1.2. Comprendre la pile de surveillance
La pile de surveillance d'OpenShift Container Platform est basée sur le projet open source Prometheus et son écosystème élargi. La pile de surveillance comprend les éléments suivants :
-
Default platform monitoring components. Un ensemble de composants de surveillance de la plateforme est installé par défaut dans le projet
openshift-monitoringlors de l'installation d'OpenShift Container Platform. Cela permet de surveiller les composants principaux d'OpenShift Container Platform, y compris les services Kubernetes. La pile de surveillance par défaut permet également de surveiller l'état des clusters à distance. Ces composants sont illustrés dans la section Installed by default dans le diagramme suivant. -
Components for monitoring user-defined projects. Après l'activation optionnelle du contrôle pour les projets définis par l'utilisateur, des composants de contrôle supplémentaires sont installés dans le projet
openshift-user-workload-monitoring. Cela permet de surveiller les projets définis par l'utilisateur. Ces composants sont illustrés dans la section User dans le diagramme suivant.
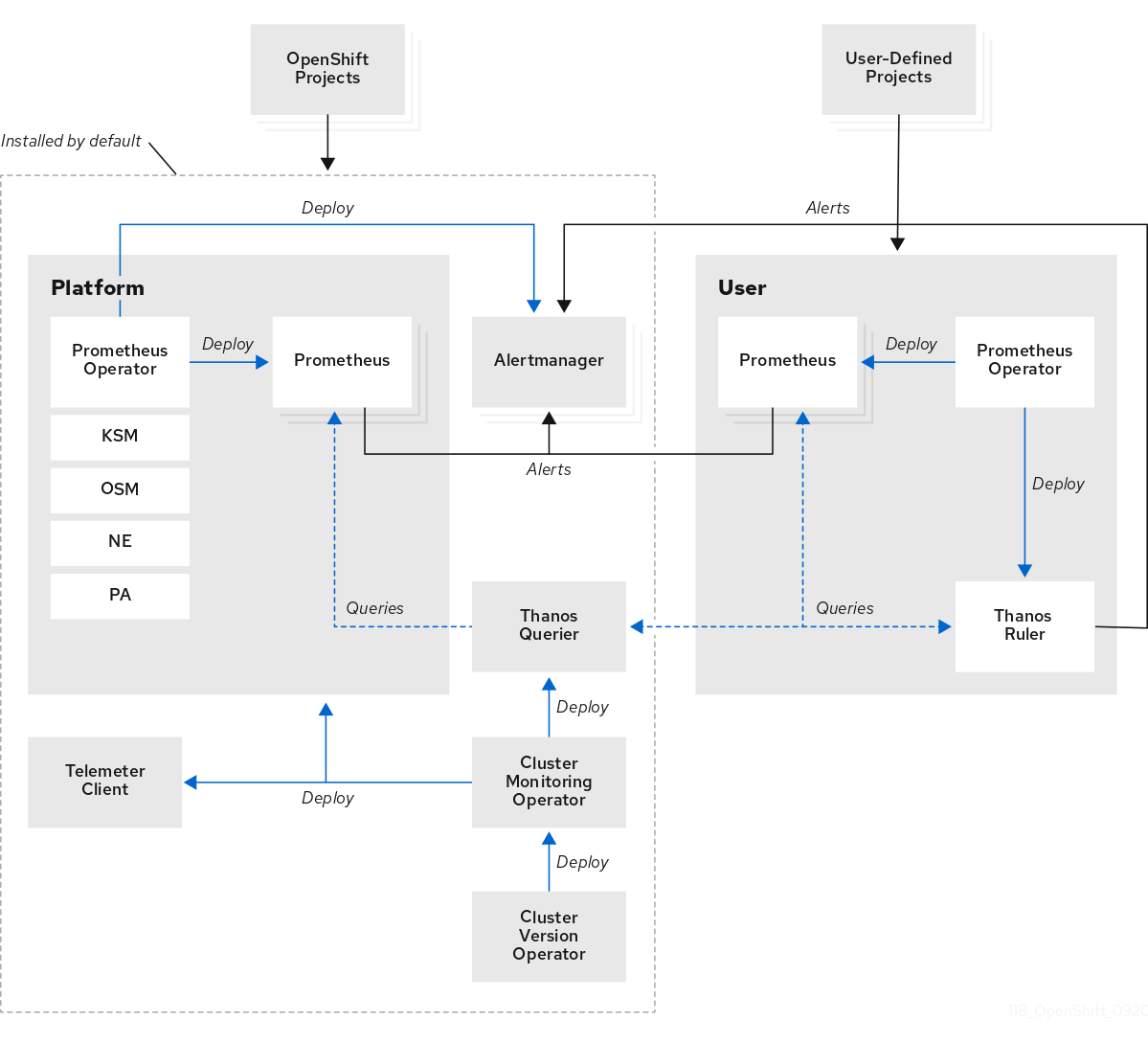
1.2.1. Composants de surveillance par défaut
Par défaut, la pile de surveillance d'OpenShift Container Platform 4.12 inclut ces composants :
| Composant | Description |
|---|---|
| Opérateur de suivi de groupe | L'opérateur de surveillance de cluster (CMO) est un composant central de la pile de surveillance. Il déploie, gère et met automatiquement à jour les instances de Prometheus et d'Alertmanager, l'interrogateur Thanos, le client Telemeter et les cibles de mesure. Le CMO est déployé par l'opérateur de version de cluster (CVO). |
| Opérateur Prométhée |
L'opérateur Prometheus (PO) du projet |
| Prometheus | Prometheus est le système de surveillance sur lequel repose la pile de surveillance d'OpenShift Container Platform. Prometheus est une base de données de séries temporelles et un moteur d'évaluation de règles pour les métriques. Prometheus envoie des alertes à Alertmanager pour traitement. |
| Adaptateur Prométhée |
L'adaptateur Prometheus (PA dans le diagramme précédent) traduit les requêtes de nœuds et de pods Kubernetes pour les utiliser dans Prometheus. Les métriques de ressources traduites comprennent les métriques d'utilisation du processeur et de la mémoire. L'adaptateur Prometheus expose l'API de métriques de ressources de cluster pour l'autoscaling horizontal de pods. L'adaptateur Prometheus est également utilisé par les commandes |
| Gestionnaire d'alerte | Le service Alertmanager gère les alertes reçues de Prometheus. Alertmanager est également responsable de l'envoi des alertes aux systèmes de notification externes. |
|
|
L'agent exportateur |
|
|
L'exportateur |
|
|
L'agent |
| Enquêteur Thanos | Thanos Querier agrège et éventuellement déduplique les métriques de base d'OpenShift Container Platform et les métriques pour les projets définis par l'utilisateur dans une interface unique et multi-tenant. |
| Client Télémètre | Telemeter Client envoie une sous-section des données des instances Prometheus de la plate-forme à Red Hat pour faciliter la surveillance à distance de la santé des grappes. |
Tous les composants de la pile de surveillance sont surveillés par la pile et sont automatiquement mis à jour lorsque OpenShift Container Platform est mis à jour.
Tous les composants de la pile de surveillance utilisent les paramètres de profil de sécurité TLS qui sont configurés de manière centralisée par un administrateur de cluster. Si vous configurez un composant de la pile de surveillance qui utilise des paramètres de sécurité TLS, le composant utilise les paramètres de profil de sécurité TLS qui existent déjà dans le champ tlsSecurityProfile de la ressource globale OpenShift Container Platform apiservers.config.openshift.io/cluster.
1.2.2. Objectifs de surveillance par défaut
Outre les composants de la pile elle-même, la pile de surveillance par défaut assure la surveillance :
- CoreDNS
- Elasticsearch (si la journalisation est installée)
- etcd
- Fluentd (si la journalisation est installée)
- HAProxy
- Registre des images
- Kubelets
- Serveur API Kubernetes
- Gestionnaire de contrôleur Kubernetes
- Ordonnanceur Kubernetes
- Serveur API OpenShift
- Gestionnaire de contrôleur OpenShift
- Gestionnaire du cycle de vie des opérateurs (OLM)
Chaque composant d'OpenShift Container Platform est responsable de sa configuration de surveillance. Pour les problèmes liés à la surveillance d'un composant d'OpenShift Container Platform, ouvrez une question Jira sur ce composant, et non sur le composant de surveillance général.
D'autres composants du framework OpenShift Container Platform peuvent également exposer des métriques. Pour plus de détails, consultez leur documentation respective.
1.2.3. Composants pour le suivi de projets définis par l'utilisateur
OpenShift Container Platform 4.12 inclut une amélioration optionnelle de la pile de surveillance qui vous permet de surveiller les services et les pods dans des projets définis par l'utilisateur. Cette fonctionnalité comprend les composants suivants :
| Composant | Description |
|---|---|
| Opérateur Prométhée |
L'opérateur Prometheus (PO) du projet |
| Prometheus | Prometheus est le système de surveillance qui permet de surveiller les projets définis par l'utilisateur. Prometheus envoie des alertes à Alertmanager pour traitement. |
| Règle de Thanos | Thanos Ruler est un moteur d'évaluation des règles pour Prometheus qui est déployé en tant que processus distinct. Dans OpenShift Container Platform 4.12, Thanos Ruler fournit une évaluation des règles et des alertes pour la surveillance des projets définis par l'utilisateur. |
| Gestionnaire d'alerte | Le service Alertmanager gère les alertes reçues de Prometheus et de Thanos Ruler. Alertmanager est également chargé d'envoyer des alertes définies par l'utilisateur à des systèmes de notification externes. Le déploiement de ce service est facultatif. |
Les composants du tableau précédent sont déployés après l'activation de la surveillance pour les projets définis par l'utilisateur.
Tous les composants de la pile de surveillance sont surveillés par la pile et sont automatiquement mis à jour lorsque OpenShift Container Platform est mis à jour.
1.2.4. Suivi des objectifs pour les projets définis par l'utilisateur
Lorsque la surveillance est activée pour les projets définis par l'utilisateur, vous pouvez surveiller :
- Les mesures sont fournies par des points d'extrémité de service dans des projets définis par l'utilisateur.
- Pods fonctionnant dans des projets définis par l'utilisateur.