1.4. 了解 OpenShift Container Platform 更新持续时间
OpenShift Container Platform 更新持续时间因部署拓扑而异。这个页可帮助您了解影响更新持续时间的因素,并估算集群更新在环境中所需的时间。
1.4.1. 影响更新持续时间的因素
以下因素可能会影响您的集群更新持续时间:
通过 Machine Config Operator (MCO) 将计算节点重启到新机器配置
机器配置池中的
MaxUnavailable的值警告对于 OpenShift Container Platform 中的所有机器配置池,
maxUnavailable的默认设置是1。建议您不要更改这个值,且一次只更新一个 control plane 节点。对于 control plane 池,请不要将这个值改为3。- pod 中断预算 (PDB) 中设定的最小副本数或百分比
- 集群中的节点数
- 集群节点的健康状况
1.4.2. 集群更新阶段
在 OpenShift Container Platform 中,集群更新分为两个阶段:
- Cluster Version Operator (CVO) 目标更新有效负载部署
- Machine Config Operator (MCO) 节点更新
1.4.2.1. Cluster Version Operator 目标更新有效负载部署
Cluster Version Operator (CVO) 检索目标更新发行镜像并应用到集群。作为 pod 运行的所有组件都会在这个阶段更新,主机组件则由 Machine Config Operator (MCO) 更新。这个过程可能需要 60 到 120 分钟。
更新的 CVO 阶段不会重启节点。
1.4.2.2. Machine Config Operator 节点更新
Machine Config Operator (MCO) 将新机器配置应用到每个 control plane 和计算节点。在此过程中,MCO 在集群的每个节点中执行以下操作:
- cordon 和 drain 所有节点
- 更新操作系统 (OS)
- 重新引导节点
- 取消协调所有节点并在节点上调度工作负载
当节点被封锁时,工作负载无法调度到其中。
完成此过程的时间取决于多个因素,包括节点和基础架构配置。此过程可能需要 5 分钟或更长时间来完成每个节点。
除了 MCO 外,您应该考虑以下参数的影响:
- control plane 节点更新持续时间是可预测的,通常比计算节点更短,因为 control plane 工作负载出于安全更新和快速排空进行了调优。
-
您可以通过将
maxUnavailable字段设置为在 Machine Config Pool (MCP) 中大于1来并行更新计算节点。MCO 会处理maxUnavailable中指定的节点数量,并标记它们无法进行更新。 -
当您在 MCP 上增加
maxUnavailable时,它可以帮助池更快地更新。但是,如果maxUnavailable太高,且同时处理几个节点,pod 中断预算 (PDB) 保护工作负载可能无法排空,因为无法找到调度的节点来运行副本。如果您为 MCP 增加maxUnavailable,请确保仍然有足够的可调度节点来允许 PDB 保护的工作负载排空。 在开始更新前,您必须确保所有节点都可用。任何不可用的节点都可能会影响更新持续时间,因为节点不可用会影响
maxUnavailable和 pod 中断预算。要从终端中检查节点状态,请运行以下命令:
$ oc get node输出示例
NAME STATUS ROLES AGE VERSION ip-10-0-137-31.us-east-2.compute.internal Ready,SchedulingDisabled worker 12d v1.23.5+3afdacb ip-10-0-151-208.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-176-138.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-183-194.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb ip-10-0-204-102.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-207-224.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb如果节点的状态为
NotReady或SchedulingDisabled,则该节点不可用,且这会影响更新持续时间。您可以通过展开 Compute
Nodes 从 web 控制台中的 Administrator 视角检查节点的状态。
1.4.2.3. 集群 Operator 的更新持续时间示例
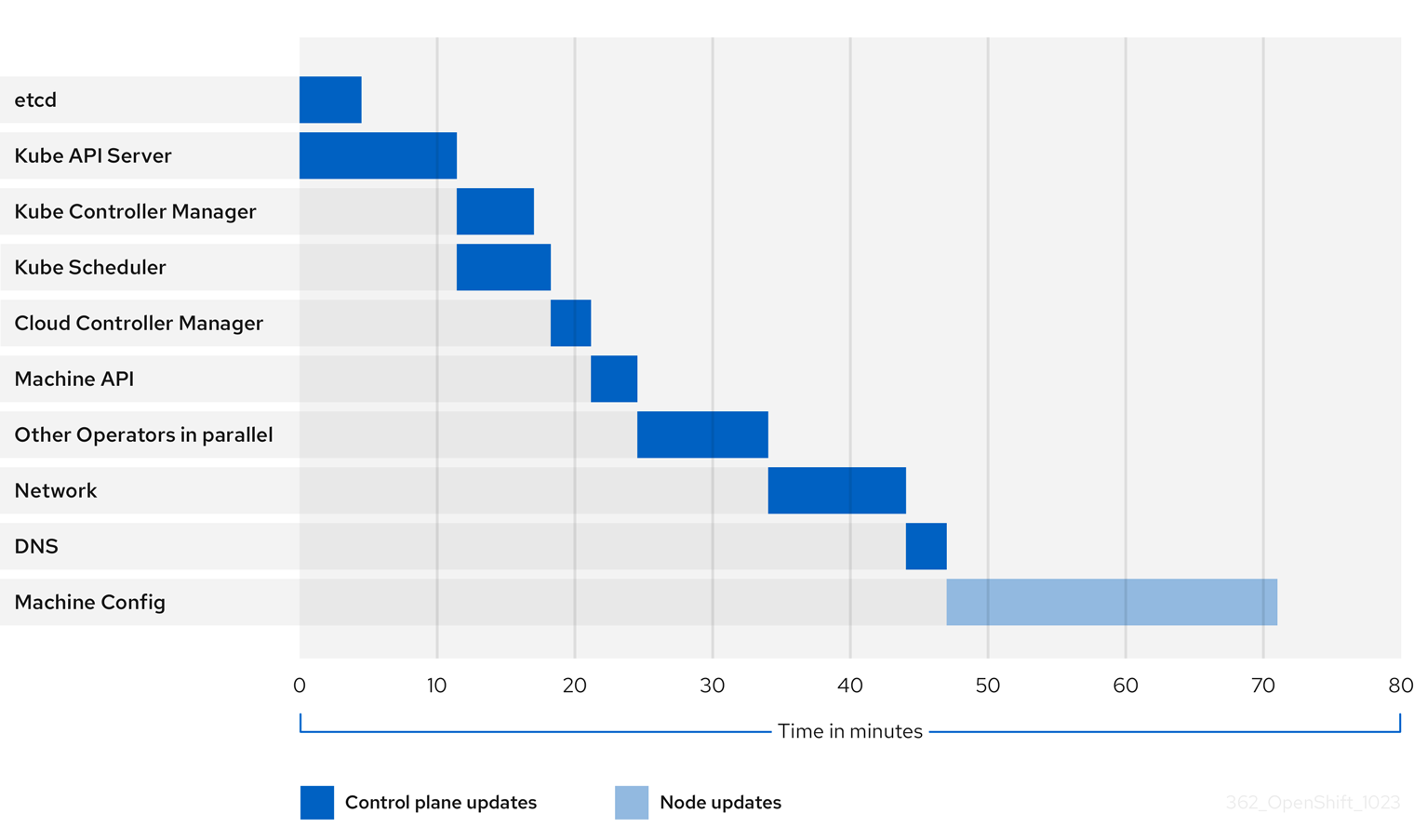
上图显示了集群 Operator 可能需要升级到其新版本的时间示例。这个示例基于一个三节点 AWS OVN 集群,它有一个健康的计算 MachineConfigPool,没有需要很长时间才能排空的工作负载,从 4.13 升级到 4.14。
- 集群及其 Operator 的特定更新持续时间可能会因几个集群特征而有所不同,如目标版本、节点数量以及调度到节点的工作负载类型。
- 有些 Operator (如 Cluster Version Operator)会在短时间内更新自己。这些 Operator 可以在图中省略,或者包含在标记为"其他 Operator 并行"的更广泛的 Operator 组中。
每个集群 Operator 的特征会影响到更新自身所需的时间。例如,在这个示例中,Kube API Server Operator 需要超过十一分钟才能更新,因为 kube-apiserver 提供了安全终止支持,这意味着现有的 in-flight 请求可以安全完成。这可能会导致关闭 kube-apiserver 的时间更长。对于这个 Operator,会牺牲更新速度,以帮助防止并限制更新期间对集群功能的中断。
影响 Operator 更新持续时间的另一个特征是 Operator 是否使用 DaemonSet。Network 和 DNS Operator 使用 full-cluster DaemonSet,这可能需要一些时间才能推出版本更改,这是这些 Operator 更新自身需要更长的原因之一。
有些 Operator 的更新持续时间主要取决于集群本身的特性。例如,Machine Config Operator 更新对集群中的每个节点应用机器配置更改。与具有较少节点的集群相比,Machine Config Operator 的集群的更新持续时间会更长。
每个集群 Operator 都会分配一个阶段,可以对其进行更新。同一阶段中的 Operator 可以同时更新,给定阶段中的 Operator 将无法开始更新,直到所有之前的阶段都完成为止。如需更多信息,请参阅"添加资源"部分中的"了解更新期间如何应用清单"。
1.4.3. 估算集群更新时间
类似集群的历史更新持续时间为您提供了未来集群更新的最佳估算。但是,如果历史数据不可用,您可以使用以下约定来估算集群更新时间:
Cluster update time = CVO target update payload deployment time + (# node update iterations x MCO node update time)
节点更新迭代由并行更新的一个或多个节点组成。control plane 节点总会与计算节点并行更新。另外,根据 maxUnavailable 值可以并行更新一个或多个计算节点。
对于 OpenShift Container Platform 中的所有机器配置池,maxUnavailable 的默认设置是 1。建议您不要更改这个值,且一次只更新一个 control plane 节点。对于 control plane 池,请不要将这个值改为 3。
例如,要估算更新时间,请考虑一个具有三个 control plane 节点的 OpenShift Container Platform 集群,以及每个主机需要大约 5 分钟才能重启。
重启特定节点所需的时间有很大不同。在云实例中,重新启动可能需要大约 1 到 2 分钟,而在物理主机中,重新引导可能需要超过 15 分钟。
场景 1
当您将 control plane 和计算节点机器配置池 (MCP) 的 maxUnavailable 设置为 1 时,所有 6 个计算节点会在每个迭代中逐一进行更新。
Cluster update time = 60 + (6 x 5) = 90 minutes场景 2
当您为计算节点 MCP 将 maxUnavailable 设置为 2 时,两个计算节点会在每个迭代中并行更新。因此,它需要三个迭代来更新所有节点。
Cluster update time = 60 + (3 x 5) = 75 minutes
对于 OpenShift Container Platform 中的所有 MCP,maxUnavailable 的默认设置为 1。建议您不要更改 control plane MCP 中的 maxUnavailable。
1.4.4. Red Hat Enterprise Linux (RHEL) 计算节点
Red Hat Enterprise Linux (RHEL) 计算节点需要额外使用 openshift-ansible 来更新节点二进制组件。更新 RHEL 计算节点的实际时间不应与 Red Hat Enterprise Linux CoreOS (RHCOS) 计算节点有很大不同。