8.2. Mesures pour les développeurs
8.2.1. Vue d'ensemble des métriques pour les développeurs Serverless
Les métriques permettent aux développeurs de surveiller les performances des services Knative. Vous pouvez utiliser la pile de surveillance OpenShift Container Platform pour enregistrer et visualiser les contrôles de santé et les métriques de vos services Knative.
Vous pouvez visualiser différentes métriques pour OpenShift Serverless en naviguant vers Dashboards dans la console web de OpenShift Container Platform Developer perspective.
Si Service Mesh est activé avec mTLS, les métriques pour Knative Serving sont désactivées par défaut car Service Mesh empêche Prometheus de récupérer les métriques.
Pour plus d'informations sur la résolution de ce problème, voir Activation des métriques Knative Serving lors de l'utilisation de Service Mesh avec mTLS.
Le scraping des métriques n'affecte pas l'autoscaling d'un service Knative, car les requêtes de scraping ne passent pas par l'activateur. Par conséquent, aucun scraping n'a lieu si aucun pod n'est en cours d'exécution.
8.2.2. Métriques de service Knative exposées par défaut
| Nom, unité et type de métrique | Description | Étiquettes métriques |
|---|---|---|
|
Unité métrique : sans dimension Type métrique : jauge | Nombre de requêtes par seconde qui atteignent le proxy de file d'attente.
Formule :
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
Unité métrique : sans dimension Type métrique : jauge | Nombre de requêtes proxy par seconde.
Formule :
| |
|
Unité métrique : sans dimension Type métrique : jauge | Nombre de demandes actuellement traitées par ce module.
La concurrence moyenne est calculée comme suit du côté de la mise en réseau
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
Unité métrique : sans dimension Type métrique : jauge | Nombre de requêtes par procuration actuellement traitées par ce module :
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
Unité métrique : secondes Type métrique : jauge | Le nombre de secondes depuis lesquelles le processus est en cours. | destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
| Nom, unité et type de métrique | Description | Étiquettes métriques |
|---|---|---|
|
Unité métrique : sans dimension Type métrique : compteur |
Le nombre de demandes qui sont acheminées vers | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
Unité métrique : millisecondes Type de mesure : histogramme | Le temps de réponse en millisecondes. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
Unité métrique : sans dimension Type métrique : compteur |
Le nombre de demandes qui sont acheminées vers | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
Unité métrique : millisecondes Type de mesure : histogramme | Le temps de réponse en millisecondes. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
Unité métrique : sans dimension Type métrique : jauge |
Le nombre actuel d'éléments dans la file d'attente de service et d'attente, ou non signalé si la concurrence est illimitée. | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
8.2.3. Service Knative avec métriques d'application personnalisées
Vous pouvez étendre l'ensemble des métriques exportées par un service Knative. L'implémentation exacte dépend de votre application et du langage utilisé.
La liste suivante met en œuvre un exemple d'application Go qui exporte la métrique personnalisée du nombre d'événements traités.
package main
import (
"fmt"
"log"
"net/http"
"os"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
opsProcessed = promauto.NewCounter(prometheus.CounterOpts{
Name: "myapp_processed_ops_total",
Help: "The total number of processed events",
})
)
func handler(w http.ResponseWriter, r *http.Request) {
log.Print("helloworld: received a request")
target := os.Getenv("TARGET")
if target == "" {
target = "World"
}
fmt.Fprintf(w, "Hello %s!\n", target)
opsProcessed.Inc()
}
func main() {
log.Print("helloworld: starting server...")
port := os.Getenv("PORT")
if port == "" {
port = "8080"
}
http.HandleFunc("/", handler)
// Separate server for metrics requests
go func() {
mux := http.NewServeMux()
server := &http.Server{
Addr: fmt.Sprintf(":%s", "9095"),
Handler: mux,
}
mux.Handle("/metrics", promhttp.Handler())
log.Printf("prometheus: listening on port %s", 9095)
log.Fatal(server.ListenAndServe())
}()
// Use same port as normal requests for metrics
//http.Handle("/metrics", promhttp.Handler())
log.Printf("helloworld: listening on port %s", port)
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%s", port), nil))
}- 1
- Y compris les paquets Prometheus.
- 2
- Définition de la métrique
opsProcessed. - 3
- Incrémentation de la métrique
opsProcessed. - 4
- Configurer l'utilisation d'un serveur séparé pour les demandes de métriques.
- 5
- Configuration pour utiliser le même port que les demandes normales de métriques et le sous-chemin
metrics.
8.2.4. Configuration pour l'extraction de métriques personnalisées
La collecte de métriques personnalisées est effectuée par une instance de Prometheus destinée à la surveillance de la charge de travail de l'utilisateur. Une fois que vous avez activé la surveillance de la charge de travail de l'utilisateur et créé l'application, vous avez besoin d'une configuration qui définit comment la pile de surveillance récupérera les métriques.
L'exemple de configuration suivant définit le site ksvc pour votre application et configure le moniteur de service. La configuration exacte dépend de votre application et de la manière dont elle exporte les métriques.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
spec:
template:
metadata:
labels:
app: helloworld-go
annotations:
spec:
containers:
- image: docker.io/skonto/helloworld-go:metrics
resources:
requests:
cpu: "200m"
env:
- name: TARGET
value: "Go Sample v1"
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
name: helloworld-go-sm
spec:
endpoints:
- port: queue-proxy-metrics
scheme: http
- port: app-metrics
scheme: http
namespaceSelector: {}
selector:
matchLabels:
name: helloworld-go-sm
---
apiVersion: v1
kind: Service
metadata:
labels:
name: helloworld-go-sm
name: helloworld-go-sm
spec:
ports:
- name: queue-proxy-metrics
port: 9091
protocol: TCP
targetPort: 9091
- name: app-metrics
port: 9095
protocol: TCP
targetPort: 9095
selector:
serving.knative.dev/service: helloworld-go
type: ClusterIP8.2.5. Examiner les paramètres d'un service
Après avoir configuré l'application pour qu'elle exporte les métriques et la pile de surveillance pour qu'elle les récupère, vous pouvez examiner les métriques dans la console web.
Conditions préalables
- Vous vous êtes connecté à la console web de OpenShift Container Platform.
- Vous avez installé OpenShift Serverless Operator et Knative Serving.
Procédure
Facultatif : Exécutez des requêtes sur votre application que vous pourrez voir dans les métriques :
$ hello_route=$(oc get ksvc helloworld-go -n ns1 -o jsonpath='{.status.url}') && \ curl $hello_routeExemple de sortie
Hello Go Sample v1!-
Dans la console web, naviguez jusqu'à l'interface Observe
Metrics. Dans le champ de saisie, entrez la requête pour la mesure que vous voulez observer, par exemple :
revision_app_request_count{namespace="ns1", job="helloworld-go-sm"}Autre exemple :
myapp_processed_ops_total{namespace="ns1", job="helloworld-go-sm"}Observez les mesures visualisées :
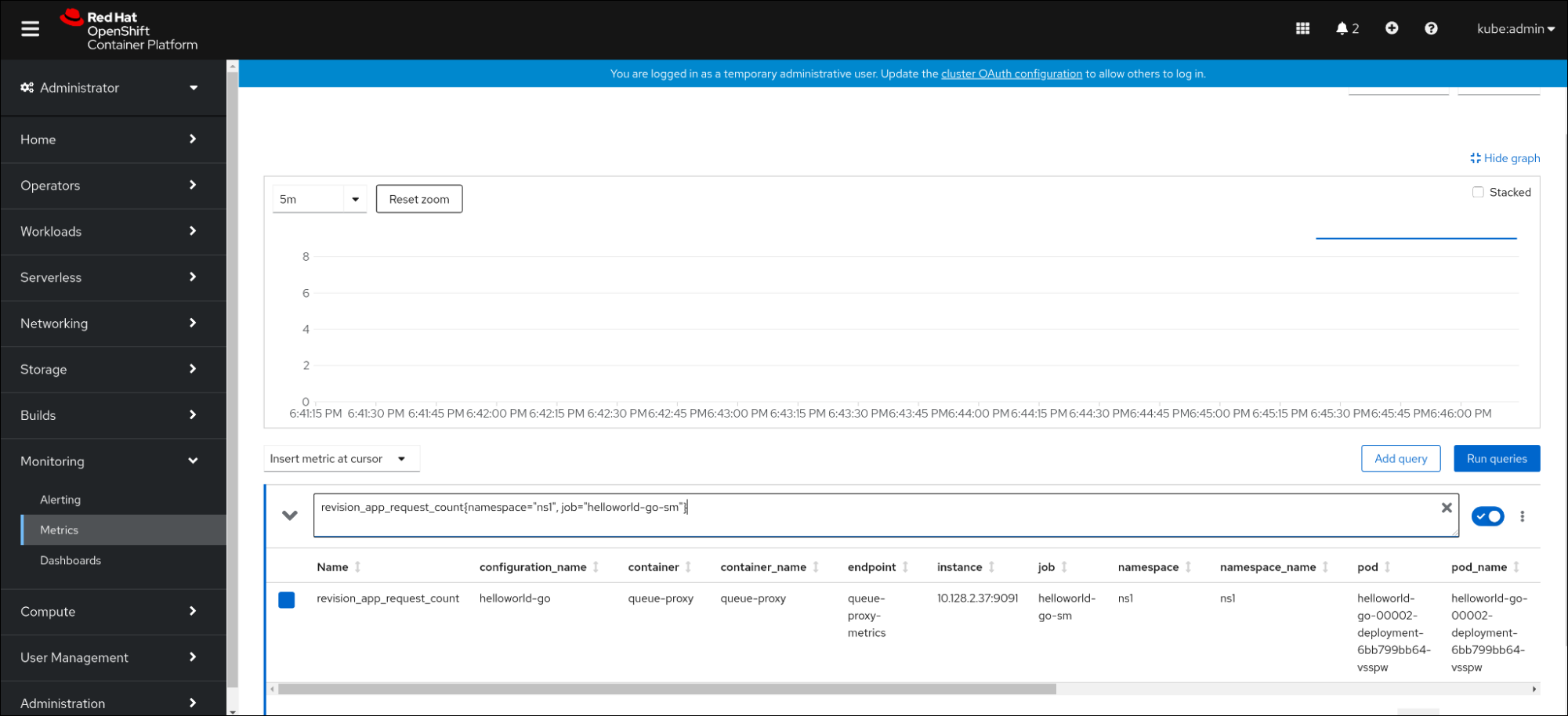
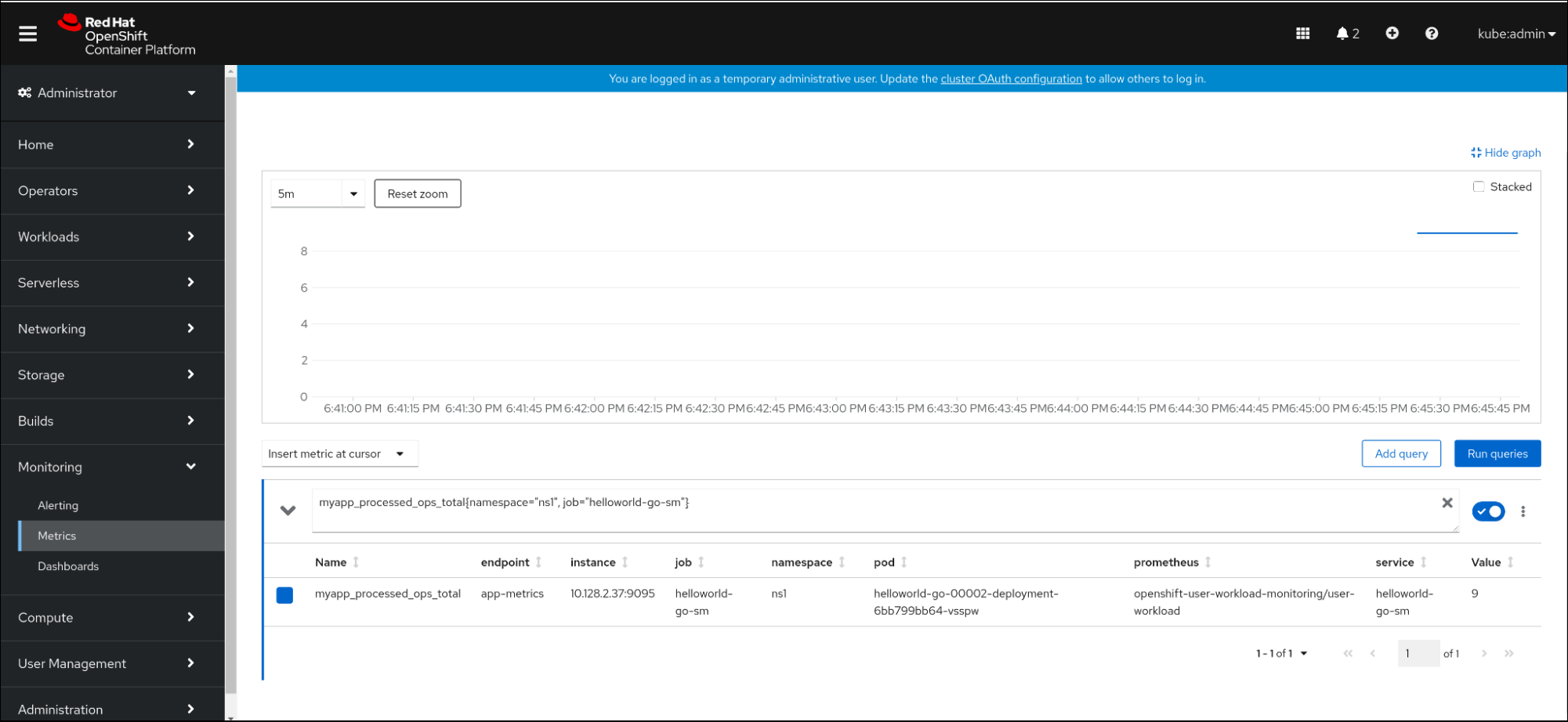
8.2.5.1. Métriques de proxy de file d'attente
Chaque service Knative dispose d'un conteneur proxy qui transmet les connexions au conteneur d'application. Un certain nombre de mesures sont rapportées pour la performance du proxy de file d'attente.
Vous pouvez utiliser les mesures suivantes pour déterminer si les demandes sont mises en file d'attente du côté du proxy et le délai réel de traitement des demandes du côté de l'application.
| Nom de la métrique | Description | Type | Tags | Unité |
|---|---|---|---|---|
|
|
Le nombre de demandes qui sont acheminées vers le pod | Compteur |
| Entier (pas d'unité) |
|
| Le temps de réponse des demandes de révision. | Histogramme |
| Millisecondes |
|
|
Nombre de requêtes acheminées vers le pod | Compteur |
| Entier (pas d'unité) |
|
| Le temps de réponse des demandes d'application de révision. | Histogramme |
| Millisecondes |
|
|
Nombre actuel d'éléments dans les files d'attente | Jauge |
| Entier (pas d'unité) |
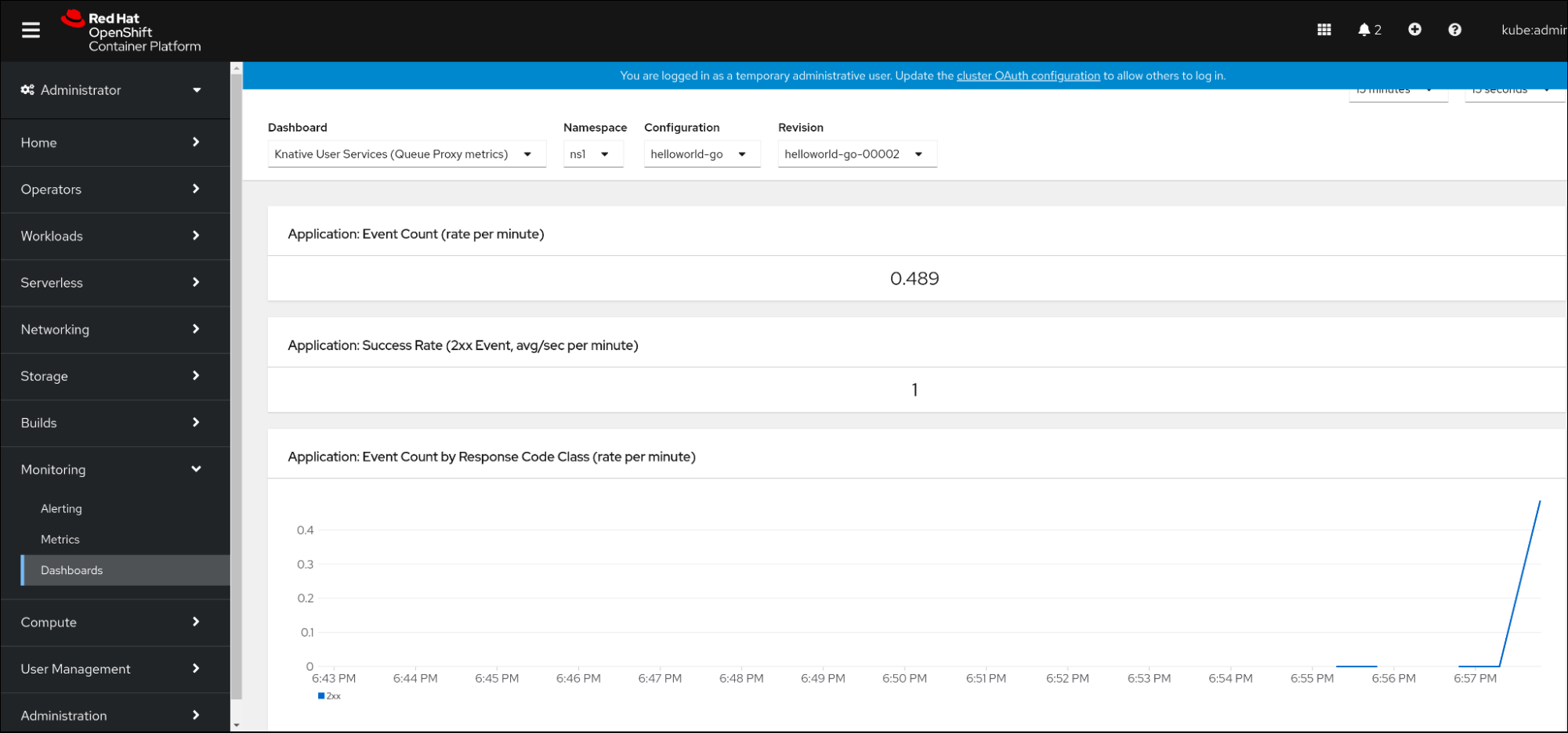
8.2.6. Tableau de bord pour les indicateurs de service
Vous pouvez examiner les mesures à l'aide d'un tableau de bord dédié qui regroupe les mesures de proxy de file d'attente par espace de noms.
8.2.6.1. Examiner les mesures d'un service dans le tableau de bord
Conditions préalables
- Vous vous êtes connecté à la console web de OpenShift Container Platform.
- Vous avez installé OpenShift Serverless Operator et Knative Serving.
Procédure
-
Dans la console web, naviguez jusqu'à l'interface Observe
Metrics. -
Sélectionnez le tableau de bord
Knative User Services (Queue Proxy metrics). - Sélectionnez les Namespace, Configuration, et Revision qui correspondent à votre application.
Observez les mesures visualisées :