7.8. Configuration du contrôleur d'entrée
7.8.1. Définition d'un certificat personnalisé par défaut
En tant qu'administrateur, vous pouvez configurer un contrôleur d'entrée pour qu'il utilise un certificat personnalisé en créant une ressource Secret et en modifiant la ressource personnalisée (CR) IngressController.
Conditions préalables
- Vous devez disposer d'une paire certificat/clé dans des fichiers codés PEM, où le certificat est signé par une autorité de certification de confiance ou par une autorité de certification de confiance privée que vous avez configurée dans une infrastructure de clés publiques (PKI) personnalisée.
Votre certificat répond aux exigences suivantes :
- Le certificat est valable pour le domaine d'entrée.
-
Le certificat utilise l'extension
subjectAltNamepour spécifier un domaine de remplacement, tel que*.apps.ocp4.example.com.
Vous devez avoir un CR
IngressController. Vous pouvez utiliser le CR par défaut :$ oc --namespace openshift-ingress-operator get ingresscontrollersExemple de sortie
NAME AGE default 10m
Si vous avez des certificats intermédiaires, ils doivent être inclus dans le fichier tls.crt du secret contenant un certificat par défaut personnalisé. L'ordre est important lors de la spécification d'un certificat ; indiquez votre (vos) certificat(s) intermédiaire(s) après le(s) certificat(s) de serveur.
Procédure
Ce qui suit suppose que le certificat personnalisé et la paire de clés se trouvent dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Remplacez les noms de chemin réels par tls.crt et tls.key. Vous pouvez également remplacer custom-certs-default par un autre nom lorsque vous créez la ressource Secret et que vous y faites référence dans le CR IngressController.
Cette action entraînera le redéploiement du contrôleur d'entrée, à l'aide d'une stratégie de déploiement continu.
Créez une ressource Secret contenant le certificat personnalisé dans l'espace de noms
openshift-ingressà l'aide des fichierstls.crtettls.key.$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.keyMettre à jour la CR du contrôleur d'ingestion pour qu'elle fasse référence au nouveau secret du certificat :
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'Vérifier que la mise à jour a été effective :
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddateoù :
<domain>- Spécifie le nom de domaine de base pour votre cluster.
Exemple de sortie
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GMAstuceVous pouvez également appliquer le code YAML suivant pour définir un certificat par défaut personnalisé :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-defaultLe nom du secret du certificat doit correspondre à la valeur utilisée pour mettre à jour le CR.
Une fois que le CR du contrôleur d'ingestion a été modifié, l'opérateur d'ingestion met à jour le déploiement du contrôleur d'ingestion afin d'utiliser le certificat personnalisé.
7.8.2. Suppression d'un certificat personnalisé par défaut
En tant qu'administrateur, vous pouvez supprimer un certificat personnalisé pour lequel vous avez configuré un contrôleur d'entrée.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc). - Vous avez précédemment configuré un certificat par défaut personnalisé pour le contrôleur d'entrée.
Procédure
Pour supprimer le certificat personnalisé et restaurer le certificat fourni avec OpenShift Container Platform, entrez la commande suivante :
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'Il peut y avoir un délai pendant que le cluster réconcilie la nouvelle configuration du certificat.
Vérification
Pour confirmer que le certificat original du cluster est restauré, entrez la commande suivante :
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddateoù :
<domain>- Spécifie le nom de domaine de base pour votre cluster.
Exemple de sortie
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
7.8.3. Mise à l'échelle automatique d'un contrôleur d'entrée
Mettre automatiquement à l'échelle un contrôleur d'entrée pour répondre dynamiquement aux exigences de performance ou de disponibilité du routage, telles que l'exigence d'augmenter le débit. La procédure suivante fournit un exemple de mise à l'échelle du contrôleur par défaut IngressController.
Le Custom Metrics Autoscaler est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès à un cluster OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. - L'opérateur Custom Metrics Autoscaler est installé.
Procédure
Créez un projet dans l'espace de noms
openshift-ingress-operatoren exécutant la commande suivante :$ oc project openshift-ingress-operatorActiver la surveillance d'OpenShift pour des projets définis par l'utilisateur en créant et en appliquant une carte de configuration :
Créez un nouvel objet
ConfigMap,cluster-monitoring-config.yaml:cluster-monitoring-config.yaml
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
- Lorsqu'il est défini sur
true, le paramètreenableUserWorkloadpermet la surveillance de projets définis par l'utilisateur dans un cluster.
Appliquez la carte de configuration en exécutant la commande suivante :
$ oc apply -f cluster-monitoring-config.yaml
Créez un compte de service pour vous authentifier auprès de Thanos en exécutant la commande suivante :
$ oc create serviceaccount thanos && oc describe serviceaccount thanosExemple de sortie
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-b4l9s Mountable secrets: thanos-dockercfg-b4l9s Tokens: thanos-token-c422q Events: <none>Définir un objet
TriggerAuthenticationdans l'espace de nomsopenshift-ingress-operatoren utilisant le jeton du compte de service.Définissez la variable
secretqui contient le secret en exécutant la commande suivante :$ secret=$(oc get secret | grep thanos-token | head -n 1 | awk '{ print $1 }')Créez l'objet
TriggerAuthenticationet transmettez la valeur de la variablesecretau paramètreTOKEN:$ oc process TOKEN="$secret" -f - <<EOF | oc apply -f - apiVersion: template.openshift.io/v1 kind: Template parameters: - name: TOKEN objects: - apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus spec: secretTargetRef: - parameter: bearerToken name: \${TOKEN} key: token - parameter: ca name: \${TOKEN} key: ca.crt EOF
Créer et appliquer un rôle pour la lecture des métriques de Thanos :
Créez un nouveau rôle,
thanos-metrics-reader.yaml, qui lit les métriques des pods et des nœuds :thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - getAppliquez le nouveau rôle en exécutant la commande suivante :
$ oc apply -f thanos-metrics-reader.yaml
Ajoutez le nouveau rôle au compte de service en entrant les commandes suivantes :
$ oc adm policy add-role-to-user thanos-metrics-reader -z thanos --role=namespace=openshift-ingress-operator$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanosNoteL'argument
add-cluster-role-to-usern'est requis que si vous utilisez des requêtes inter-espaces de noms. L'étape suivante utilise une requête de l'espace de nomskube-metricsqui nécessite cet argument.Créez un nouveau fichier YAML
ScaledObject,ingress-autoscaler.yaml, qui cible le déploiement du contrôleur d'ingestion par défaut :Exemple
ScaledObjectdéfinitionapiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler spec: scaleTargetRef:1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 202 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://<example-cluster>:90913 namespace: openshift-ingress-operator4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})'5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus- 1
- La ressource personnalisée que vous ciblez. Dans ce cas, il s'agit du contrôleur Ingress.
- 2
- Facultatif : Le nombre maximal de répliques. Si vous omettez ce champ, le maximum par défaut est fixé à 100 répliques.
- 3
- L'adresse et le port du cluster.
- 4
- L'espace de noms de l'opérateur d'entrée.
- 5
- Cette expression correspond au nombre de nœuds de travail présents dans la grappe déployée.
ImportantSi vous utilisez des requêtes inter-espace, vous devez cibler le port 9091 et non le port 9092 dans le champ
serverAddress. Vous devez également disposer de privilèges élevés pour lire les métriques à partir de ce port.Appliquez la définition de ressource personnalisée en exécutant la commande suivante :
$ oc apply -f ingress-autoscaler.yaml
Vérification
Vérifiez que le contrôleur d'entrée par défaut est mis à l'échelle pour correspondre à la valeur renvoyée par la requête
kube-state-metricsen exécutant les commandes suivantes :Utilisez la commande
greppour rechercher des répliques dans le fichier YAML du contrôleur d'entrée :$ oc get ingresscontroller/default -o yaml | grep replicas:Exemple de sortie
replicas: 3Obtenir les pods dans le projet
openshift-ingress:$ oc get pods -n openshift-ingressExemple de sortie
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
7.8.4. Mise à l'échelle d'un contrôleur d'entrée
Mettre à l'échelle manuellement un contrôleur d'entrée pour répondre aux exigences de performance de routage ou de disponibilité telles que l'exigence d'augmenter le débit. Les commandes oc sont utilisées pour mettre à l'échelle la ressource IngressController. La procédure suivante fournit un exemple de mise à l'échelle de la ressource par défaut IngressController.
La mise à l'échelle n'est pas une action immédiate, car il faut du temps pour créer le nombre souhaité de répliques.
Procédure
Affichez le nombre actuel de répliques disponibles pour le site par défaut
IngressController:$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
2Adaptez la version par défaut
IngressControllerau nombre de répliques souhaité à l'aide de la commandeoc patch. L'exemple suivant met à l'échelle le serveur par défautIngressControlleravec 3 réplicas :$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=mergeExemple de sortie
ingresscontroller.operator.openshift.io/default patchedVérifiez que la valeur par défaut de
IngressControllerest adaptée au nombre de répliques que vous avez spécifié :$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
3AstuceVous pouvez également appliquer le fichier YAML suivant pour adapter un contrôleur d'ingestion à trois répliques :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 31 - 1
- Si vous avez besoin d'un nombre différent de répliques, modifiez la valeur de
replicas.
7.8.5. Configuration de la journalisation des accès d'entrée
Vous pouvez configurer le contrôleur d'entrée pour activer les journaux d'accès. Si vous avez des clusters qui ne reçoivent pas beaucoup de trafic, vous pouvez enregistrer les logs dans un sidecar. Si vous avez des clusters à fort trafic, pour éviter de dépasser la capacité de la pile de journalisation ou pour intégrer une infrastructure de journalisation en dehors d'OpenShift Container Platform, vous pouvez transmettre les journaux à un point d'extrémité syslog personnalisé. Vous pouvez également spécifier le format des journaux d'accès.
La journalisation des conteneurs est utile pour activer les journaux d'accès sur les clusters à faible trafic lorsqu'il n'y a pas d'infrastructure de journalisation Syslog existante, ou pour une utilisation à court terme lors du diagnostic de problèmes avec le contrôleur d'entrée.
Syslog est nécessaire pour les clusters à fort trafic où les logs d'accès pourraient dépasser la capacité de la pile OpenShift Logging, ou pour les environnements où toute solution de logging doit s'intégrer à une infrastructure de logging Syslog existante. Les cas d'utilisation de Syslog peuvent se chevaucher.
Conditions préalables
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Configurer l'enregistrement des accès entrants à un sidecar.
Pour configurer la journalisation des accès entrants, vous devez spécifier une destination à l'aide de
spec.logging.access.destination. Pour spécifier la journalisation vers un conteneur sidecar, vous devez spécifierContainerspec.logging.access.destination.type. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre vers une destinationContainer:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: ContainerLorsque vous configurez le contrôleur d'entrée pour qu'il se connecte à un sidecar, l'opérateur crée un conteneur nommé
logsdans le pod du contrôleur d'entrée :$ oc -n openshift-ingress logs deployment.apps/router-default -c logsExemple de sortie
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
Configurer la journalisation de l'accès à l'entrée vers un point de terminaison Syslog.
Pour configurer la journalisation des accès d'entrée, vous devez spécifier une destination à l'aide de
spec.logging.access.destination. Pour spécifier la journalisation vers un point de terminaison Syslog, vous devez spécifierSyslogpourspec.logging.access.destination.type. Si le type de destination estSyslog, vous devez également spécifier un point d'extrémité de destination à l'aide despec.logging.access.destination.syslog.endpointet vous pouvez spécifier une installation à l'aide despec.logging.access.destination.syslog.facility. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre vers une destinationSyslog:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514NoteLe port de destination de
syslogdoit être UDP.
Configurer l'enregistrement des accès d'entrée avec un format d'enregistrement spécifique.
Vous pouvez spécifier
spec.logging.access.httpLogFormatpour personnaliser le format du journal. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre sur un point d'extrémitésyslogavec l'adresse IP 1.2.3.4 et le port 10514 :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514 httpLogFormat: '%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV'
Désactiver la journalisation des accès entrants.
Pour désactiver la journalisation des accès entrants, laissez
spec.loggingouspec.logging.accessvide :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: null
7.8.6. Réglage du nombre de fils du contrôleur d'ingérence
Un administrateur de cluster peut définir le nombre de threads afin d'augmenter le nombre de connexions entrantes qu'un cluster peut gérer. Vous pouvez corriger un contrôleur d'entrée existant pour augmenter le nombre de threads.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée.
Procédure
Mettre à jour le contrôleur d'entrée pour augmenter le nombre de threads :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'NoteSi vous disposez d'un nœud capable d'exécuter de grandes quantités de ressources, vous pouvez configurer
spec.nodePlacement.nodeSelectoravec des étiquettes correspondant à la capacité du nœud prévu et configurerspec.tuningOptions.threadCountavec une valeur élevée appropriée.
7.8.7. Configuration d'un contrôleur d'entrée pour utiliser un équilibreur de charge interne
Lors de la création d'un contrôleur d'ingestion sur des plateformes en nuage, le contrôleur d'ingestion est publié par un équilibreur de charge en nuage public par défaut. En tant qu'administrateur, vous pouvez créer un contrôleur d'entrée qui utilise un équilibreur de charge interne au nuage.
Si votre fournisseur de cloud est Microsoft Azure, vous devez avoir au moins un équilibreur de charge public qui pointe vers vos nœuds. Si ce n'est pas le cas, tous vos nœuds perdront la connectivité de sortie vers l'internet.
Si vous souhaitez modifier le paramètre scope pour une ressource IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Figure 7.1. Diagramme de LoadBalancer
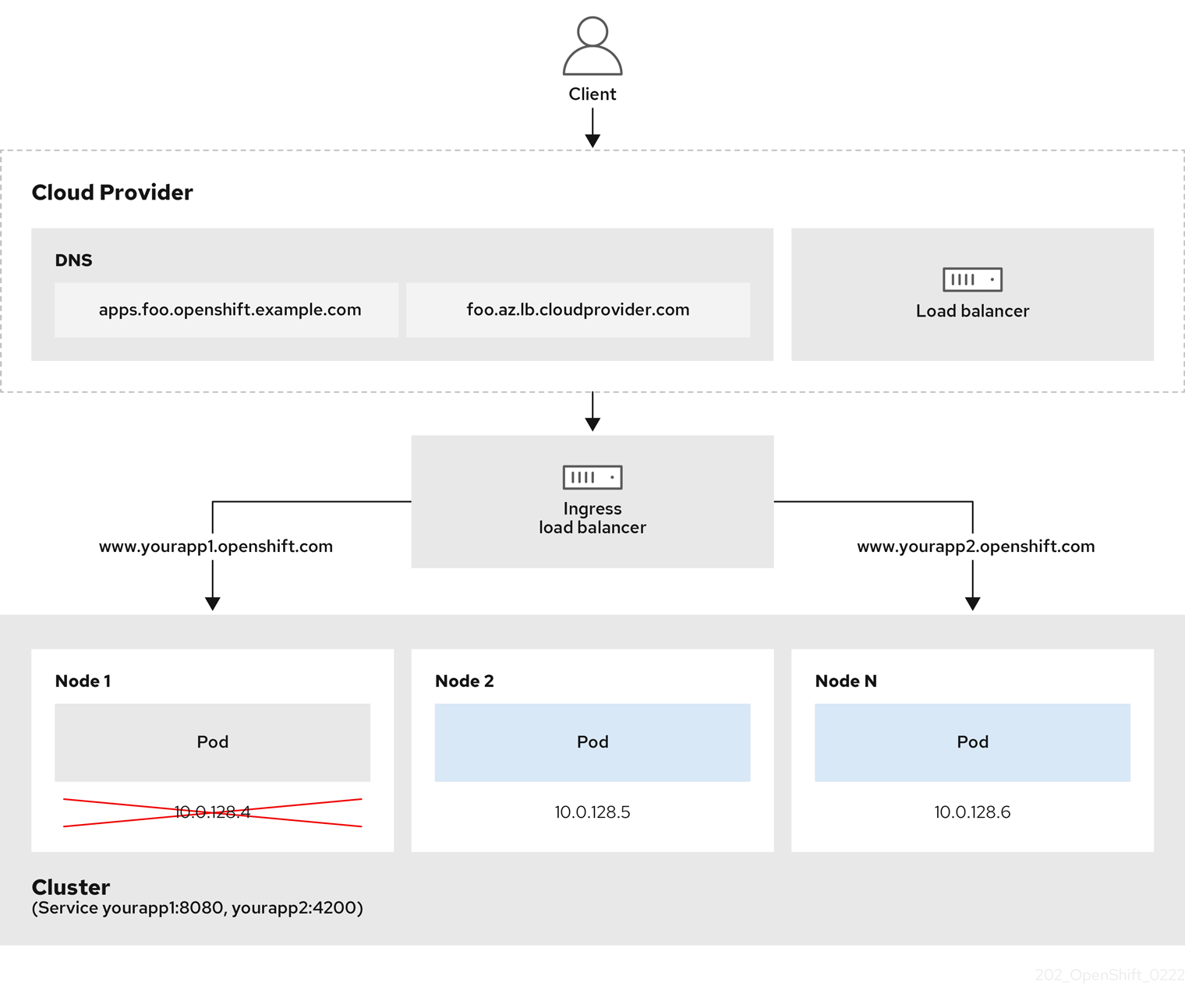
Le graphique précédent illustre les concepts suivants relatifs à la stratégie de publication des points d'extrémité de OpenShift Container Platform Ingress LoadBalancerService :
- Vous pouvez équilibrer la charge en externe, en utilisant l'équilibreur de charge du fournisseur de cloud, ou en interne, en utilisant l'équilibreur de charge du contrôleur d'ingestion OpenShift.
- Vous pouvez utiliser l'adresse IP unique de l'équilibreur de charge et des ports plus familiers, tels que 8080 et 4200, comme le montre le cluster illustré dans le graphique.
- Le trafic provenant de l'équilibreur de charge externe est dirigé vers les pods et géré par l'équilibreur de charge, comme le montre l'instance d'un nœud en panne. Voir la documentation de Kubernetes Services pour plus de détails sur la mise en œuvre.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez une ressource personnalisée (CR)
IngressControllerdans un fichier nommé<name>-ingress-controller.yaml, comme dans l'exemple suivant :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal3 Créez le contrôleur d'entrée défini à l'étape précédente en exécutant la commande suivante :
oc create -f <name>-ingress-controller.yaml1 - 1
- Remplacez
<name>par le nom de l'objetIngressController.
Facultatif : Confirmez que le contrôleur d'entrée a été créé en exécutant la commande suivante :
$ oc --all-namespaces=true get ingresscontrollers
7.8.8. Configuration de l'accès global pour un contrôleur d'entrée sur GCP
Un contrôleur d'entrée créé sur GCP avec un équilibreur de charge interne génère une adresse IP interne pour le service. Un administrateur de cluster peut spécifier l'option d'accès global, qui permet aux clients de n'importe quelle région du même réseau VPC et de la même région de calcul que l'équilibreur de charge, d'atteindre les charges de travail exécutées sur votre cluster.
Pour plus d'informations, voir la documentation GCP pour l'accès global.
Conditions préalables
- Vous avez déployé un cluster OpenShift Container Platform sur une infrastructure GCP.
- Vous avez configuré un contrôleur d'entrée pour utiliser un équilibreur de charge interne.
-
You installed the OpenShift CLI (
oc).
Procédure
Configurez la ressource Ingress Controller pour autoriser l'accès global.
NoteVous pouvez également créer un contrôleur d'entrée et spécifier l'option d'accès global.
Configurer la ressource Ingress Controller :
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultModifiez le fichier YAML :
Sample
clientAccessconfiguration toGlobalspec: endpointPublishingStrategy: loadBalancer: providerParameters: gcp: clientAccess: Global1 type: GCP scope: Internal type: LoadBalancerService- 1
- Set
gcp.clientAccesstoGlobal.
- Enregistrez le fichier pour appliquer les modifications.
Exécutez la commande suivante pour vérifier que le service autorise l'accès global :
$ oc -n openshift-ingress edit svc/router-default -o yamlLa sortie montre que l'accès global est activé pour GCP avec l'annotation
networking.gke.io/internal-load-balancer-allow-global-access.
7.8.9. Définition de l'intervalle de contrôle de santé du contrôleur d'entrée
L'administrateur d'un cluster peut définir l'intervalle de contrôle de santé afin de déterminer la durée d'attente du routeur entre deux contrôles de santé consécutifs. Cette valeur est appliquée globalement par défaut à toutes les routes. La valeur par défaut est de 5 secondes.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée.
Procédure
Mettre à jour le contrôleur d'entrée afin de modifier l'intervalle entre les contrôles de santé du back-end :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'NotePour remplacer le site
healthCheckIntervalpour un seul itinéraire, utilisez l'annotation d'itinérairerouter.openshift.io/haproxy.health.check.interval
7.8.10. Configurer le contrôleur d'entrée par défaut de votre cluster pour qu'il soit interne
Vous pouvez configurer le contrôleur d'entrée default de votre cluster pour qu'il soit interne en le supprimant et en le recréant.
Si votre fournisseur de cloud est Microsoft Azure, vous devez avoir au moins un équilibreur de charge public qui pointe vers vos nœuds. Si ce n'est pas le cas, tous vos nœuds perdront la connectivité de sortie vers l'internet.
Si vous souhaitez modifier le paramètre scope pour une ressource IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Configurez le contrôleur d'entrée
defaultde votre cluster pour qu'il soit interne en le supprimant et en le recréant.$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
7.8.11. Configuration de la politique d'admission des routes
Les administrateurs et les développeurs d'applications peuvent exécuter des applications dans plusieurs espaces de noms avec le même nom de domaine. Cela s'adresse aux organisations où plusieurs équipes développent des microservices qui sont exposés sur le même nom d'hôte.
L'autorisation des revendications à travers les espaces de noms ne devrait être activée que pour les clusters avec confiance entre les espaces de noms, sinon un utilisateur malveillant pourrait prendre le contrôle d'un nom d'hôte. Pour cette raison, la politique d'admission par défaut interdit les demandes de noms d'hôtes entre espaces de noms.
Conditions préalables
- Privilèges d'administrateur de cluster.
Procédure
Modifiez le champ
.spec.routeAdmissionde la variable de ressourceingresscontrollerà l'aide de la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeExemple de configuration du contrôleur d'entrée
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...AstuceVous pouvez également appliquer le langage YAML suivant pour configurer la politique d'admission des routes :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
7.8.12. Utilisation d'itinéraires génériques
Le contrôleur d'entrée HAProxy prend en charge les itinéraires génériques. L'opérateur d'entrée utilise wildcardPolicy pour configurer la variable d'environnement ROUTER_ALLOW_WILDCARD_ROUTES du contrôleur d'entrée.
Le comportement par défaut du contrôleur d'entrée est d'admettre les itinéraires avec une politique de caractères génériques de None, ce qui est rétrocompatible avec les ressources IngressController existantes.
Procédure
Configurer la politique des caractères génériques.
Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit IngressControllerSous
spec, définissez le champwildcardPolicycommeWildcardsDisallowedouWildcardsAllowed:spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
7.8.13. Utilisation des en-têtes X-Forwarded
Vous configurez le contrôleur d'entrée HAProxy pour qu'il spécifie une stratégie de traitement des en-têtes HTTP, y compris Forwarded et X-Forwarded-For. L'opérateur d'entrée utilise le champ HTTPHeaders pour configurer la variable d'environnement ROUTER_SET_FORWARDED_HEADERS du contrôleur d'entrée.
Procédure
Configurez le champ
HTTPHeaderspour le contrôleur d'entrée.Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit IngressControllerSous
spec, définissez le champ de politiqueHTTPHeaderssurAppend,Replace,IfNoneouNever:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
Exemples de cas d'utilisation
As a cluster administrator, you can:
Configurez un proxy externe qui injecte l'en-tête
X-Forwarded-Fordans chaque requête avant de la transmettre à un contrôleur d'entrée.Pour configurer le contrôleur d'entrée afin qu'il transmette l'en-tête sans modification, vous devez spécifier la politique
never. Le contrôleur d'entrée ne définit alors jamais les en-têtes et les applications ne reçoivent que les en-têtes fournis par le proxy externe.Configurez le contrôleur d'entrée pour qu'il transmette sans modification l'en-tête
X-Forwarded-Forque votre proxy externe définit sur les requêtes de clusters externes.Pour configurer le contrôleur d'entrée afin qu'il définisse l'en-tête
X-Forwarded-Forsur les requêtes internes du cluster, qui ne passent pas par le proxy externe, spécifiez la stratégieif-none. Si l'en-tête d'une requête HTTP est déjà défini via le proxy externe, le contrôleur d'entrée le conserve. Si l'en-tête est absent parce que la requête n'est pas passée par le proxy, le contrôleur d'entrée ajoute l'en-tête.
As an application developer, you can:
Configurer un proxy externe spécifique à l'application qui injecte l'en-tête
X-Forwarded-For.Pour configurer un contrôleur d'entrée afin qu'il transmette l'en-tête sans modification pour la route d'une application, sans affecter la politique pour les autres routes, ajoutez une annotation
haproxy.router.openshift.io/set-forwarded-headers: if-noneouhaproxy.router.openshift.io/set-forwarded-headers: neversur la route de l'application.NoteVous pouvez définir l'annotation
haproxy.router.openshift.io/set-forwarded-headerspour chaque itinéraire, indépendamment de la valeur définie globalement pour le contrôleur d'entrée.
7.8.14. Activation de la connectivité HTTP/2 Ingress
Vous pouvez activer la connectivité HTTP/2 transparente de bout en bout dans HAProxy. Cela permet aux propriétaires d'applications d'utiliser les fonctionnalités du protocole HTTP/2, notamment la connexion unique, la compression des en-têtes, les flux binaires, etc.
Vous pouvez activer la connectivité HTTP/2 pour un contrôleur d'entrée individuel ou pour l'ensemble du cluster.
Pour permettre l'utilisation de HTTP/2 pour la connexion du client à HAProxy, un itinéraire doit spécifier un certificat personnalisé. Une route qui utilise le certificat par défaut ne peut pas utiliser HTTP/2. Cette restriction est nécessaire pour éviter les problèmes liés à la coalescence des connexions, lorsque le client réutilise une connexion pour différents itinéraires qui utilisent le même certificat.
La connexion entre HAProxy et le module d'application ne peut utiliser HTTP/2 que pour le recryptage des itinéraires et non pour les itinéraires terminés ou non sécurisés. Cette restriction est due au fait que HAProxy utilise la négociation de protocole au niveau de l'application (ALPN), qui est une extension TLS, pour négocier l'utilisation de HTTP/2 avec le back-end. Il en résulte que le protocole HTTP/2 de bout en bout est possible avec passthrough et re-encrypt, mais pas avec des itinéraires non sécurisés ou terminés par un bord.
L'utilisation de WebSockets avec une route de recryptage et avec HTTP/2 activé sur un contrôleur d'entrée nécessite la prise en charge de WebSocket sur HTTP/2. WebSockets sur HTTP/2 est une fonctionnalité de HAProxy 2.4, qui n'est pas supportée par OpenShift Container Platform pour le moment.
Pour les routes non passantes, le contrôleur d'entrée négocie sa connexion à l'application indépendamment de la connexion du client. Cela signifie qu'un client peut se connecter au contrôleur d'entrée et négocier HTTP/1.1, et que le contrôleur d'entrée peut ensuite se connecter à l'application, négocier HTTP/2, et transmettre la demande de la connexion HTTP/1.1 du client en utilisant la connexion HTTP/2 à l'application. Cela pose un problème si le client tente par la suite de faire passer sa connexion de HTTP/1.1 au protocole WebSocket, car le contrôleur d'entrée ne peut pas transmettre WebSocket à HTTP/2 et ne peut pas faire passer sa connexion HTTP/2 à WebSocket. Par conséquent, si vous avez une application destinée à accepter des connexions WebSocket, elle ne doit pas autoriser la négociation du protocole HTTP/2, sinon les clients ne parviendront pas à passer au protocole WebSocket.
Procédure
Activer HTTP/2 sur un seul contrôleur d'entrée.
Pour activer HTTP/2 sur un contrôleur d'entrée, entrez la commande
oc annotate:oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=trueRemplacer
<ingresscontroller_name>par le nom du contrôleur d'entrée à annoter.
Activer HTTP/2 sur l'ensemble du cluster.
Pour activer HTTP/2 pour l'ensemble du cluster, entrez la commande
oc annotate:$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=trueAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'annotation :
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster annotations: ingress.operator.openshift.io/default-enable-http2: "true"
7.8.15. Configuration du protocole PROXY pour un contrôleur d'entrée
Un administrateur de cluster peut configurer le protocole PROXY lorsqu'un contrôleur d'entrée utilise les types de stratégie de publication des points d'extrémité HostNetwork ou NodePortService. Le protocole PROXY permet à l'équilibreur de charge de conserver les adresses client d'origine pour les connexions que le contrôleur d'entrée reçoit. Les adresses client d'origine sont utiles pour la journalisation, le filtrage et l'injection d'en-têtes HTTP. Dans la configuration par défaut, les connexions que le contrôleur d'entrée reçoit ne contiennent que l'adresse source associée à l'équilibreur de charge.
Cette fonctionnalité n'est pas prise en charge dans les déploiements en nuage. Cette restriction s'explique par le fait que lorsque OpenShift Container Platform fonctionne sur une plateforme cloud et qu'un IngressController spécifie qu'un service d'équilibrage de charge doit être utilisé, l'opérateur d'ingestion configure le service d'équilibrage de charge et active le protocole PROXY en fonction de l'exigence de la plateforme en matière de préservation des adresses source.
Vous devez configurer OpenShift Container Platform et l'équilibreur de charge externe pour qu'ils utilisent le protocole PROXY ou TCP.
Le protocole PROXY n'est pas pris en charge par le contrôleur d'entrée par défaut avec les clusters fournis par l'installateur sur des plates-formes non cloud qui utilisent un VIP d'entrée Keepalived.
Conditions préalables
- Vous avez créé un contrôleur d'entrée.
Procédure
Modifiez la ressource Ingress Controller :
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultDéfinir la configuration PROXY :
Si votre contrôleur d'entrée utilise le type de stratégie de publication des points d'extrémité hostNetwork, définissez le sous-champ
spec.endpointPublishingStrategy.hostNetwork.protocolsurPROXY:Exemple de configuration de
hostNetworkpourPROXYspec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetworkSi votre contrôleur d'entrée utilise le type de stratégie de publication des points d'extrémité NodePortService, attribuez la valeur
PROXYau sous-champspec.endpointPublishingStrategy.nodePort.protocol:Exemple de configuration de
nodePortpourPROXYspec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService
7.8.16. Spécification d'un domaine de cluster alternatif à l'aide de l'option appsDomain
En tant qu'administrateur de cluster, vous pouvez spécifier une alternative au domaine de cluster par défaut pour les routes créées par l'utilisateur en configurant le champ appsDomain. Le champ appsDomain est un domaine optionnel pour OpenShift Container Platform à utiliser à la place du domaine par défaut, qui est spécifié dans le champ domain. Si vous spécifiez un domaine alternatif, il remplace le domaine de cluster par défaut afin de déterminer l'hôte par défaut pour une nouvelle route.
Par exemple, vous pouvez utiliser le domaine DNS de votre entreprise comme domaine par défaut pour les routes et les entrées des applications fonctionnant sur votre cluster.
Conditions préalables
- You deployed an OpenShift Container Platform cluster.
-
Vous avez installé l'interface de ligne de commande
oc.
Procédure
Configurez le champ
appsDomainen spécifiant un autre domaine par défaut pour les itinéraires créés par l'utilisateur.Modifiez la ressource ingress
cluster:$ oc edit ingresses.config/cluster -o yamlModifiez le fichier YAML :
Exemple de configuration de
appsDomainpourtest.example.comapiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com1 appsDomain: <test.example.com>2 - 1
- Spécifie le domaine par défaut. Vous ne pouvez pas modifier le domaine par défaut après l'installation.
- 2
- Facultatif : Domaine de l'infrastructure OpenShift Container Platform à utiliser pour les routes d'application. Au lieu du préfixe par défaut,
apps, vous pouvez utiliser un autre préfixe commetest.
Vérifiez qu'un itinéraire existant contient le nom de domaine spécifié dans le champ
appsDomainen exposant l'itinéraire et en vérifiant le changement de domaine de l'itinéraire :NoteAttendez que le site
openshift-apiserverfinisse de diffuser les mises à jour avant d'exposer l'itinéraire.Exposer l'itinéraire :
$ oc expose service hello-openshift route.route.openshift.io/hello-openshift exposedExemple de sortie :
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
7.8.17. Conversion des en-têtes HTTP
HAProxy 2.2 met par défaut les noms d'en-tête HTTP en minuscules, par exemple en remplaçant Host: xyz.com par host: xyz.com. Si les applications existantes sont sensibles à la mise en majuscules des noms d'en-tête HTTP, utilisez le champ API spec.httpHeaders.headerNameCaseAdjustments du contrôleur d'entrée pour trouver une solution permettant d'accommoder les applications existantes jusqu'à ce qu'elles soient corrigées.
Comme OpenShift Container Platform inclut HAProxy 2.2, assurez-vous d'ajouter la configuration nécessaire à l'aide de spec.httpHeaders.headerNameCaseAdjustments avant de procéder à la mise à niveau.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
En tant qu'administrateur de cluster, vous pouvez convertir le cas de l'en-tête HTTP en entrant la commande oc patch ou en définissant le champ HeaderNameCaseAdjustments dans le fichier YAML du contrôleur d'entrée.
Spécifiez un en-tête HTTP à mettre en majuscules en entrant la commande
oc patch.Entrez la commande
oc patchpour remplacer l'en-tête HTTPhostparHost:$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'Annoter l'itinéraire de la demande :
$ oc annotate routes/my-application haproxy.router.openshift.io/h1-adjust-case=trueLe contrôleur d'entrée ajuste ensuite l'en-tête de demande
hostcomme spécifié.
Spécifiez les ajustements à l'aide du champ
HeaderNameCaseAdjustmentsen configurant le fichier YAML du contrôleur d'entrée.L'exemple suivant de contrôleur d'entrée YAML ajuste l'en-tête
hostàHostpour les requêtes HTTP/1 vers des itinéraires correctement annotés :Exemple de contrôleur d'entrée YAML
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - HostL'exemple de route suivant permet d'ajuster les cas de figure des en-têtes de réponse HTTP à l'aide de l'annotation
haproxy.router.openshift.io/h1-adjust-case:Exemple de route YAML
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
- Fixer
haproxy.router.openshift.io/h1-adjust-caseà true (vrai).
7.8.18. Utilisation de la compression du routeur
Vous configurez le contrôleur d'entrée HAProxy pour spécifier globalement la compression du routeur pour des types MIME spécifiques. Vous pouvez utiliser la variable mimeTypes pour définir les formats des types MIME auxquels la compression est appliquée. Les types sont les suivants : application, image, message, multipart, texte, vidéo ou un type personnalisé précédé de "X-". Pour voir la notation complète des types et sous-types MIME, voir RFC1341.
La mémoire allouée à la compression peut affecter le nombre maximal de connexions. En outre, la compression de tampons volumineux peut entraîner une certaine latence, comme c'est le cas pour les expressions rationnelles lourdes ou les longues listes d'expressions rationnelles.
Tous les types MIME ne bénéficient pas de la compression, mais HAProxy utilise tout de même des ressources pour essayer de les compresser si on le lui demande. En général, les formats de texte, tels que html, css et js, bénéficient de la compression, mais les formats déjà compressés, tels que les images, l'audio et la vidéo, bénéficient peu en échange du temps et des ressources consacrés à la compression.
Procédure
Configurez le champ
httpCompressionpour le contrôleur d'entrée.Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultSous
spec, définissez le champ de politiquehttpCompressionsurmimeTypeset indiquez une liste de types MIME pour lesquels la compression doit être appliquée :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
7.8.19. Personnalisation des pages de réponse au code d'erreur de HAProxy
En tant qu'administrateur de cluster, vous pouvez spécifier un code d'erreur personnalisé pour la page de réponse 503, 404 ou les deux pages d'erreur. Le routeur HAProxy sert une page d'erreur 503 lorsque le module d'application ne fonctionne pas ou une page d'erreur 404 lorsque l'URL demandée n'existe pas. Par exemple, si vous personnalisez la page de réponse au code d'erreur 503, la page est servie lorsque le module d'application n'est pas en cours d'exécution et la page de réponse HTTP au code d'erreur 404 par défaut est servie par le routeur HAProxy en cas d'itinéraire incorrect ou inexistant.
Les pages de réponse aux codes d'erreur personnalisés sont spécifiées dans une carte de configuration, puis patchées sur le contrôleur d'entrée. Les clés de la carte de configuration ont deux noms de fichier disponibles : error-page-503.http et error-page-404.http.
Les pages de réponse de code d'erreur HTTP personnalisées doivent respecter les directives de configuration de la page d'erreur HTTP de HAProxy. Voici un exemple de la page de réponse par défaut du code d'erreur http 503 du routeur HAProxy de OpenShift Container Platform. Vous pouvez utiliser le contenu par défaut comme modèle pour créer votre propre page personnalisée.
Par défaut, le routeur HAProxy ne sert qu'une page d'erreur 503 lorsque l'application n'est pas en cours d'exécution ou lorsque la route est incorrecte ou inexistante. Ce comportement par défaut est le même que le comportement sur OpenShift Container Platform 4.8 et antérieur. Si une carte de configuration pour la personnalisation d'une réponse de code d'erreur HTTP n'est pas fournie et que vous utilisez une page de réponse de code d'erreur HTTP personnalisée, le routeur sert une page de réponse de code d'erreur 404 ou 503 par défaut.
Si vous utilisez la page de code d'erreur 503 par défaut d'OpenShift Container Platform comme modèle pour vos personnalisations, les en-têtes du fichier nécessitent un éditeur qui peut utiliser les fins de ligne CRLF.
Procédure
Créez une carte de configuration nommée
my-custom-error-code-pagesdans l'espace de nomsopenshift-config:$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.httpImportantSi vous ne spécifiez pas le format correct pour la page de réponse du code d'erreur personnalisé, une panne du module de routeur se produit. Pour résoudre cette panne, vous devez supprimer ou corriger la carte de configuration et supprimer les router pods concernés afin qu'ils puissent être recréés avec les informations correctes.
Patch du contrôleur d'entrée pour référencer la carte de configuration
my-custom-error-code-pagespar son nom :$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeL'opérateur d'entrée copie la carte de configuration
my-custom-error-code-pagesde l'espace de nomsopenshift-configvers l'espace de nomsopenshift-ingress. L'opérateur nomme la carte de configuration selon le modèle<your_ingresscontroller_name>-errorpages, dans l'espace de nomsopenshift-ingress.Afficher la copie :
$ oc get cm default-errorpages -n openshift-ingressExemple de sortie
NAME DATA AGE default-errorpages 2 25s1 - 1
- L'exemple de nom de carte de configuration est
default-errorpagescar la ressource personnalisée (CR) du contrôleur d'entréedefaulta été corrigée.
Confirmez que la carte de configuration contenant la page de réponse d'erreur personnalisée est montée sur le volume du routeur, la clé de la carte de configuration étant le nom du fichier contenant la réponse du code d'erreur HTTP personnalisé :
Pour la réponse au code d'erreur personnalisé HTTP 503 :
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.httpPour la réponse au code d'erreur HTTP personnalisé 404 :
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
Vérification
Vérifiez votre code d'erreur personnalisé dans la réponse HTTP :
Créez un projet et une application de test :
$ oc new-project test-ingress$ oc new-app django-psql-examplePour la réponse au code d'erreur http personnalisé 503 :
- Arrêter tous les pods pour l'application.
Exécutez la commande curl suivante ou visitez le nom d'hôte de la route dans le navigateur :
$ curl -vk <route_hostname>
Pour la réponse au code d'erreur http personnalisé 404 :
- Visiter un itinéraire inexistant ou un itinéraire incorrect.
Exécutez la commande curl suivante ou visitez le nom d'hôte de la route dans le navigateur :
$ curl -vk <route_hostname>
Vérifier que l'attribut
errorfilefigure bien dans le fichierhaproxy.config:oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
7.8.20. Définition du nombre maximum de connexions du contrôleur d'entrée
Un administrateur de cluster peut définir le nombre maximum de connexions simultanées pour les déploiements de routeurs OpenShift. Vous pouvez corriger un contrôleur d'entrée existant pour augmenter le nombre maximum de connexions.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée
Procédure
Mettez à jour le contrôleur d'entrée afin de modifier le nombre maximal de connexions pour HAProxy :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'AvertissementSi la valeur de
spec.tuningOptions.maxConnectionsest supérieure à la limite actuelle du système d'exploitation, le processus HAProxy ne démarrera pas. Voir le tableau de la section "Paramètres de configuration du contrôleur d'entrée" pour plus d'informations sur ce paramètre.