4.14. 故障排除
您可以使用 OpenShift CLI 工具或 Velero CLI 工具调试 Velero 自定义资源(CR)。Velero CLI 工具提供更详细的日志和信息。
您可以检查 安装问题、备份和恢复 CR 问题,以及 Restic 问题。
您可以使用 must-gather 工具收集日志和 CR 信息。
您可以通过以下方法获取 Velero CLI 工具:
- 下载 Velero CLI 工具
- 访问集群中的 Velero 部署中的 Velero 二进制文件
4.14.1. 下载 Velero CLI 工具
您可以按照 Velero 文档页面中的说明下载并安装 Velero CLI 工具。
该页面包括:
- 使用 Homebrew 的 macOS
- GitHub
- 使用 Chocolatey 的 Windows
先决条件
- 您可以访问启用了 DNS 和容器网络的 Kubernetes 集群 v1.16 或更高版本。
-
您已在本地安装了
kubectl。
流程
- 打开浏览器,进入到在 Velero 网站上的"安装 CLI"。
- 按照 macOS、GitHub 或 Windows 的适当流程。
- 下载适用于 OADP 和 OpenShift Container Platform 版本的 Velero 版本。
4.14.1.1. OADP-Velero-OpenShift Container Platform 版本关系
| OADP 版本 | Velero 版本 | OpenShift Container Platform 版本 |
|---|---|---|
| 1.1.0 | 4.9 及更新的版本 | |
| 1.1.1 | 4.9 及更新的版本 | |
| 1.1.2 | 4.9 及更新的版本 | |
| 1.1.3 | 4.9 及更新的版本 | |
| 1.1.4 | 4.9 及更新的版本 | |
| 1.1.5 | 4.9 及更新的版本 | |
| 1.1.6 | 4.11 及更新的版本 | |
| 1.1.7 | 4.11 及更新的版本 | |
| 1.2.0 | 4.11 及更新的版本 | |
| 1.2.1 | 4.11 及更新的版本 | |
| 1.2.2 | 4.11 及更新的版本 | |
| 1.2.3 | 4.11 及更新的版本 | |
| 1.3.0 | 4.10-4.15 | |
| 1.3.1 | 4.10-4.15 | |
| 1.3.2 | 4.10-4.15 | |
| 1.4.0 | 4.14-4.18 | |
| 1.4.1 | 4.14-4.18 | |
| 1.4.2 | 4.14-4.18 |
4.14.2. 访问集群中的 Velero 部署中的 Velero 二进制文件
您可以使用 shell 命令访问集群中的 Velero 部署中的 Velero 二进制文件。
先决条件
-
您的
DataProtectionApplication自定义资源的状态为Reconcile complete。
流程
输入以下命令设定所需的别名:
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.14.3. 使用 OpenShift CLI 工具调试 Velero 资源
您可以使用 OpenShift CLI 工具检查 Velero 自定义资源(CR)和 Velero pod 日志来调试失败的备份或恢复。
Velero CR
使用 oc describe 命令检索与 Backup 或 Restore CR 关联的警告和错误概述:
$ oc describe <velero_cr> <cr_name>
Velero pod 日志
使用 oc logs 命令检索 Velero pod 日志:
$ oc logs pod/<velero>
Velero pod 调试日志
您可以在 DataProtectionApplication 资源中指定 Velero 日志级别,如下例所示。
这个选项可从 OADP 1.0.3 开始。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
可用的 logLevel 值如下:
-
trace -
debug -
info -
warning -
错误 -
fatal -
panic
对于大多数日志,建议使用 info logLevel 值。
4.14.4. 使用 Velero CLI 工具调试 Velero 资源
您可以调试 Backup 和 Restore 自定义资源(CR)并使用 Velero CLI 工具检索日志。
Velero CLI 工具比 OpenShift CLI 工具提供更详细的信息。
语法
使用 oc exec 命令运行 Velero CLI 命令:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> <command> <cr_name>
Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
帮助选项
使用 velero --help 列出所有 Velero CLI 命令:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ --help
describe 命令
使用 velero describe 命令检索与 Backup 或 Restore CR 关联的警告和错误概述:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> describe <cr_name>
Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
velero describe 请求的输出中会显示以下类型的恢复错误和警告:
-
Velero: 与 Velero 本身操作相关的信息列表,例如:与连接到云相关的信息,读取备份文件等 -
集群:与备份和恢复集群范围的资源相关的消息列表 -
命名空间:与备份或恢复存储在命名空间中资源相关的消息列表
这些类别中的一个或多个错误会导致 Restore 操作接收 PartiallyFailed 而不是 Completed 状态。警告不会造成完成状态的更改。
-
对于特定于资源的错误,即
Cluster和Namespaces错误,restore describe --details输出包含一个资源列表,其中列出了 Velero 在恢复中成功的所有资源。对于具有此类错误的任何资源,请检查资源是否实际位于集群中。 如果存在
Velero错误,但没有特定于资源的错误,在describe命令的输出中没有完成恢复,且没有恢复工作负载中的实际问题,但仔细验证恢复后应用程序。例如,如果输出包含
PodVolumeRestore或节点代理相关的错误,请检查PodVolumeRestores和DataDownloads的状态。如果其中任何失败或仍在运行,则卷数据可能已被完全恢复。
logs 命令
使用 velero logs 命令检索 Backup 或 Restore CR 的日志:
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> logs <cr_name>
Example
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf
4.14.5. 因内存不足或 CPU 造成 pod 崩溃或重启
如果 Velero 或 Restic pod 因为缺少内存或 CPU 而导致崩溃,您可以为其中任何一个资源设置特定的资源请求。
其他资源
4.14.5.1. 为 Velero pod 设置资源请求
您可以使用 oadp_v1alpha1_dpa.yaml 文件中的 configuration.velero.podConfig.resourceAllocations 规格字段为 Velero pod 设置特定的资源请求。
流程
在 YAML 文件中设置
cpu和memory资源请求:Velero 文件示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations: 1 requests: cpu: 200m memory: 256Mi- 1
- 列出的
resourceAllocations用于平均使用。
4.14.5.2. 为 Restic pod 设置资源请求
您可以使用 configuration.restic.podConfig.resourceAllocations specification 字段为 Restic pod 设置特定的资源请求。
流程
在 YAML 文件中设置
cpu和memory资源请求:Restic 文件示例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations: 1 requests: cpu: 1000m memory: 16Gi- 1
- 列出的
resourceAllocations用于平均使用。
资源请求字段的值必须遵循与 Kubernetes 资源要求相同的格式。另外,如果您没有指定 configuration.velero.podConfig.resourceAllocations 或 configuration.restic.podConfig.resourceAllocations,则 Velero pod 或 Restic pod 的默认 resources 规格如下:
requests: cpu: 500m memory: 128Mi
4.14.6. 当 StorageClass 是 NFS 时,PodVolumeRestore 无法完成
当使用 Restic 或 Kopia 在 NFS 恢复过程中有多个卷时,恢复操作会失败。PodVolumeRestore 失败并显示以下错误,或者在最终失败前尝试恢复。
错误消息
Velero: pod volume restore failed: data path restore failed: \ Failed to run kopia restore: Failed to copy snapshot data to the target: \ restore error: copy file: error creating file: \ open /host_pods/b4d...6/volumes/kubernetes.io~nfs/pvc-53...4e5/userdata/base/13493/2681: \ no such file or directory
原因
对于要恢复的两个卷,NFS 挂载路径不唯一。因此,在恢复过程中,velero 锁定文件在 NFS 服务器上使用相同的文件,从而导致 PodVolumeRestore 失败。
解决方案
您可以通过为每个卷设置唯一的 pathPattern 来解决这个问题,同时在 deploy/class.yaml 文件中定义 nfs-subdir-external-provisioner 的 StorageClass。使用以下 nfs-subdir-external-provisioner StorageClass 示例:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
pathPattern: "${.PVC.namespace}/${.PVC.annotations.nfs.io/storage-path}" 1
onDelete: delete- 1
- 使用
PVC元数据(如标签、注解、名称或命名空间)指定用于创建目录路径的模板。要指定元数据,请使用${.PVC.<metadata>}。例如,要将文件夹命名为:<pvc-namespace>-<pvc-name>,使用${.PVC.namespace}-${.PVC.name}作为pathPattern。
4.14.7. Velero 和准入 Webhook 的问题
Velero 在恢复过程中解决准入 Webhook 问题的能力有限。如果您的工作负载带有准入 webhook,您可能需要使用额外的 Velero 插件或更改如何恢复工作负载。
通常,带有准入 Webhook 的工作负载需要您首先创建特定类型的资源。如果您的工作负载具有子资源,因为准入 webhook 通常阻止子资源,则会出现这种情况。
例如,创建或恢复顶层对象,如 service.serving.knative.dev 通常会自动创建子资源。如果您首先这样做,则不需要使用 Velero 创建和恢复这些资源。这可避免由 Velero 可使用的准入 Webhook 阻断子资源的问题。
4.14.7.1. 为使用准入 webhook 的 Velero 备份恢复临时解决方案
本节介绍了使用准入 webhook 的一些类型的 Velero 备份恢复资源所需的额外步骤。
4.14.7.1.1. 恢复 Knative 资源
您可能会遇到使用 Velero 备份使用准入 webhook 的 Knative 资源的问题。
在备份和恢复使用准入 webhook 的 Knative 资源时,您可以通过首先恢复顶层 Service 资源来避免这个问题。
流程
恢复顶层
service.serving.knavtive.dev Service资源:$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.14.7.1.2. 恢复 IBM AppConnect 资源
如果您使用 Velero 恢复具有准入 webhook 的 IBM® AppConnect 资源时遇到问题,您可以在此过程中运行检查。
流程
检查集群中是否有
kind: MutatingWebhookConfiguration的变异准入插件:$ oc get mutatingwebhookconfigurations
-
检查每个
kind: MutatingWebhookConfiguration的 YAML 文件,以确保其没有规则块创建存在问题的对象。如需更多信息,请参阅官方 Kubernetes 文档。 -
检查在备份时使用的
type: Configuration.appconnect.ibm.com/v1beta1中的spec.version被已安装的 Operator 支持。
4.14.7.2. OADP 插件的已知问题
以下章节介绍了 OpenShift API for Data Protection (OADP) 插件中的已知问题:
4.14.7.2.1. 因为缺少 secret,Velero 插件在镜像流备份过程中会出现错误
当在数据保护应用程序(DPA)范围外管理备份和备份存储位置(BSL)时,OADP 控制器,这意味着 DPA 协调不会创建相关的 oadp-<bsl_name>-<bl_provider>-registry-secret。
当备份运行时,OpenShift Velero 插件在镜像流备份中出现错误,并显示以下错误:
024-02-27T10:46:50.028951744Z time="2024-02-27T10:46:50Z" level=error msg="Error backing up item" backup=openshift-adp/<backup name> error="error executing custom action (groupResource=imagestreams.image.openshift.io, namespace=<BSL Name>, name=postgres): rpc error: code = Aborted desc = plugin panicked: runtime error: index out of range with length 1, stack trace: goroutine 94…
4.14.7.2.1.1. 临时解决方案以避免出现错误
要避免 Velero 插件 panic 错误,请执行以下步骤:
使用相关标签标记自定义 BSL:
$ oc label backupstoragelocations.velero.io <bsl_name> app.kubernetes.io/component=bsl
在标记 BSL 后,等待 DPA 协调。
注意您可以通过对 DPA 本身进行任何更改来强制进行协调。
当 DPA 协调时,确认相关的
oadp-<bsl_name>-<bsl_provider>-registry-secret已被填充到其中:$ oc -n openshift-adp get secret/oadp-<bsl_name>-<bsl_provider>-registry-secret -o json | jq -r '.data'
4.14.7.2.2. OpenShift ADP Controller 分段错误
如果您在同时启用了 cloudstorage 和 restic 的情况下配置 DPA,openshift-adp-controller-manager pod 会无限期重复崩溃和重启过程,直到 pod 出现一个崩溃循环分段错误为止。
您只能定义 velero 或 cloudstorage,它们是互斥的字段。
-
如果您同时定义了
velero和cloudstorage,openshift-adp-controller-manager会失败。 -
如果
velero和cloudstorage都没有定义,openshift-adp-controller-manager也将失败。
有关此问题的更多信息,请参阅 OADP-1054。
4.14.7.2.2.1. OpenShift ADP Controller 分段错误临时解决方案
在配置一个 DPA 时,您必须定义 velero 或 cloudstorage。如果您在 DPA 中同时定义了这两个 API,openshift-adp-controller-manager pod 会失败,并显示崩溃循环分段错误。
4.14.7.3. Velero 插件返回 "received EOF, stop recv loop" 信息
Velero 插件作为单独的进程启动。当 Velero 操作完成后,无论是否成功,它们都会退出。接收到 received EOF, stopping recv loop 消息表示插件操作已完成。这并不意味着发生了错误。
4.14.8. 安装问题
在安装数据保护应用程序时,您可能会遇到使用无效目录或不正确的凭证导致的问题。
4.14.8.1. 备份存储包含无效目录
Velero pod 日志显示错误消息,备份存储包含无效的顶级目录。
原因
对象存储包含不是 Velero 目录的顶级目录。
解决方案
如果对象存储不适用于 Velero,则必须通过设置 DataProtectionApplication 清单中的 spec.backupLocations.velero.objectStorage.prefix 参数为存储桶指定一个前缀。
4.14.8.2. AWS 凭证不正确
oadp-aws-registry pod 日志会显示错误消息 InvalidAccessKeyId: The AWS Access Key Id you provided does not exist in our records.
Velero pod 日志显示错误消息 NoCredentialProviders: no valid provider in chain。
原因
用于创建 Secret 对象的 credentials-velero 文件会错误地格式化。
解决方案
确保 credentials-velero 文件已正确格式化,如下例所示:
credentials-velero 文件示例
[default] 1 aws_access_key_id=AKIAIOSFODNN7EXAMPLE 2 aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
4.14.9. OADP Operator 问题
OpenShift API for Data Protection (OADP) Operator 可能会遇到它无法解决的问题。
4.14.9.1. OADP Operator 静默失败
OADP Operator 的 S3 存储桶可能为空,但在运行 oc get po -n <OADP_Operator_namespace> 命令时,您会看到 Operator 的状态变为 Running。在这种情况下,Operator 被认为有静默地失败,因为它错误地报告它正在运行。
原因
这个问题是因为云凭证提供的权限不足。
解决方案
检索备份存储位置列表(BSL),并检查每个 BSL 的清单是否有凭证问题。
流程
运行以下命令之一以检索 BSL 列表:
使用 OpenShift CLI:
$ oc get backupstoragelocations.velero.io -A
使用 Velero CLI:
$ velero backup-location get -n <OADP_Operator_namespace>
使用 BSL 列表,运行以下命令来显示每个 BSL 的清单,并检查每个清单是否有错误。
$ oc get backupstoragelocations.velero.io -n <namespace> -o yaml
结果示例
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""
4.14.10. OADP 超时
通过扩展超时,可以允许复杂的或资源密集型的进程在没有预先终止的情况下成功完成。此配置可减少错误、重试或失败的可能性。
确保您在扩展超时设置时符合正常的逻辑,,以便不会因为设置的超时时间太长导致隐藏了底层存在的问题。仔细考虑并监控超时设置,以符合相关进程的需求和整体系统性能要求。
以下是不同的 OADP 超时设置的信息:
4.14.10.1. Restic 超时
spec.configuration.nodeAgent.timeout 参数定义 Restic 超时。默认值为 1h。
在以下情况下,使用 nodeAgent 部分中的 Restic timeout 参数:
- 对总 PV 数据使用量大于 500GB 的 Restic 备份。
如果备份超时并显示以下错误:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
流程
编辑
DataProtectionApplication自定义资源(CR)清单的spec.configuration.nodeAgent.timeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: nodeAgent: enable: true uploaderType: restic timeout: 1h # ...
4.14.10.2. Velero 资源超时
resourceTimeout 定义在超时发生前等待 Velero 资源的时间,如等待 Velero 自定义资源定义 (CRD)可用、volumeSnapshot 删除和存储库可用。默认值为 10m。
在以下情况下使用 resourceTimeout :
对总 PV 数据使用量大于 1TB 的备份。当在将备份标记为完成前,Velero 尝试清理或删除 Container Storage Interface (CSI)快照时使用此参数作为超时值。
- 这个清理过程的一个子任务会尝试修补 VSC,此超时可用于该任务。
- 要创建或确保一个备份存储库已准备好用于 Restic 或 Kopia 的基于文件系统的备份。
- 在从备份中恢复自定义资源 (CR) 或资源前,检查集群中的 Velero CRD 是否可用。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.resourceTimeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.14.10.3. Data Mover timeout
timeout 是一个用户提供的、完成 VolumeSnapshotBackup 和 VolumeSnapshotRestore 的超时值。默认值为 10m。
在以下情况下使用 Data Mover timeout :
-
如果创建
VolumeSnapshotBackups(VSBs) 和VolumeSnapshotRestores(VSR),则会在 10 分钟后超时。 -
对于总 PV 数据使用量超过 500GB 的大型环境。设置
1h的超时时间。 -
使用
VolumeSnapshotMover(VSM) 插件。 - 只适用于 OADP 1.1.x。
流程
编辑
DataProtectionApplicationCR 清单的spec.features.dataMover.timeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.14.10.4. CSI 快照超时
CSISnapshotTimeout 指定,在创建过程返回超时错误前,需要等待 CSI VolumeSnapshot 状态变为 ReadyToUse 的时间。默认值为 10m。
在以下情况下使用 CSISnapshotTimeout :
- 使用 CSI 插件。
- 对于非常大型的存储卷,进行快照的时间可能会超过 10 分钟。如果在日志中出现超时信息,请调整此超时设置。
通常,不需要调整 CSISnapshotTimeout,因为默认设置已考虑到大型存储卷的情况。
流程
编辑
BackupCR 清单的spec.csiSnapshotTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.14.10.5. Velero 默认项目操作超时
defaultItemOperationTimeout 定义在超时前等待异步 BackupItemActions 和 RestoreItemActions 所需的时间。默认值为 1h。
在以下情况下使用 defaultItemOperationTimeout :
- 只有 Data Mover 1.2.x。
- 要指定一个特定备份或恢复应等待异步操作完成的时间长度。在 OADP 功能上下文中,这个值用于涉及 Container Storage Interface (CSI) Data Mover 功能的异步操作。
-
当使用
defaultItemOperationTimeout在 Data Protection Application (DPA) 中定义defaultItemOperationTimeout时,它适用于备份和恢复操作。您可以使用itemOperationTimeout来只定义这些 CR 的备份过程或恢复过程,如以下 "Item operation timeout - restore" 和 "Item operation timeout - backup" 部分所述。
流程
编辑
DataProtectionApplicationCR 清单的spec.configuration.velero.defaultItemOperationTimeout块中的值,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.14.10.6. 项目操作超时 - 恢复
ItemOperationTimeout 指定用于等待 RestoreItemAction 操作的时间。默认值为 1h。
在以下情况下,使用 restore ItemOperationTimeout :
- 只有 Data Mover 1.2.x。
-
对于 Data Mover,上传到
BackupStorageLocation或从其中下载。如果在达到超时时没有完成恢复操作,它将标记为失败。如果因为存储卷太大出现超时并导致数据 Data Mover 操作失败,则可能需要增加这个超时设置。
流程
编辑
RestoreCR 清单的Restore.spec.itemOperationTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.14.10.7. 项目操作超时 - 备份
ItemOperationTimeout 指定用于等待异步 BackupItemAction 操作的时间。默认值为 1h。
在以下情况下,使用 backup ItemOperationTimeout :
- 只有 Data Mover 1.2.x。
-
对于 Data Mover,上传到
BackupStorageLocation或从其中下载。如果在达到超时时没有完成备份操作,它将标记为失败。如果因为存储卷太大出现超时并导致数据 Data Mover 操作失败,则可能需要增加这个超时设置。
流程
编辑
BackupCR 清单的Backup.spec.itemOperationTimeout块中的值,如下例所示:apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.14.11. 备份和恢复 CR 问题
您可能会遇到 Backup 和 Restore 自定义资源(CR)的常见问题。
4.14.11.1. 备份 CR 无法检索卷
Backup CR 显示错误消息 InvalidVolume.NotFound: The volume ‘vol-xxxx’ does not exist。
原因
持久性卷(PV)和快照位置位于不同的区域。
解决方案
-
编辑
DataProtectionApplication清单中的spec.snapshotLocations.velero.config.region键的值,使快照位置位于与 PV 相同的区域。 -
创建新的
BackupCR。
4.14.11.2. 备份 CR 状态在进行中
Backup CR 的状态保留在 InProgress 阶段,且未完成。
原因
如果备份中断,则无法恢复。
解决方案
检索
BackupCR 的详细信息:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>删除
BackupCR:$ oc delete backups.velero.io <backup> -n openshift-adp
您不需要清理备份位置,因为正在进行中的
BackupCR 没有上传文件到对象存储。-
创建新的
BackupCR。 查看 Velero 备份详情
$ velero backup describe <backup-name> --details
4.14.11.3. 备份 CR 状态处于 PartiallyFailed
在没有 Restic 使用时一个 Backup CR 的状态保留在 PartiallyFailed 阶段,且没有完成。从属 PVC 的快照没有创建。
原因
如果备份是基于 CSI 快照类创建的,但缺少标签,CSI 快照插件将无法创建快照。因此,Velero pod 会记录类似如下的错误:
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq
解决方案
删除
BackupCR:$ oc delete backups.velero.io <backup> -n openshift-adp
-
如果需要,清理
BackupStorageLocation上存储的数据以释放空间。 将标签
velero.io/csi-volumesnapshot-class=true应用到VolumeSnapshotClass对象:$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true
-
创建新的
BackupCR。
4.14.12. Restic 问题
在使用 Restic 备份应用程序时,您可能会遇到这些问题。
4.14.12.1. 启用了 root_squash 的 NFS 数据卷的 Restic 权限错误
Restic pod 日志显示错误消息, controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied"。
原因
如果您的 NFS 数据卷启用了 root_squash,Restic 映射到 nfsnobody,且没有创建备份的权限。
解决方案
您可以通过为 Restic 创建补充组并将组 ID 添加到 DataProtectionApplication 清单中来解决这个问题:
-
在 NFS 数据卷中为
Restic创建补充组。 -
在 NFS 目录上设置
setgid位,以便继承组所有权。 将
spec.configuration.nodeAgent.supplementalGroups参数和组 ID 添加到DataProtectionApplication清单中,如下例所示:apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication # ... spec: configuration: nodeAgent: enable: true uploaderType: restic supplementalGroups: - <group_id> 1 # ...- 1
- 指定补充组 ID。
-
等待
Resticpod 重启,以便应用更改。
4.14.12.2. 在存储桶被强制后重新创建 Restic Backup CR
如果您为命名空间创建 Restic Backup CR,请清空对象存储的存储桶,然后为同一命名空间重新创建 Backup CR,重新创建的 Backup CR 会失败。
velero pod 日志显示以下错误消息:stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?。
原因
如果 Restic 目录从对象存储中删除,Velero 不会从 ResticRepository 清单重新创建或更新 Restic 存储库。如需更多信息,请参阅 Velero 问题 4421。
解决方案
运行以下命令,从命名空间中删除相关的 Restic 存储库:
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>
在以下错误日志中,
mysql-persistent是有问题的 Restic 存储库。存储库的名称会出现在其说明中。time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.14.12.3. 因为更改了 PSA 策略,Restic 恢复部分在 OCP 4.14 上失败
OpenShift Container Platform 4.14 强制执行一个 pod 安全准入 (PSA) 策略,该策略可能会在 Restic 恢复过程中阻止 pod 的就绪度。
如果创建 Pod 时找不到 SecurityContextConstraints (SCC) 资源,并且 pod 上的 PSA 策略没有设置为满足所需的标准,则 Pod 准入将被拒绝。
造成这个问题的原因是 Velero 资源恢复的顺序。
错误示例
\"level=error\" in line#2273: time=\"2023-06-12T06:50:04Z\" level=error msg=\"error restoring mysql-869f9f44f6-tp5lv: pods\\\ "mysql-869f9f44f6-tp5lv\\\" is forbidden: violates PodSecurity\\\ "restricted:v1.24\\\": privil eged (container \\\"mysql\\\ " must not set securityContext.privileged=true), allowPrivilegeEscalation != false (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.capabilities.drop=[\\\"ALL\\\"]), seccompProfile (pod or containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.seccompProfile.type to \\\ "RuntimeDefault\\\" or \\\"Localhost\\\")\" logSource=\"/remote-source/velero/app/pkg/restore/restore.go:1388\" restore=openshift-adp/todolist-backup-0780518c-08ed-11ee-805c-0a580a80e92c\n velero container contains \"level=error\" in line#2447: time=\"2023-06-12T06:50:05Z\" level=error msg=\"Namespace todolist-mariadb, resource restore error: error restoring pods/todolist-mariadb/mysql-869f9f44f6-tp5lv: pods \\\ "mysql-869f9f44f6-tp5lv\\\" is forbidden: violates PodSecurity \\\"restricted:v1.24\\\": privileged (container \\\ "mysql\\\" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (containers \\\ "restic-wait\\\",\\\"mysql\\\" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.capabilities.drop=[\\\"ALL\\\"]), seccompProfile (pod or containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.seccompProfile.type to \\\ "RuntimeDefault\\\" or \\\"Localhost\\\")\" logSource=\"/remote-source/velero/app/pkg/controller/restore_controller.go:510\" restore=openshift-adp/todolist-backup-0780518c-08ed-11ee-805c-0a580a80e92c\n]",
解决方案
在 DPA 自定义资源 (CR) 中,检查或设置 Velero 服务器上的
restore-resource-priorities字段,以确保在资源列表的pod之前列出securitycontextconstraints:$ oc get dpa -o yaml
DPA CR 示例
# ... configuration: restic: enable: true velero: args: restore-resource-priorities: 'securitycontextconstraints,customresourcedefinitions,namespaces,storageclasses,volumesnapshotclass.snapshot.storage.k8s.io,volumesnapshotcontents.snapshot.storage.k8s.io,volumesnapshots.snapshot.storage.k8s.io,datauploads.velero.io,persistentvolumes,persistentvolumeclaims,serviceaccounts,secrets,configmaps,limitranges,pods,replicasets.apps,clusterclasses.cluster.x-k8s.io,endpoints,services,-,clusterbootstraps.run.tanzu.vmware.com,clusters.cluster.x-k8s.io,clusterresourcesets.addons.cluster.x-k8s.io' 1 defaultPlugins: - gcp - openshift- 1
- 如果您有一个现有的恢复资源优先级列表,请确保将现有列表与完整列表合并。
- 确保应用程序 pod 的安全标准一致(如为部署修复 PodSecurity Admission 警告 中所述)以防止部署警告。如果应用程序与安全标准不一致,无论 SCC 是什么,都可能会出现错误。
这个解决方案是临时的,永久解决方案正在讨论中。
4.14.13. 使用 must-gather 工具
您可以使用 must-gather 工具收集有关 OADP 自定义资源的日志、指标和信息。
must-gather 数据必须附加到所有客户案例。
您可以使用以下数据收集选项运行 must-gather 工具:
-
完全
must-gather数据收集为安装 OADP Operator 的所有命名空间收集 Prometheus metrics、pod 日志和 Velero CR 信息。 -
基本的
must-gather数据收集在特定持续时间内收集 pod 日志和 Velero CR 信息,例如一小时或 24 小时。Prometheus 指标和重复日志不包含在内。 -
使用超时的
must-gather数据收集。如果有许多BackupCR 失败,则数据收集需要很长时间。您可以通过设置超时值来提高性能。 - Prometheus 指标数据转储下载包含 Prometheus 收集的数据的存档文件。
先决条件
-
您必须使用具有
cluster-admin角色的用户登录到 OpenShift Container Platform 集群。 -
已安装 OpenShift CLI (
oc)。 - 您必须使用带有 OADP 1.3 和 OADP 1.4 的 Red Hat Enterprise Linux (RHEL) 9.0。
流程
-
进入存储
must-gather数据的目录。 为以下数据收集选项之一运行
oc adm must-gather命令:完整的
must-gather数据收集,包括 Prometheus 指标:对于 OADP 1.3,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3
对于 OADP 1.4,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4
数据保存为
must-gather/must-gather.tar.gz。您可以将此文件上传到红帽客户门户网站中的支持问题单中。
特定持续时间内,基本
must-gather数据收集功能不进行 Prometheus 指标:对于 OADP 1.3,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 \ -- /usr/bin/gather_<time>_essential 1- 1
- 以小时为单位指定时间。允许的值是
1h、6h、24h、72h或all,例如gather_1h_essential或gather_all_essential。
对于 OADP 1.4,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 \ -- /usr/bin/gather_<time>_essential 1- 1
- 以小时为单位指定时间。允许的值是
1h、6h、24h、72h或all,例如gather_1h_essential或gather_all_essential。
使用超时的
must-gather数据收集:对于 OADP 1.3,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 \ -- /usr/bin/gather_with_timeout <timeout> 1- 1
- 以秒为单位指定超时值。
对于 OADP 1.4,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 \ -- /usr/bin/gather_with_timeout <timeout> 1- 1
- 以秒为单位指定超时值。
Prometheus 指标数据转储:
对于 OADP 1.3,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_metrics_dump
对于 OADP 1.4,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_metrics_dump
此操作可能需要很长时间。数据保存为
must-gather/metrics/prom_data.tar.gz。
其他资源
4.14.13.1. 使用带有不安全 TLS 连接的 must-gather
如果使用自定义 CA 证书,must-gather pod 无法获取 velero logs/describe 的输出。要将 must-gather 工具与不安全的 TLS 连接搭配使用,您可以将 gather_without_tls 标志传递给 must-gather 命令。
流程
使用以下命令,将
gather_without_tls标志(值设为true)传递给must-gather工具:对于 OADP 1.3,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_without_tls <true/false>
对于 OADP 1.4,运行以下命令:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_without_tls <true/false>
默认情况下,这个标志的值设为
false。将值设为true以允许不安全的 TLS 连接。
4.14.13.2. 使用 must-gather 工具合并选项
目前,无法组合 must-gather 脚本,例如指定超时阈值,同时允许不安全的 TLS 连接。在某些情况下,您可以通过在 must-gather 命令行上设置内部变量来解决这个问题,如下例所示:
对于 OADP 1.3:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
对于 OADP 1.4:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
在这些示例中,在运行 gather_with_timeout 脚本前设置 skip_tls 变量。结果是 gather_with_timeout 和 gather_without_tls 的组合。
您可以以这种方式指定的其他变量是如下:
-
logs_since,默认值为72h -
request_timeout,默认值为0s
如果 DataProtectionApplication 自定义资源(CR)配置了 s3Url 和 insecureSkipTLS: true,则 CR 不会因为缺少 CA 证书而收集必要的日志。要收集这些日志,请使用以下选项运行 must-gather 命令:
对于 OADP 1.3:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_without_tls true
对于 OADP 1.4:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_without_tls true
4.14.14. OADP Monitoring
OpenShift Container Platform 提供了一个监控堆栈,允许用户和管理员有效地监控和管理其集群,并监控和分析集群中运行的用户应用程序和服务的工作负载性能,包括在事件发生时收到警报。
4.14.14.1. OADP 监控设置
OADP Operator 利用 OpenShift Monitoring Stack 提供的 OpenShift User Workload Monitoring 从 Velero 服务端点检索指标。监控堆栈允许使用 OpenShift Metrics 查询前端创建用户定义的 Alerting Rules 或查询指标。
启用 User Workload Monitoring 后,可以配置和使用任何与 Prometheus 兼容的第三方 UI (如 Grafana)来视觉化 Velero 指标。
监控指标需要为用户定义的项目启用监控,并创建一个 ServiceMonitor 资源,以便从位于 openshift-adp 命名空间中的已启用的 OADP 服务端点中提取这些指标。
先决条件
-
可以使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。 - 您已创建了集群监控配置映射。
流程
编辑
openshift-monitoring命名空间中的cluster-monitoring-configConfigMap对象:$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
在
data部分的config.yaml字段中添加或启用enableUserWorkload选项:apiVersion: v1 data: config.yaml: | enableUserWorkload: true 1 kind: ConfigMap metadata: # ...- 1
- 添加这个选项或设置为
true
通过检查以下组件是否在
openshift-user-workload-monitoring命名空间中运行,等待较短的时间段来验证 User Workload Monitoring Setup:$ oc get pods -n openshift-user-workload-monitoring
输出示例
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32s
验证
openshift-user-workload-monitoring中是否存在user-workload-monitoring-configConfigMap。如果存在,请跳过这个过程中的剩余步骤。$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring
输出示例
Error from server (NotFound): configmaps "user-workload-monitoring-config" not found
为 User Workload Monitoring 创建一个
user-workload-monitoring-configConfigMap对象,并将它保存为2_configure_user_workload_monitoring.yaml文件:输出示例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |
应用
2_configure_user_workload_monitoring.yaml文件:$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.14.14.2. 创建 OADP 服务监控器
OADP 提供了一个 openshift-adp-velero-metrics-svc 服务,它会在配置 DPA 时创建。用户工作负载监控使用的服务监控器必须指向定义的服务。
运行以下命令来获取该服务的详情:
流程
确保
openshift-adp-velero-metrics-svc服务存在。它应当包含app.kubernetes.io/name=velero标签,这些标签将用作ServiceMonitor对象的选择器。$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero
输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h
创建一个与现有 service 标签匹配的
ServiceMonitorYAML 文件,并将文件保存为3_create_oadp_service_monitor.yaml。服务监控器在openshift-adp命名空间中创建,其中openshift-adp-velero-metrics-svc服务所在的位置。ServiceMonitor对象示例apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"应用
3_create_oadp_service_monitor.yaml文件:$ oc apply -f 3_create_oadp_service_monitor.yaml
输出示例
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
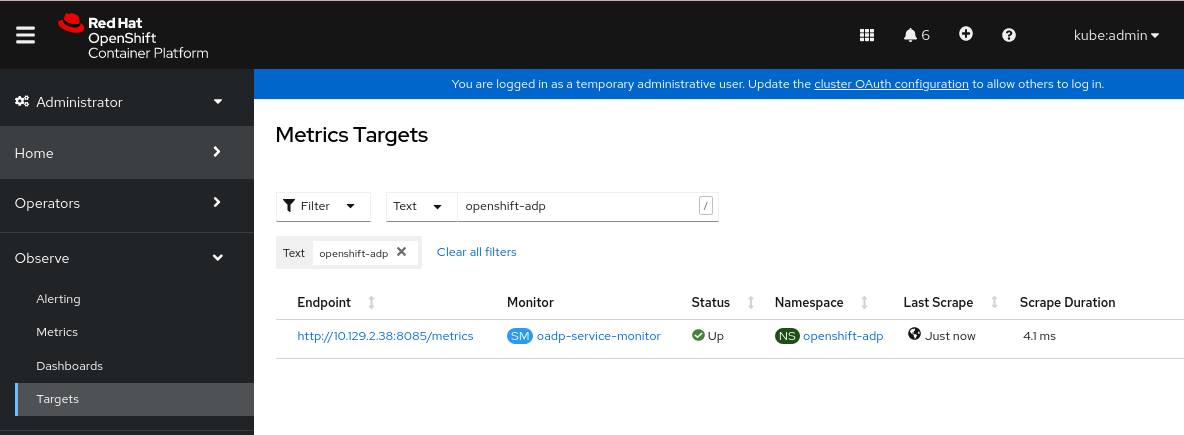
验证
使用 OpenShift Container Platform Web 控制台的 Administrator 视角确认新服务监控器处于 Up 状态:
-
进入到 Observe
Targets 页面。 -
确保没有选择 Filter,或选择了 User source,并在
Text搜索字段中输入openshift-adp。 验证服务监控器的 Status 的状态是否为 Up。
图 4.1. OADP 指标目标
-
进入到 Observe
4.14.14.3. 创建警报规则
OpenShift Container Platform 监控堆栈允许接收使用 Alerting Rules 配置的 Alerts。要为 OADP 项目创建 Alerting 规则,请使用用户工作负载监控提取的其中一个指标。
流程
使用示例
OADPBackupFailing警报创建一个PrometheusRuleYAML 文件,并将其保存为4_create_oadp_alert_rule.yaml。OADPBackupFailing警报示例apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warning在本例中,Alert 在以下情况下显示:
- 在最后 2 个小时内增加了新的故障备份(大于 0),且状态至少维持了 5 分钟。
-
如果第一次增加的时间小于 5 分钟,则 Alert 将处于
Pending状态,之后它将进入Firing状态。
应用
4_create_oadp_alert_rule.yaml文件,该文件在openshift-adp命名空间中创建PrometheusRule对象:$ oc apply -f 4_create_oadp_alert_rule.yaml
输出示例
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
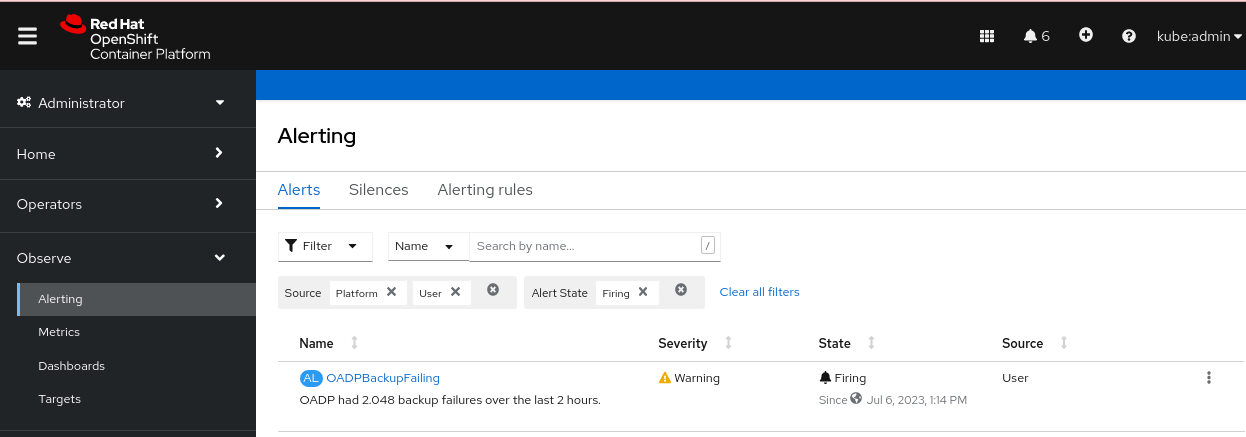
验证
在触发 Alert 后,您可以使用以下方法查看它:
- 在 Developer 视角中,选择 Observe 菜单。
在 Observe
Alerting 菜单下的 Administrator 视角中,在 Filter 框中选择 User。否则,默认只会显示 Platform Alerts。 图 4.2. OADP 备份失败警报
其他资源
4.14.14.4. 可用指标列表
这些是 OADP 提供的指标列表,以及它们的 类型。
| 指标名称 | 描述 | 类型 |
|---|---|---|
|
| 从缓存检索的字节数 | 计数 |
|
| 从缓存检索内容的次数 | 计数 |
|
| 从缓存中读取不正确的内容的次数 | 计数 |
|
| 没有在缓存中找到内容并获取它的次数 | 计数 |
|
| 从底层存储检索的字节数 | 计数 |
|
| 在底层存储中无法找到内容的次数 | 计数 |
|
| 无法保存到缓存中的次数 | 计数 |
|
|
使用 | 计数 |
|
|
| 计数 |
|
|
调用 | 计数 |
|
|
调用 | 计数 |
|
|
传递给 | 计数 |
|
|
| 计数 |
|
| 试图备份的总数 | 计数 |
|
| 试图备份删除的总数 | 计数 |
|
| 删除失败的备份总数 | 计数 |
|
| 成功删除备份的总数 | 计数 |
|
| 完成备份所需的时间,以秒为单位 | Histogram |
|
| 失败备份的总数 | 计数 |
|
| 备份过程中遇到的错误总数 | 量表 |
|
| 备份的项目总数 | 量表 |
|
| 备份的最后状态。值 1 代表成功,0。 | 量表 |
|
| 备份最后一次运行成功的时间,Unix 时间戳(以秒为单位) | 量表 |
|
| 部分失败的备份总数 | 计数 |
|
| 成功备份的总数 | 计数 |
|
| 备份的大小,以字节为单位 | 量表 |
|
| 当前存在的备份数量 | 量表 |
|
| 验证失败的备份总数 | 计数 |
|
| 警告备份的总数 | 计数 |
|
| CSI 试图卷快照的总数 | 计数 |
|
| CSI 失败卷快照的总数 | 计数 |
|
| CSI 成功卷快照总数 | 计数 |
|
| 尝试恢复的总数 | 计数 |
|
| 恢复的失败总数 | 计数 |
|
| 恢复部分失败的总数 | 计数 |
|
| 成功恢复的总数 | 计数 |
|
| 当前存在的恢复数量 | 量表 |
|
| 恢复失败验证的总数 | 计数 |
|
| 尝试的卷快照总数 | 计数 |
|
| 失败的卷快照总数 | 计数 |
|
| 成功卷快照的总数 | 计数 |
4.14.14.5. 使用 Observe UI 查看指标
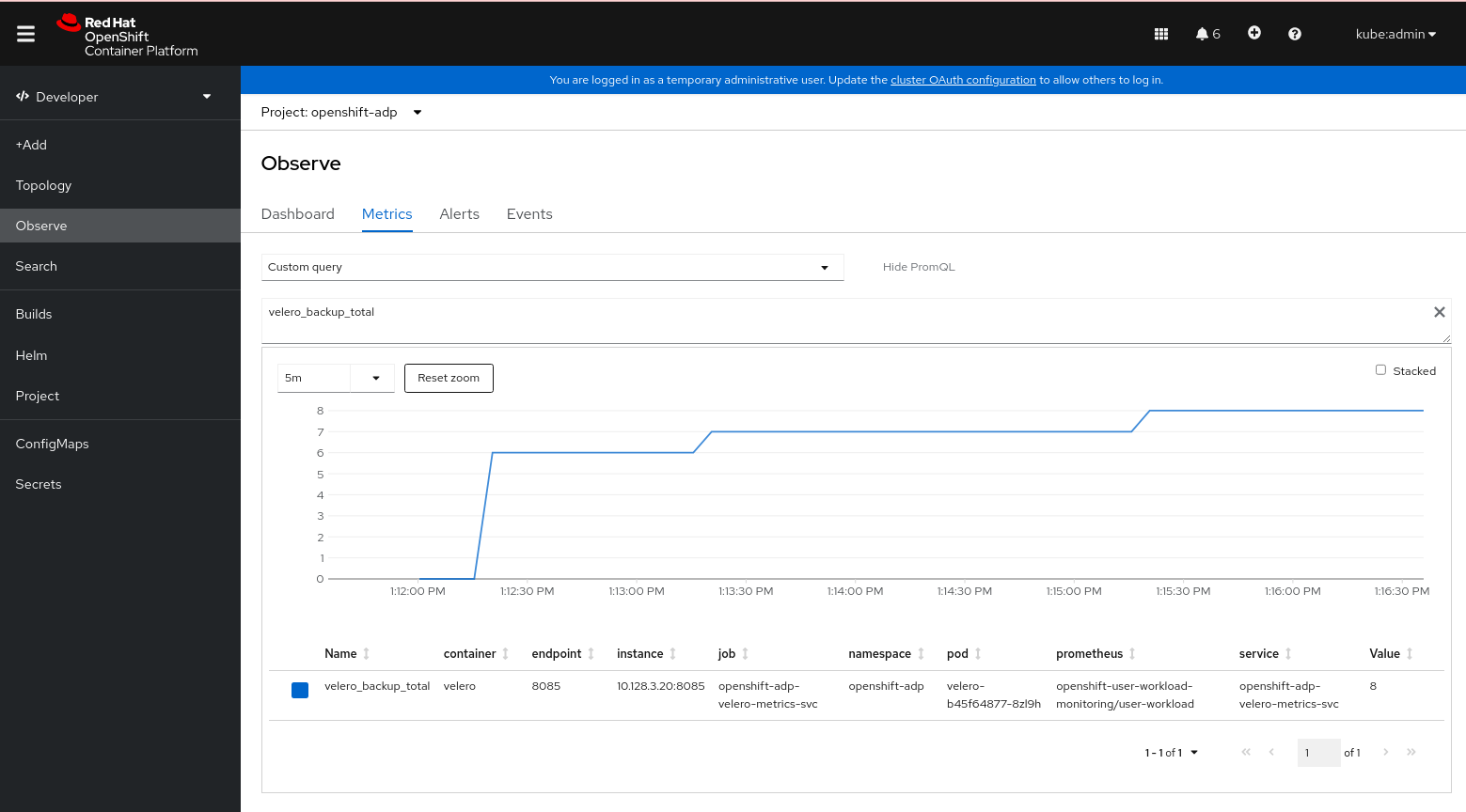
您可以从 Administrator 或 Developer 视角查看 OpenShift Container Platform Web 控制台中的指标,该视角必须有权访问 openshift-adp 项目。
流程
进入到 Observe
Metrics 页面: 如果使用 Developer 视角,请按照以下步骤执行:
- 选择 Custom query,或者点 Show PromQL 链接。
- 输入查询并点 Enter。
如果使用 Administrator 视角,请在文本字段中输入表达式,然后选择 Run Queries。
图 4.3. OADP 指标查询