信頼済みストレージプールでは、クォーラムの割合を 50% より大きく し、2 つのノードが相互に分離した状態にすることができます。
2 つのノードを持つレプリケートされたボリュームと、各マシンで 1 つのブリックが有効にされており、サーバー側のクォーラムが有効で、ノードの 1 つがオフラインになると、クォーラム設定が原因で他のノードもオフラインになります。そのため、レプリケーションによって提供される高可用性は効率的ではありません。この状況を防ぐために、ブリックを含まない信頼できるストレージプールにダミーノードを追加できます。これにより、データが含まれるノードの 1 つがオフラインであっても、他のノードはオンラインのままになります。ダミーノードとデータノードの 1 つがオフラインになると、他のノードのブリックもオフラインになり、データが利用できなくなることに注意してください。
11.15.1.2. クライアント側クォーラムの設定
リンクのコピーリンクがクリップボードにコピーされました!
デフォルトでは、レプリケーションが設定されると、レプリカグループ内の少なくとも 1 つのブリックが利用できる限り、クライアントはファイルを変更できます。ネットワークのパーティション設定が発生すると、異なるクライアントはレプリカセット内の異なるブリックにのみ接続できるため、異なるクライアントが 1 つのファイルを同時に変更できる可能性があります。
たとえば、同じファイルを修正したい 2 台のクライアントである C1 および C2 が 3 方向の複製されたボリュームにアクセスするとします。クライアント C1 がブリック B1 のみにアクセスでき、クライアント C2 にはブック B2 のみにアクセスでき、両方のクライアントはファイルを独立して変更でき、ボリュームにスプリットブレイン条件を作成できます。ファイルは使用できないため、問題を修正するには手動での介入が必要になります。
クライアント側のクォーラムを使用すると、管理者はボリュームのデータを変更できるようにするためにクライアントがアクセスできる必要があるブリックの最小数を設定できます。クライアント側のクォーラムが一致しない場合、レプリカセットのファイルは読み取り専用として処理されます。これは、3 方向のレプリケーションが設定されている場合に役に立ちます。
クライアント側のクォーラムはボリュームごとに設定され、ボリューム内のすべてのレプリカセットに適用されます。Y ボリュームセットの X に対してクライアント側のクォーラムを満たさないと、X ボリュームセットのみは読み取り専用として処理されます。残りのボリュームセットは、データ変更を許可し続けます。
以前のリリースでは、クォーラムが満たされないと、レプリカサブボリュームは読み取り専用になります。rhgs-3.4.3 では、すべてのファイル操作が EROFS になるのではなく ENOTCONN エラーを出して失敗するため、サブボリュームは使用できなくなります。これは、cluster.quorum-reads ボリュームオプションもサポートされていないことを意味します。
クライアント側のクォーラムオプション
- cluster.quorum-count
- 書き込みを許可するのに必要なブリックの最小数。これはボリュームごとに設定されます。有効な値は、レプリカセットの
1からブリックの数になります。このオプションは、書き込み動作を決定するためにcluster.quorum-typeオプションによって使用されます。このオプションは、cluster.quorum-type =fixedオプションと併用し、クォーラムに参加するためにアクティブなブリックの数を指定します。quorum-type がautoの場合、このオプションには大きな影響はありません。 - cluster.quorum-type
- クライアントがボリュームへの書き込みを許可されるタイミングを決定します。有効な値は
fixedおよびautoです。cluster.quorum-typeがfixedの場合は、レプリカセットで利用可能なブリックの数がcluster.quorum-countオプションの値以上であれば、書き込みが許可されます。cluster.quorum-typeがautoの場合、レプリカセット内のブリックの 50% 以上が利用できる場合に書き込みが許可されます。一連のブリックを持つレプリカセットでは、ブリックの 50% が利用可能であれば、書き込みを続行するには、レプリカセットの最初のブリックが利用可能でなければなりません。3 方向のレプリケーション設定では、スプリットブレインを回避するためにcluster.quorum-typeをautoに設定することが推奨されます。クォーラムを満たさないと、レプリカのペアは読み取り専用になります。
例11.7 クライアント側のクォーラム
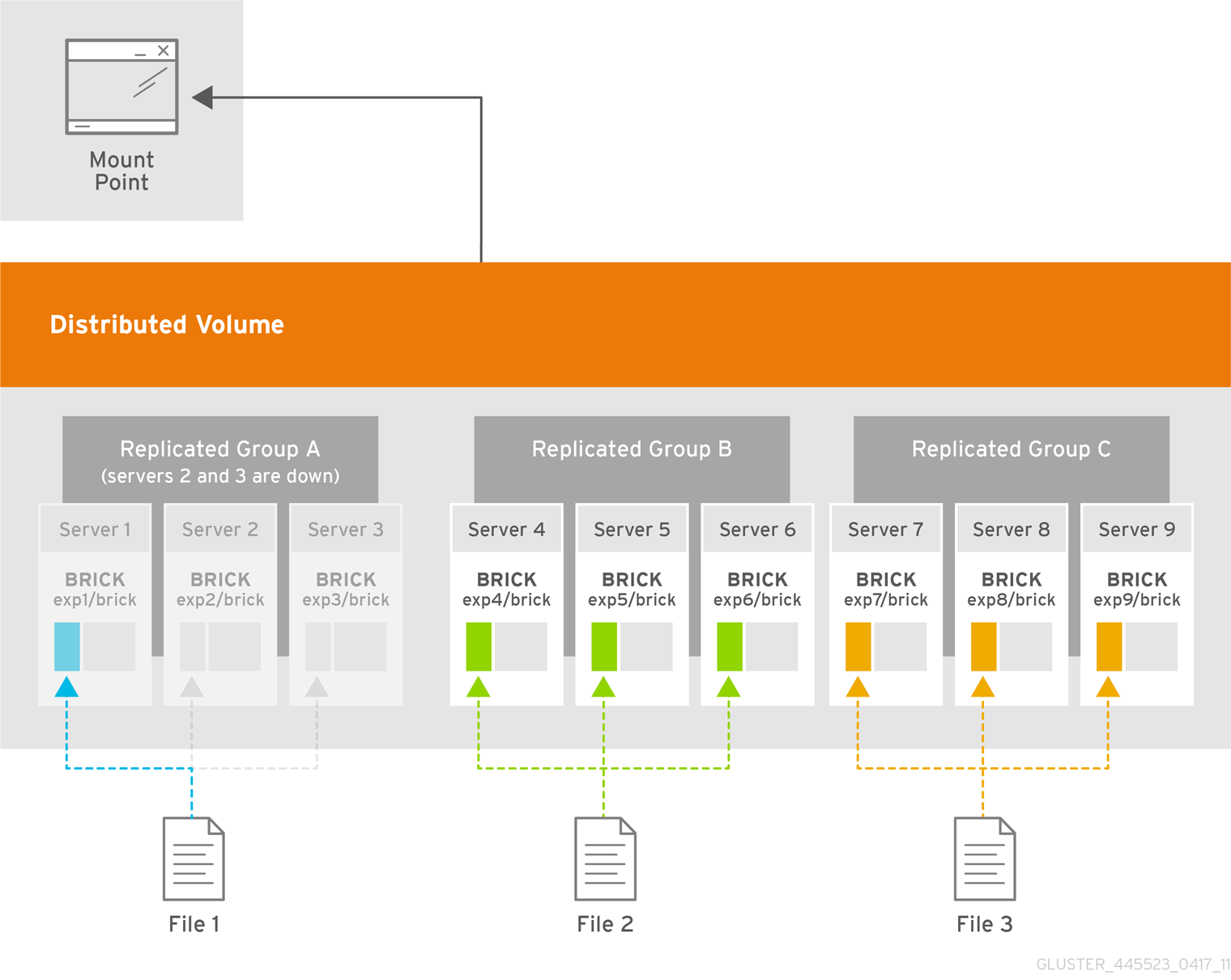
上記のシナリオでは、レプリカグループ
A にクライアント側のクォーラムが満たされないと、レプリカグループ A のみが読み取り専用になります。レプリカグループ B および C を続行して、データの変更を可能にします。
cluster.quorum-type および cluster.quorum-count オプションを使用してクライアント側のクォーラムを設定します。
重要
Red Hat Gluster Storage を Red Hat Enterprise Virtualization と統合すると、gluster volume set VOLNAME group virt コマンドを実行するときにクライアント側のクォーラムが有効になります。2 つのレプリカを設定すると、レプリカペアの最初のブリックがオフラインの場合、クォーラムは満たされず、書き込みは拒否されるため、仮想マシンは一時停止されます。
一貫性は、耐障害性のコストで実現されます。整合性よりもフォールトトレランスが優先される場合は、次のコマンドを使用してクライアント側のクォーラムを無効にします。
# gluster volume reset VOLNAME quorum-type例: スプリットブレインのシナリオを回避するためにサーバー側およびクライアント側のクォーラムを設定
この例では、スプリットブレインのシナリオを回避するために、Distribute Replicate ボリュームでサーバー側およびクライアント側のクォーラムを設定する方法を説明します。この例の設定には、3 X 3(9 ブリック) の Distribute Replicate が設定されています。
# gluster volume info testvol
Volume Name: testvol
Type: Distributed-Replicate
Volume ID: 0df52d58-bded-4e5d-ac37-4c82f7c89cfh
Status: Created
Number of Bricks: 3 x 3 = 9
Transport-type: tcp
Bricks:
Brick1: server1:/rhgs/brick1
Brick2: server2:/rhgs/brick2
Brick3: server3:/rhgs/brick3
Brick4: server4:/rhgs/brick4
Brick5: server5:/rhgs/brick5
Brick6: server6:/rhgs/brick6
Brick7: server7:/rhgs/brick7
Brick8: server8:/rhgs/brick8
Brick9: server9:/rhgs/brick9
サーバー側のクォーラムの設定
以下のコマンドを実行して、特定のボリュームでクォーラムがサーバー側のクォーラムに参加できるようにします。
# gluster volume set VOLNAME cluster.server-quorum-type server
信頼できるストレージプールのクォーラムを 51% に設定するには、次のコマンドを実行します。
# gluster volume set all cluster.server-quorum-ratio 51%
この例では、クォーラム比率を 51% に設定すると、信頼できるストレージプールのノードの半分がオンラインになり、指定の時間におけるそのノード間のネットワーク接続が任意になります。ストレージプールでネットワークの切断が発生すると、それらのノードで実行しているブリックは停止して、さらなる書き込みを防ぐことができます。
クライアント側のクォーラムの設定
アクティブな複製ブリックの割合が、そのレプリカを構成するブリックの合計数の 50% を超える場合にのみ、ファイルに書き込みできるようにするには、
quorum-type オプションを auto に設定します。
# gluster volume set VOLNAME quorum-type auto
この例では、レプリカのペアにはブリックが 2 つしかないため、書き込みを可能にするために最初のブリックを起動して実行する必要があります。
重要
クォーラムを満たすには、atleast n/2 ブリックを稼働させる必要があります。レプリカセット内のブリック数 (
n) が偶数の場合は、n/2 数はプライマリーブリックで構成される必要があり、稼働して実行する必要があります。n が正の数の場合には、n/2 数にブリックを起動して実行できます。つまり、プライマリーブリックは起動せず、書き込みを許可するために稼働する必要があります。