2.4. Mise à l'échelle automatique des pods avec le pod autoscaler horizontal
En tant que développeur, vous pouvez utiliser un pod autoscaler horizontal (HPA) pour spécifier comment OpenShift Container Platform doit automatiquement augmenter ou diminuer l'échelle d'un contrôleur de réplication ou d'une configuration de déploiement, en fonction des métriques collectées à partir des pods qui appartiennent à ce contrôleur de réplication ou à cette configuration de déploiement. Vous pouvez créer un HPA pour n'importe quel déploiement, configuration de déploiement, ensemble de répliques, contrôleur de réplication ou ensemble avec état.
Pour plus d'informations sur la mise à l'échelle des pods en fonction de mesures personnalisées, voir Mise à l'échelle automatique des pods en fonction de mesures personnalisées.
Il est recommandé d'utiliser un objet Deployment ou ReplicaSet, sauf si vous avez besoin d'une fonctionnalité ou d'un comportement spécifique fourni par d'autres objets. Pour plus d'informations sur ces objets, voir Comprendre les objets Deployment et DeploymentConfig.
2.4.1. Comprendre les autoscalers de pods horizontaux
Vous pouvez créer un autoscaler de pods horizontal pour spécifier le nombre minimum et maximum de pods que vous souhaitez exécuter, ainsi que l'utilisation du CPU ou de la mémoire que vos pods doivent cibler.
Après avoir créé un autoscaler de pods horizontaux, OpenShift Container Platform commence à interroger les métriques de ressources CPU et/ou mémoire sur les pods. Lorsque ces métriques sont disponibles, l'autoscaler de pods horizontaux calcule le rapport entre l'utilisation actuelle de la métrique et l'utilisation souhaitée de la métrique, et augmente ou réduit l'échelle en conséquence. L'interrogation et la mise à l'échelle se produisent à intervalles réguliers, mais il peut s'écouler une à deux minutes avant que les mesures ne soient disponibles.
Pour les contrôleurs de réplication, cette mise à l'échelle correspond directement aux répliques du contrôleur de réplication. Pour les configurations de déploiement, la mise à l'échelle correspond directement au nombre de répliques de la configuration de déploiement. Notez que la mise à l'échelle automatique ne s'applique qu'au dernier déploiement dans la phase Complete.
OpenShift Container Platform prend automatiquement en compte les ressources et évite une mise à l'échelle automatique inutile lors des pics de ressources, comme lors du démarrage. Les pods dans l'état unready ont une utilisation de 0 CPU lors de la mise à l'échelle et l'autoscaler ignore les pods lors de la mise à l'échelle. Les pods sans métriques connues ont une utilisation de 0\fPU lors de la montée en charge et de 100\fPU lors de la descente en charge. Cela permet une plus grande stabilité lors de la décision HPA. Pour utiliser cette fonctionnalité, vous devez configurer des contrôles de disponibilité afin de déterminer si un nouveau module est prêt à être utilisé.
Pour utiliser les autoscalers de pods horizontaux, votre administrateur de cluster doit avoir correctement configuré les métriques de cluster.
2.4.1.1. Mesures prises en charge
Les métriques suivantes sont prises en charge par les autoscalers de pods horizontaux :
| Métrique | Description | Version de l'API |
|---|---|---|
| Utilisation de l'unité centrale | Nombre de cœurs de CPU utilisés. Peut être utilisé pour calculer un pourcentage de l'unité centrale demandée par le pod. |
|
| Utilisation de la mémoire | Quantité de mémoire utilisée. Peut être utilisé pour calculer un pourcentage de la mémoire demandée par le pod. |
|
Pour l'autoscaling basé sur la mémoire, l'utilisation de la mémoire doit augmenter et diminuer proportionnellement au nombre de répliques. En moyenne :
- Une augmentation du nombre de répliques doit entraîner une diminution globale de l'utilisation de la mémoire (ensemble de travail) par pod.
- Une diminution du nombre de répliques doit entraîner une augmentation globale de l'utilisation de la mémoire par pod.
Utilisez la console web d'OpenShift Container Platform pour vérifier le comportement de la mémoire de votre application et assurez-vous que votre application répond à ces exigences avant d'utiliser l'autoscaling basé sur la mémoire.
L'exemple suivant illustre la mise à l'échelle automatique de l'objet image-registry Deployment . Le déploiement initial nécessite 3 pods, l'objet HPA augmente le minimum à 5 pods. L'objet HPA augmente le minimum à 5. Si l'utilisation du CPU sur les pods atteint 75 %, les pods passent à 7 :
$ oc autoscale deployment/image-registry --min=5 --max=7 --cpu-percent=75Exemple de sortie
horizontalpodautoscaler.autoscaling/image-registry autoscaledExemple d'APS pour l'objet image-registry Deployment avec minReplicas fixé à 3
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: image-registry
namespace: default
spec:
maxReplicas: 7
minReplicas: 3
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: image-registry
targetCPUUtilizationPercentage: 75
status:
currentReplicas: 5
desiredReplicas: 0Afficher le nouvel état du déploiement :
$ oc get deployment image-registryIl y a maintenant 5 pods dans le déploiement :
Exemple de sortie
NAME REVISION DESIRED CURRENT TRIGGERED BY image-registry 1 5 5 config
2.4.2. Comment fonctionne l'APH ?
Le pod autoscaler horizontal (HPA) étend le concept de pod autoscaling. Le HPA vous permet de créer et de gérer un groupe de nœuds à charge équilibrée. Le HPA augmente ou diminue automatiquement le nombre de pods lorsqu'un seuil donné de CPU ou de mémoire est franchi.
Figure 2.1. Flux de travail de haut niveau de l'APH
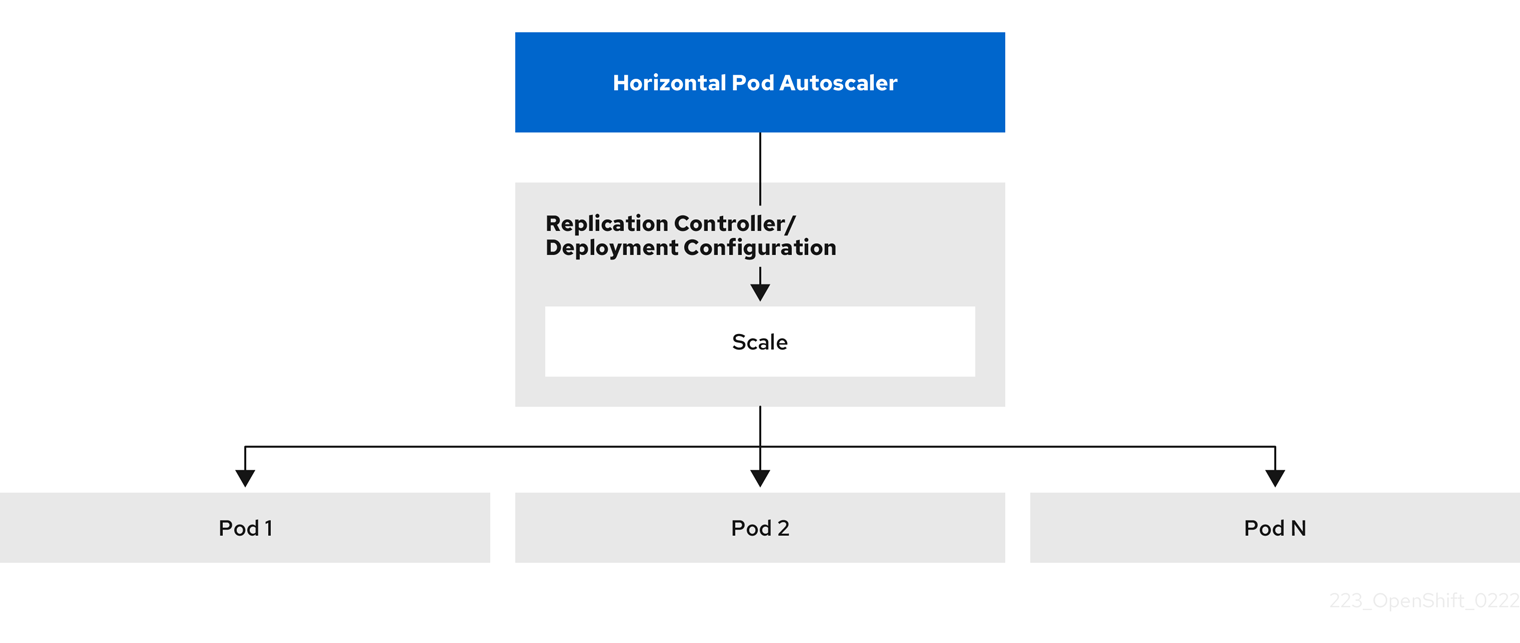
L'HPA est une ressource API dans le groupe API Kubernetes autoscaling. L'autoscaler fonctionne comme une boucle de contrôle avec une valeur par défaut de 15 secondes pour la période de synchronisation. Au cours de cette période, le gestionnaire du contrôleur interroge l'utilisation du CPU, de la mémoire, ou des deux, par rapport à ce qui est défini dans le fichier YAML pour l'HPA. Le gestionnaire de contrôleur obtient les métriques d'utilisation de l'API de métriques de ressources pour les métriques de ressources par pod comme le CPU ou la mémoire, pour chaque pod ciblé par l'HPA.
Si une valeur cible d'utilisation est définie, le contrôleur calcule la valeur d'utilisation en tant que pourcentage de la demande de ressources équivalente sur les conteneurs de chaque pod. Le contrôleur prend ensuite la moyenne de l'utilisation dans tous les pods ciblés et produit un ratio qui est utilisé pour mettre à l'échelle le nombre de répliques souhaitées. L'APH est configuré pour récupérer les métriques sur metrics.k8s.io, qui est fourni par le serveur de métriques. En raison de la nature dynamique de l'évaluation des métriques, le nombre de réplicas peut fluctuer lors de la mise à l'échelle d'un groupe de réplicas.
Pour mettre en œuvre l'APH, tous les pods ciblés doivent avoir une demande de ressource définie sur leurs conteneurs.
2.4.3. A propos des demandes et des limites
L'ordonnanceur utilise la demande de ressources que vous spécifiez pour les conteneurs d'un module, afin de décider sur quel nœud placer le module. Le kubelet applique la limite de ressources que vous spécifiez pour un conteneur afin de s'assurer que le conteneur n'est pas autorisé à utiliser plus que la limite spécifiée. Le kubelet réserve également la quantité demandée de cette ressource système spécifiquement pour l'utilisation de ce conteneur.
Comment utiliser les indicateurs de ressources ?
Dans les spécifications du pod, vous devez spécifier les demandes de ressources, telles que le CPU et la mémoire. Le HPA utilise cette spécification pour déterminer l'utilisation des ressources, puis augmente ou réduit la cible.
Par exemple, l'objet HPA utilise la source de métriques suivante :
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60Dans cet exemple, l'APH maintient l'utilisation moyenne des modules dans la cible de mise à l'échelle à 60 %. L'utilisation est le rapport entre l'utilisation actuelle de la ressource et la ressource demandée pour le module.
2.4.4. Meilleures pratiques
Tous les pods doivent avoir des demandes de ressources configurées
Le HPA prend une décision de mise à l'échelle basée sur les valeurs observées d'utilisation du CPU ou de la mémoire des pods dans un cluster OpenShift Container Platform. Les valeurs d'utilisation sont calculées en pourcentage des demandes de ressources de chaque pod. Des valeurs de demandes de ressources manquantes peuvent affecter les performances optimales de l'APH.
Configurer la période de refroidissement
Lors de la mise à l'échelle automatique des pods horizontaux, il peut y avoir une mise à l'échelle rapide des événements sans intervalle de temps. Configurez la période de refroidissement pour éviter les fluctuations fréquentes des répliques. Vous pouvez spécifier une période de refroidissement en configurant le champ stabilizationWindowSeconds. La fenêtre de stabilisation est utilisée pour limiter la fluctuation du nombre de répliques lorsque les métriques utilisées pour la mise à l'échelle continuent de fluctuer. L'algorithme de mise à l'échelle automatique utilise cette fenêtre pour déduire un état antérieur souhaité et éviter les changements non désirés de l'échelle de la charge de travail.
Par exemple, une fenêtre de stabilisation est spécifiée pour le champ scaleDown:
behavior:
scaleDown:
stabilizationWindowSeconds: 300Dans l'exemple ci-dessus, tous les états souhaités au cours des cinq dernières minutes sont pris en compte. Cela permet d'obtenir un maximum glissant et d'éviter que l'algorithme de mise à l'échelle ne supprime fréquemment des nacelles pour en recréer une équivalente quelques instants plus tard.
2.4.4.1. Politiques d'échelonnement
L'API autoscaling/v2 vous permet d'ajouter scaling policies à un pod autoscaler horizontal. Une politique de mise à l'échelle contrôle la façon dont l'autoscaler de pods horizontaux (HPA) de OpenShift Container Platform met à l'échelle les pods. Les politiques de mise à l'échelle vous permettent de limiter le taux de mise à l'échelle des pods par les HPA en définissant un nombre ou un pourcentage spécifique à mettre à l'échelle dans une période de temps spécifiée. Vous pouvez également définir une politique de mise à l'échelle stabilization window, qui utilise les états souhaités calculés précédemment pour contrôler la mise à l'échelle si les métriques fluctuent. Vous pouvez créer plusieurs politiques pour la même direction de mise à l'échelle et déterminer la politique à utiliser en fonction de la quantité de changement. Vous pouvez également limiter la mise à l'échelle par des itérations temporelles. L'APH met à l'échelle les pods au cours d'une itération, puis effectue la mise à l'échelle, si nécessaire, au cours des itérations suivantes.
Exemple d'objet HPA avec une politique de mise à l'échelle
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-resource-metrics-memory
namespace: default
spec:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
selectPolicy: Min
stabilizationWindowSeconds: 300
scaleUp:
policies:
- type: Pods
value: 5
periodSeconds: 70
- type: Percent
value: 12
periodSeconds: 80
selectPolicy: Max
stabilizationWindowSeconds: 0
...- 1
- Spécifie la direction de la politique de mise à l'échelle, soit
scaleDownouscaleUp. Cet exemple crée une politique de mise à l'échelle vers le bas. - 2
- Définit la politique de mise à l'échelle.
- 3
- Détermine si la politique s'adapte à un nombre spécifique de pods ou à un pourcentage de pods à chaque itération. La valeur par défaut est
pods. - 4
- Détermine la quantité de mise à l'échelle, soit le nombre de pods, soit le pourcentage de pods, à chaque itération. Il n'y a pas de valeur par défaut pour la mise à l'échelle par nombre de modules.
- 5
- Détermine la durée d'une itération de mise à l'échelle. La valeur par défaut est
15secondes. - 6
- La valeur par défaut de la réduction d'échelle en pourcentage est de 100 %.
- 7
- Détermine la politique à utiliser en premier, si plusieurs politiques sont définies. Spécifiez
Maxpour utiliser la stratégie qui autorise le plus grand nombre de changements,Minpour utiliser la stratégie qui autorise le plus petit nombre de changements, ouDisabledpour empêcher l'HPA de se mettre à l'échelle dans cette direction de stratégie. La valeur par défaut estMax. - 8
- Détermine la période de temps pendant laquelle l'APH doit revenir sur les états souhaités. La valeur par défaut est
0. - 9
- Cet exemple permet d'élaborer une politique de mise à l'échelle.
- 10
- Le montant de la mise à l'échelle du nombre de pods. La valeur par défaut de l'augmentation du nombre de modules est de 4 %.
- 11
- Le montant de la mise à l'échelle par le pourcentage de pods. La valeur par défaut de la mise à l'échelle par pourcentage est de 100 %.
Exemple de politique de réduction d'échelle
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-resource-metrics-memory
namespace: default
spec:
...
minReplicas: 20
...
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Pods
value: 4
periodSeconds: 30
- type: Percent
value: 10
periodSeconds: 60
selectPolicy: Max
scaleUp:
selectPolicy: Disabled
Dans cet exemple, lorsque le nombre de pods est supérieur à 40, la politique basée sur le pourcentage est utilisée pour la réduction d'échelle, car cette politique entraîne un changement plus important, comme l'exige le site selectPolicy.
S'il y a 80 répliques de pods, lors de la première itération, l'APH réduit les pods de 8, soit 10 % des 80 pods (sur la base des paramètres type: Percent et value: 10 ), en une minute (periodSeconds: 60). Pour l'itération suivante, le nombre de nacelles est de 72. L'APH calcule que 10 % des nacelles restantes représentent 7,2, qu'il arrondit à 8 et réduit de 8 nacelles. À chaque itération suivante, le nombre de nacelles à réduire est recalculé en fonction du nombre de nacelles restantes. Lorsque le nombre de nacelles est inférieur à 40, la politique basée sur les nacelles est appliquée, car le nombre basé sur les nacelles est supérieur au nombre basé sur le pourcentage. Le HPA réduit 4 pods à la fois (type: Pods et value: 4), sur 30 secondes (periodSeconds: 30), jusqu'à ce qu'il reste 20 répliques (minReplicas).
Le paramètre selectPolicy: Disabled empêche l'APH de mettre à l'échelle les pods. Vous pouvez augmenter manuellement l'échelle en ajustant le nombre de répliques dans l'ensemble de répliques ou l'ensemble de déploiement, si nécessaire.
Si elle est définie, vous pouvez visualiser la politique de mise à l'échelle à l'aide de la commande oc edit:
$ oc edit hpa hpa-resource-metrics-memoryExemple de sortie
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/behavior:\
'{"ScaleUp":{"StabilizationWindowSeconds":0,"SelectPolicy":"Max","Policies":[{"Type":"Pods","Value":4,"PeriodSeconds":15},{"Type":"Percent","Value":100,"PeriodSeconds":15}]},\
"ScaleDown":{"StabilizationWindowSeconds":300,"SelectPolicy":"Min","Policies":[{"Type":"Pods","Value":4,"PeriodSeconds":60},{"Type":"Percent","Value":10,"PeriodSeconds":60}]}}'
...2.4.5. Création d'un pod autoscaler horizontal à l'aide de la console web
Depuis la console web, vous pouvez créer un pod autoscaler horizontal (HPA) qui spécifie le nombre minimum et maximum de pods que vous souhaitez exécuter sur un objet Deployment ou DeploymentConfig. Vous pouvez également définir la quantité d'utilisation de CPU ou de mémoire que vos pods doivent cibler.
Un HPA ne peut pas être ajouté aux déploiements qui font partie d'un service soutenu par un opérateur, d'un service Knative ou d'une carte Helm.
Procédure
Pour créer un HPA dans la console web :
- Dans la vue Topology, cliquez sur le nœud pour faire apparaître le volet latéral.
Dans la liste déroulante Actions, sélectionnez Add HorizontalPodAutoscaler pour ouvrir le formulaire Add HorizontalPodAutoscaler.
Figure 2.2. Ajouter HorizontalPodAutoscaler
Dans le formulaire Add HorizontalPodAutoscaler, définissez le nom, les limites minimales et maximales du pod, l'utilisation du processeur et de la mémoire, et cliquez sur Save.
NoteSi l'une des valeurs de l'utilisation du processeur et de la mémoire est manquante, un avertissement s'affiche.
Pour éditer un HPA dans la console web :
- Dans la vue Topology, cliquez sur le nœud pour faire apparaître le volet latéral.
- Dans la liste déroulante Actions, sélectionnez Edit HorizontalPodAutoscaler pour ouvrir le formulaire Edit Horizontal Pod Autoscaler.
- Dans le formulaire Edit Horizontal Pod Autoscaler, modifiez les limites minimales et maximales du pod et l'utilisation du CPU et de la mémoire, puis cliquez sur Save.
Lors de la création ou de la modification du pod autoscaler horizontal dans la console web, vous pouvez passer de Form view à YAML view.
Pour supprimer un HPA dans la console web :
- Dans la vue Topology, cliquez sur le nœud pour faire apparaître le panneau latéral.
- Dans la liste déroulante Actions, sélectionnez Remove HorizontalPodAutoscaler.
- Dans la fenêtre de confirmation, cliquez sur Remove pour supprimer le HPA.
2.4.6. Création d'un pod autoscaler horizontal pour l'utilisation du CPU à l'aide de la CLI
À l'aide de la CLI d'OpenShift Container Platform, vous pouvez créer un pod autoscaler horizontal (HPA) pour mettre automatiquement à l'échelle un objet existant Deployment, DeploymentConfig, ReplicaSet, ReplicationController, ou StatefulSet. Le HPA met à l'échelle les pods associés à cet objet pour maintenir l'utilisation du CPU que vous spécifiez.
Il est recommandé d'utiliser un objet Deployment ou ReplicaSet, sauf si vous avez besoin d'une fonction ou d'un comportement spécifique fourni par d'autres objets.
Le HPA augmente et diminue le nombre de répliques entre les nombres minimum et maximum pour maintenir l'utilisation spécifiée du CPU dans tous les pods.
Lors de l'autoscaling pour l'utilisation du CPU, vous pouvez utiliser la commande oc autoscale et spécifier le nombre minimum et maximum de pods que vous souhaitez exécuter à tout moment et l'utilisation moyenne du CPU que vos pods doivent cibler. Si vous ne spécifiez pas de minimum, les pods reçoivent des valeurs par défaut du serveur OpenShift Container Platform.
Pour adapter l'autoscale à une valeur de CPU spécifique, créez un objet HorizontalPodAutoscaler avec la CPU cible et les limites du pod.
Conditions préalables
Pour utiliser les autoscalers de pods horizontaux, votre administrateur de cluster doit avoir correctement configuré les métriques du cluster. Vous pouvez utiliser la commande oc describe PodMetrics <pod-name> pour déterminer si les métriques sont configurées. Si les métriques sont configurées, la sortie est similaire à ce qui suit, avec Cpu et Memory affichés sous Usage.
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internalExemple de sortie
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>Procédure
Pour créer un pod autoscaler horizontal pour l'utilisation du CPU :
Effectuez l'une des opérations suivantes :
Pour mettre à l'échelle en fonction du pourcentage d'utilisation du processeur, créez un objet
HorizontalPodAutoscalerpour un objet existant :$ oc autoscale <object_type>/<name> \1 --min <number> \2 --max <number> \3 --cpu-percent=<percent>4 - 1
- Spécifiez le type et le nom de l'objet à mettre à l'échelle. L'objet doit exister et être un
Deployment,DeploymentConfig/dc,ReplicaSet/rs,ReplicationController/rc, ouStatefulSet. - 2
- Optionnellement, spécifier le nombre minimum de répliques lors d'une réduction d'échelle.
- 3
- Spécifiez le nombre maximum de répliques lors de la mise à l'échelle.
- 4
- Spécifiez l'utilisation moyenne de l'unité centrale cible sur tous les pods, représentée en pourcentage de l'unité centrale demandée. Si elle n'est pas spécifiée ou si elle est négative, une politique de mise à l'échelle automatique par défaut est utilisée.
Par exemple, la commande suivante montre la mise à l'échelle automatique de l'objet
image-registryDeployment. Le déploiement initial nécessite 3 pods, l'objet HPA augmente le minimum à 5. L'objet HPA augmente le minimum à 5. Si l'utilisation du CPU sur les pods atteint 75 %, les pods passeront à 7 :$ oc autoscale deployment/image-registry --min=5 --max=7 --cpu-percent=75Pour mettre à l'échelle une valeur de CPU spécifique, créez un fichier YAML similaire au suivant pour un objet existant :
Créez un fichier YAML similaire au suivant :
apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: cpu-autoscale2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: cpu9 target: type: AverageValue10 averageValue: 500m11 - 1
- Utilisez l'API
autoscaling/v2. - 2
- Spécifiez un nom pour cet objet autoscaler de pods horizontaux.
- 3
- Indiquez la version API de l'objet à mettre à l'échelle :
-
Pour un objet
Deployment,ReplicaSet,Statefulset, utilisezapps/v1. -
Pour un
ReplicationController, utilisezv1. -
Pour un
DeploymentConfig, utilisezapps.openshift.io/v1.
-
Pour un objet
- 4
- Spécifiez le type d'objet. L'objet doit être un
Deployment,DeploymentConfig/dc,ReplicaSet/rs,ReplicationController/rc, ouStatefulSet. - 5
- Indiquez le nom de l'objet à mettre à l'échelle. L'objet doit exister.
- 6
- Spécifiez le nombre minimum de répliques lors de la réduction d'échelle.
- 7
- Spécifiez le nombre maximum de répliques lors de la mise à l'échelle.
- 8
- Utilisez le paramètre
metricspour l'utilisation de la mémoire. - 9
- Spécifiez
cpupour l'utilisation de l'unité centrale. - 10
- Régler sur
AverageValue. - 11
- Réglé sur
averageValueavec la valeur ciblée de l'unité centrale.
Créer le pod autoscaler horizontal :
oc create -f <nom-de-fichier>.yaml
Vérifiez que le pod horizontal autoscaler a été créé :
$ oc get hpa cpu-autoscaleExemple de sortie
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE cpu-autoscale Deployment/example 173m/500m 1 10 1 20m
2.4.7. Création d'un objet autoscaler pod horizontal pour l'utilisation de la mémoire à l'aide de la CLI
À l'aide de la CLI d'OpenShift Container Platform, vous pouvez créer un pod autoscaler horizontal (HPA) pour mettre automatiquement à l'échelle un objet existant Deployment, DeploymentConfig, ReplicaSet, ReplicationController, ou StatefulSet. Le HPA met à l'échelle les pods associés à cet objet pour maintenir l'utilisation moyenne de la mémoire que vous spécifiez, soit une valeur directe, soit un pourcentage de la mémoire demandée.
Il est recommandé d'utiliser un objet Deployment ou ReplicaSet, sauf si vous avez besoin d'une fonction ou d'un comportement spécifique fourni par d'autres objets.
L'APH augmente et diminue le nombre de répliques entre les nombres minimum et maximum pour maintenir l'utilisation de la mémoire spécifiée dans tous les pods.
Pour l'utilisation de la mémoire, vous pouvez spécifier le nombre minimum et maximum de pods et l'utilisation moyenne de la mémoire que vos pods doivent viser. Si vous ne spécifiez pas de minimum, les pods reçoivent des valeurs par défaut du serveur OpenShift Container Platform.
Conditions préalables
Pour utiliser les autoscalers de pods horizontaux, votre administrateur de cluster doit avoir correctement configuré les métriques du cluster. Vous pouvez utiliser la commande oc describe PodMetrics <pod-name> pour déterminer si les métriques sont configurées. Si les métriques sont configurées, la sortie est similaire à ce qui suit, avec Cpu et Memory affichés sous Usage.
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-129-223.compute.internal -n openshift-kube-schedulerExemple de sortie
Name: openshift-kube-scheduler-ip-10-0-129-223.compute.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Cpu: 0
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2020-02-14T22:21:14Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-129-223.compute.internal
Timestamp: 2020-02-14T22:21:14Z
Window: 5m0s
Events: <none>Procédure
Pour créer un autoscaler de pods horizontaux pour l'utilisation de la mémoire :
Créez un fichier YAML pour l'un des éléments suivants :
Pour mettre à l'échelle une valeur de mémoire spécifique, créez un objet
HorizontalPodAutoscalersimilaire au suivant pour un objet existant :apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: hpa-resource-metrics-memory2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: memory9 target: type: AverageValue10 averageValue: 500Mi11 behavior:12 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Pods value: 4 periodSeconds: 60 - type: Percent value: 10 periodSeconds: 60 selectPolicy: Max- 1
- Utilisez l'API
autoscaling/v2. - 2
- Spécifiez un nom pour cet objet autoscaler de pods horizontaux.
- 3
- Indiquez la version API de l'objet à mettre à l'échelle :
-
Pour un objet
Deployment,ReplicaSet, ouStatefulset, utilisezapps/v1. -
Pour un
ReplicationController, utilisezv1. -
Pour un
DeploymentConfig, utilisezapps.openshift.io/v1.
-
Pour un objet
- 4
- Spécifiez le type d'objet. L'objet doit être un
Deployment,DeploymentConfig,ReplicaSet,ReplicationController, ouStatefulSet. - 5
- Indiquez le nom de l'objet à mettre à l'échelle. L'objet doit exister.
- 6
- Spécifiez le nombre minimum de répliques lors de la réduction d'échelle.
- 7
- Spécifiez le nombre maximum de répliques lors de la mise à l'échelle.
- 8
- Utilisez le paramètre
metricspour l'utilisation de la mémoire. - 9
- Spécifiez
memorypour l'utilisation de la mémoire. - 10
- Réglez le type sur
AverageValue. - 11
- Spécifiez
averageValueet une valeur de mémoire spécifique. - 12
- Facultatif : Spécifiez une politique de mise à l'échelle pour contrôler le taux de mise à l'échelle vers le haut ou vers le bas.
Pour mettre à l'échelle un pourcentage, créez un objet
HorizontalPodAutoscalersimilaire au suivant pour un objet existant :apiVersion: autoscaling/v21 kind: HorizontalPodAutoscaler metadata: name: memory-autoscale2 namespace: default spec: scaleTargetRef: apiVersion: apps/v13 kind: Deployment4 name: example5 minReplicas: 16 maxReplicas: 107 metrics:8 - type: Resource resource: name: memory9 target: type: Utilization10 averageUtilization: 5011 behavior:12 scaleUp: stabilizationWindowSeconds: 180 policies: - type: Pods value: 6 periodSeconds: 120 - type: Percent value: 10 periodSeconds: 120 selectPolicy: Max- 1
- Utilisez l'API
autoscaling/v2. - 2
- Spécifiez un nom pour cet objet autoscaler de pods horizontaux.
- 3
- Indiquez la version API de l'objet à mettre à l'échelle :
-
Pour un ReplicationController, utilisez
v1. -
Pour un DeploymentConfig, utilisez
apps.openshift.io/v1. -
Pour un objet Deployment, ReplicaSet, Statefulset, utilisez
apps/v1.
-
Pour un ReplicationController, utilisez
- 4
- Spécifiez le type d'objet. L'objet doit être un
Deployment,DeploymentConfig,ReplicaSet,ReplicationController, ouStatefulSet. - 5
- Indiquez le nom de l'objet à mettre à l'échelle. L'objet doit exister.
- 6
- Spécifiez le nombre minimum de répliques lors de la réduction d'échelle.
- 7
- Spécifiez le nombre maximum de répliques lors de la mise à l'échelle.
- 8
- Utilisez le paramètre
metricspour l'utilisation de la mémoire. - 9
- Spécifiez
memorypour l'utilisation de la mémoire. - 10
- Régler sur
Utilization. - 11
- Spécifiez
averageUtilizationet un objectif d'utilisation moyenne de la mémoire sur tous les pods, représenté en pourcentage de la mémoire demandée. Les pods cibles doivent avoir des demandes de mémoire configurées. - 12
- Facultatif : Spécifiez une politique de mise à l'échelle pour contrôler le taux de mise à l'échelle vers le haut ou vers le bas.
Créer le pod autoscaler horizontal :
oc create -f <nom-de-fichier>.yamlPar exemple :
$ oc create -f hpa.yamlExemple de sortie
horizontalpodautoscaler.autoscaling/hpa-resource-metrics-memory createdVérifiez que le pod horizontal autoscaler a été créé :
$ oc get hpa hpa-resource-metrics-memoryExemple de sortie
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-resource-metrics-memory Deployment/example 2441216/500Mi 1 10 1 20m$ oc describe hpa hpa-resource-metrics-memoryExemple de sortie
Name: hpa-resource-metrics-memory Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Wed, 04 Mar 2020 16:31:37 +0530 Reference: Deployment/example Metrics: ( current / target ) resource memory on pods: 2441216 / 500Mi Min replicas: 1 Max replicas: 10 ReplicationController pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 6m34s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
2.4.8. Comprendre les conditions d'état du pod autoscaler horizontal à l'aide de la CLI
Vous pouvez utiliser les conditions d'état définies pour déterminer si l'autoscaler de pods horizontaux (HPA) est capable ou non de se mettre à l'échelle et s'il est actuellement limité de quelque manière que ce soit.
Les conditions d'état HPA sont disponibles avec la version v2 de l'API de mise à l'échelle automatique.
L'APH répond par les états suivants :
La condition
AbleToScaleindique si HPA est en mesure de récupérer et de mettre à jour les mesures, et si des conditions liées au backoff risquent d'empêcher la mise à l'échelle.-
Une condition
Trueindique que la mise à l'échelle est autorisée. -
Une condition
Falseindique que la mise à l'échelle n'est pas autorisée pour la raison spécifiée.
-
Une condition
La condition
ScalingActiveindique si le HPA est activé (par exemple, le nombre de répliques de la cible n'est pas nul) et s'il est en mesure de calculer les mesures souhaitées.-
Une condition
Trueindique que les mesures fonctionnent correctement. -
Une condition
Falseindique généralement un problème de récupération des données.
-
Une condition
La condition
ScalingLimitedindique que l'échelle souhaitée a été plafonnée par le maximum ou le minimum de l'échelle automatique du pod horizontal.-
Une condition
Trueindique que vous devez augmenter ou diminuer le nombre minimum ou maximum de répliques afin de procéder à une mise à l'échelle. La condition
Falseindique que la mise à l'échelle demandée est autorisée.$ oc describe hpa cm-testExemple de sortie
Name: cm-test Namespace: prom Labels: <none> Annotations: <none> CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000 Reference: ReplicationController/cm-test Metrics: ( current / target ) "http_requests" on pods: 66m / 500m Min replicas: 1 Max replicas: 4 ReplicationController pods: 1 current / 1 desired Conditions:1 Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range Events:- 1
- Les messages d'état de l'autoscaler du pod horizontal.
-
Une condition
Voici un exemple d'un module qui ne peut pas être mis à l'échelle :
Exemple de sortie
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale False FailedGetScale the HPA controller was unable to get the target's current scale: no matches for kind "ReplicationController" in group "apps"
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetScale 6s (x3 over 36s) horizontal-pod-autoscaler no matches for kind "ReplicationController" in group "apps"Voici un exemple de pod qui n'a pas pu obtenir les métriques nécessaires à la mise à l'échelle :
Exemple de sortie
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics APIVoici un exemple de pod où l'autoscaling demandé était inférieur aux minimums requis :
Exemple de sortie
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range2.4.8.1. Visualisation des conditions d'état des pods horizontaux autoscaler à l'aide de la CLI
Vous pouvez visualiser les conditions d'état définies sur un pod par le pod autoscaler horizontal (HPA).
Les conditions d'état de l'autoscaler de pods horizontaux sont disponibles avec la version v2 de l'API d'autoscaling.
Conditions préalables
Pour utiliser les autoscalers de pods horizontaux, votre administrateur de cluster doit avoir correctement configuré les métriques du cluster. Vous pouvez utiliser la commande oc describe PodMetrics <pod-name> pour déterminer si les métriques sont configurées. Si les métriques sont configurées, la sortie est similaire à ce qui suit, avec Cpu et Memory affichés sous Usage.
$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internalExemple de sortie
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Namespace: openshift-kube-scheduler
Labels: <none>
Annotations: <none>
API Version: metrics.k8s.io/v1beta1
Containers:
Name: wait-for-host-port
Usage:
Memory: 0
Name: scheduler
Usage:
Cpu: 8m
Memory: 45440Ki
Kind: PodMetrics
Metadata:
Creation Timestamp: 2019-05-23T18:47:56Z
Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal
Timestamp: 2019-05-23T18:47:56Z
Window: 1m0s
Events: <none>Procédure
Pour afficher les conditions d'état d'un module, utilisez la commande suivante avec le nom du module :
oc describe hpa <pod-name> $ oc describe hpa <pod-name>Par exemple :
$ oc describe hpa cm-test
Les conditions apparaissent dans le champ Conditions de la sortie.
Exemple de sortie
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_request
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range