31.4. パフォーマンステストの手順
本セクションの目的は、VDO をインストールしたデバイスのパフォーマンスプロファイルを構築することです。各テストは、VDO のインストール有無にかかわらず実行する必要があります。これにより、VDO のパフォーマンスをベースシステムのパフォーマンスに関連付けて評価できるようになります。
31.4.1. フェーズ 1 - I/O 深さの影響、固定 4KB ブロック
リンクのコピーリンクがクリップボードにコピーされました!
これらのテストの目的は、アプリケーションの最適なスループットと最小のレイテンシーを生成する I/O 深度を決定することです。VDO は、従来のストレージデバイスで使用されていた従来の 512 B ではなく、4KB のセクターサイズを使用します。セクターサイズが大きいため、大容量のストレージをサポートし、パフォーマンスを向上させ、ほとんどのオペレーティングシステムで使用されるキャッシュバッファーサイズと一致させることができます。
- 4KB I/O および I/O 深度が 1、8、16、32、64、128、256、512、1024 で、フォーコーナーテストを実行します。
- 100% シーケンシャル読み取り (固定 4KB *)
- 100% シーケンシャル書き込み (固定 4KB)
- 100% ランダム読み取り (固定 4KB *)
- 100% ランダム書き込み (固定 4KB **)
* 最初に write fio ジョブを実行して、読み取りテスト中に読み取り可能な領域を事前に入力します。** 4 KB のランダム書き込み I/O の実行後、VDO ボリュームを再作成します。シェルテスト入力要因の例 (書き込み):# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write --bs=4096 --name=vdo --filename=/dev/mapper/vdo0 \ --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300\ --direct=1 --iodepth=$depth --scramble_buffers=1 --offset=0 \ --size=100g done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
- テストを繰り返してフォーコーナーテストを完了します:
--rw=randwrite、--rw=read、および--rw=randread.
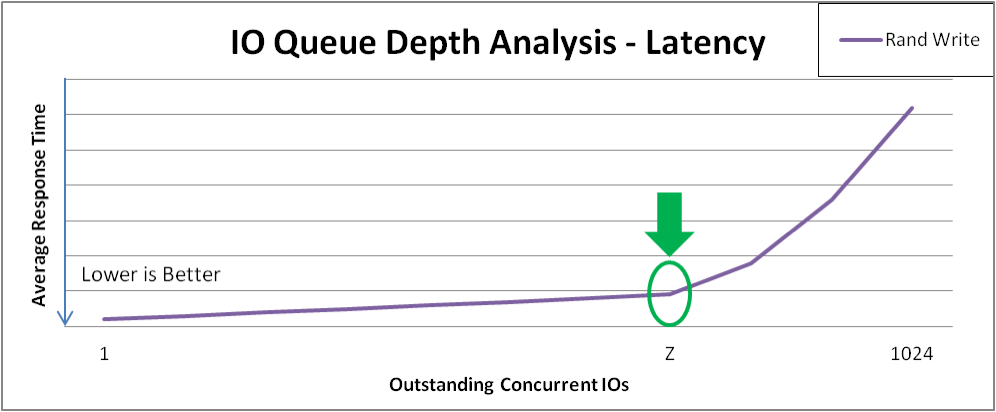
結果は以下のようなグラフになります。重要な点は、範囲全体の動作と、I/O 深度が増えるとスループットの向上が低下することが証明される変曲点です。おそらく、シーケンシャルアクセスとランダムアクセスは異なる値でピークに達しますが、すべてのタイプのストレージ設定で異なる可能性があります。図31.1「I/O 深度分析」 で、各パフォーマンス曲線の急な折れ曲がりに注意してください。マーカー 1 はポイント X でのピークシーケンシャルスループットを識別し、マーカー 2 はポイント Z でのピークランダム 4KB スループットを識別します。
- この特定のアプライアンスは、シーケンシャル 4 KB I/O 深度 > X の恩恵を受けません。この深度を超えると、帯域幅の利得が減少し、I/O 要求が増えるごとに平均要求レイテンシーが 1:1 に増加します。
- この特定のアプライアンスは、ランダム 4KB の I/O 深度 > Z の恩恵を受けません。この深度を超えると、帯域幅の利得が減少し、追加の I/O 要求ごとに平均要求レイテンシーが 1:1 増加します。
図31.1 I/O 深度分析

図31.2「ランダム書き込みの I/O の増加による遅延応答」 は、図31.1「I/O 深度分析」 の曲線が急に折れ曲がった後のランダムな書き込みレイテンシーの例を示しています。ベンチマークの実践では、この点で応答時間のペナルティーが最小となる最大スループットを検証する必要があります。このアプライアンスの例のテスト計画を進めるにつれ、I/O 深度 = Z で追加データを収集します。
図31.2 ランダム書き込みの I/O の増加による遅延応答
31.4.2. フェーズ 2 - I/O リクエストサイズの影響
リンクのコピーリンクがクリップボードにコピーされました!
このテストの目的は、前のステップで決定された最適な I/O 深度でテスト対象システムの最高のパフォーマンスを生み出すブロックサイズを理解することです。
- 8KB から 1MB の範囲でさまざまなブロックサイズ (2 の累乗) を使用して、固定 I/O 深度で フォーコーナーテストを実行します。読み取る領域を事前に入力し、テストの合間にボリュームを再作成することを忘れないでください。
- I/O 深度を 「フェーズ 1 - I/O 深さの影響、固定 4KB ブロック」 で決定された値に設定します。テスト入力要因の例 (読み取り):
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
- テストを繰り返してフォーコーナーテストを完了します:
--rw=randwrite、--rw=read、および--rw=randread.
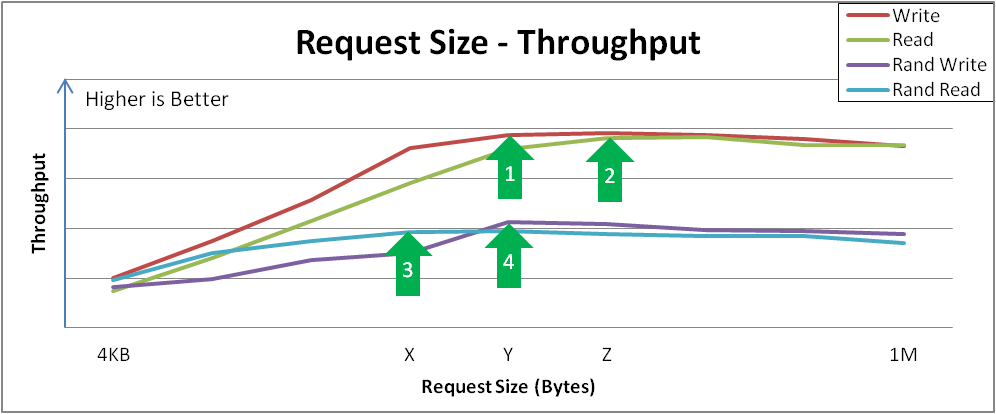
この結果には、いくつかの重要な点があります。この例では、以下のように設定されています。
- シーケンシャル書き込みは、要求サイズ Y でピークスループットに達します。この曲線は、設定可能であるか、特定の要求サイズによって自然に支配されるアプリケーションが、パフォーマンスをどのように認識するかを示しています。4KB の I/O はマージの恩恵を受ける可能性があるため、要求サイズが大きいほどスループットが向上することがよくあります。
- シーケンシャル読み取りのスループットは、Z 点で似たようなピークスループットに到達します。これらのピークの後、I/O が完了するまでの全体的な遅延は、追加のスループットなしで増加することに注意してください。このサイズよりも大きな I/O を受け付けないようにデバイスを調整することが推奨されます。
- ランダム読み取りは、ポイント X でピークスループットを達成します。デバイスによっては、大規模なリクエストサイズのランダムアクセスで、ほぼシーケンシャルスループット率を実現する可能性がありますが、純粋なシーケンシャルアクセスと異なる場合は、より多くのペナルティーを受けることになります。
- ランダム書き込みは、ポイント Y でピークスループットを達成します。ランダム書き込みは、重複排除デバイスの相互作用が最も多く、VDO は、特に要求サイズや I/O 深度が大きい場合に高いパフォーマンスを実現します。
このテスト図31.3「要求サイズとスループットの分析、および重要な変曲点」の結果は、ストレージデバイスの特性や、特定のアプリケーションのユーザーエクスペリエンスを把握する上で役立ちます。異なるリクエストサイズでパフォーマンスを向上させるためにさらに調整が必要な場合は、Red Hat セールスエンジニアに相談してください。
図31.3 要求サイズとスループットの分析、および重要な変曲点
31.4.3. フェーズ 3 - 読み取り/書き込み I/O のミキシングの影響
リンクのコピーリンクがクリップボードにコピーされました!
このテストの目的は、混合 I/O 負荷 (読み取り/書き込み) で提示されたときに VDO を持つアプライアンスがどのように動作するかを理解し、最適なランダムキューの深度と、4KB から 1 MB の要求サイズでの読み取り/書き込み混合の影響を分析することです。ケースに適したものを使用してください。
- 固定の I/O 深度、8 KB から 256 KB の範囲の可変ブロックサイズ (2 の累乗)、0% から初めて 10 % 刻みで読み取り率を設定し、フォーコーナーテストを実行します。読み取る領域を事前に入力し、テストの合間にボリュームを再作成することを忘れないでください。
- I/O 深度を 「フェーズ 1 - I/O 深さの影響、固定 4KB ブロック」 で決定された値に設定します。テスト入力要因の例 (読み取り/書き込みの組み合わせ):
# z=[see previous step] # for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw --rwmixread=$readmix --bs=$iosize\k --name=vdo \ --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \ --norandommap --runtime=300 --direct=0 --iodepth=$z --scramble_buffers=1 \ --offset=0 --size=100g done done - 各データポイントでスループットとレイテンシーを記録してから、グラフ化します。
図31.4「パフォーマンスは、さまざまな読み取りと書き込みの組み合わせ混合で一貫している」 は、VDO が I/O 負荷に応答する方法の例を示しています。
図31.4 パフォーマンスは、さまざまな読み取りと書き込みの組み合わせ混合で一貫している

パフォーマンス (集約) とレイテンシー (集約) は、読み取りと書き込みが混在する範囲全体で比較的一貫性があり、より低い最大書き込みスループットからより高い最大書き込みスループットへと移ります。
この動作はストレージによって異なる場合がありますが、負荷が変化してもパフォーマンスが一貫していることや、特定の読み取りと書き込みの組み合わせを示すアプリケーションのパフォーマンス期待値を理解できることが重要となります。予期しない結果が見つかった場合、Red Hat セールスエンジニアは、変更が必要なのが VDO なのか、ストレージデバイス自体なのかを理解するためのサポートを提供することができます。
注記: 同様の応答の一貫性を示さないシステムは、多くの場合、設定が最適ではないことを意味します。この場合は、Red Hat セールスエンジニアにお問い合わせください。
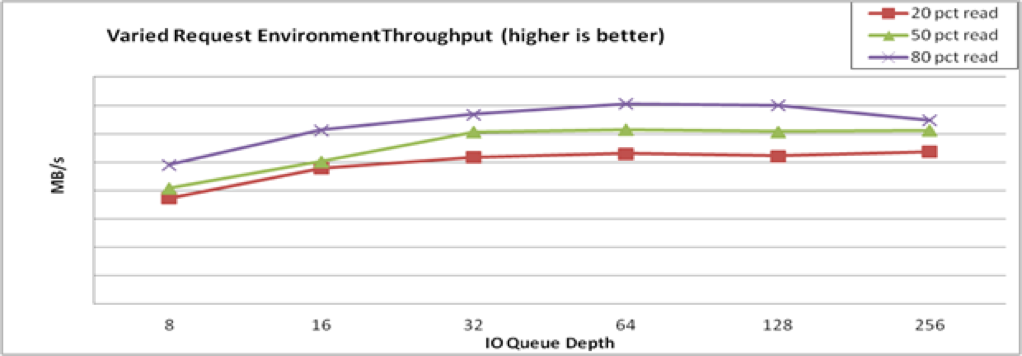
31.4.4. フェーズ 4: アプリケーション環境
リンクのコピーリンクがクリップボードにコピーされました!
この最終テストの目的は、実際のアプリケーション環境にデプロイする際に、VDO を使用したシステムがどのように動作するかを理解することです。可能であれば、実際のアプリケーションを使用し、これまでに学んだ知識を活用します。アプライアンスで許容されるキューの深さを制限することを検討し、可能であれば、VDO のパフォーマンスに最も有益なブロックサイズでリクエストを発行するようにアプリケーションを調整します。
リクエストサイズ、I/O 負荷、読み取り/書き込みパターンなどは、アプリケーションのユースケース (ファイラー、仮想デスクトップ、データベース) により異なるため、一般に予測は困難であり、アプリケーションも特定の操作またはマルチテナントのアクセスにより、I/O のタイプが異なることが多いです。
最終テストでは、混合環境における一般的な VDO パフォーマンスが示されます。想定される環境について、より具体的な詳細が分かっている場合は、その設定もテストします。
テスト入力要因の例 (読み取り/書き込みの組み合わせ):
# for readmix in 20 50 80; do
for iosize in 4 8 16 32 64 128 256 512 1024; do
fio --rw=rw --rwmixread=$readmix --bsrange=4k-256k --name=vdo \
--filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \
--norandommap --runtime=300 --direct=0 --iodepth=$iosize \
--scramble_buffers=1 --offset=0 --size=100g
done
done
各データポイントでスループットとレイテンシーを記録してから、グラフ化します (図31.5「混合環境パフォーマンス」)。
図31.5 混合環境パフォーマンス