2.4. Gestionnaire du cycle de vie de l’opérateur (OLM)
2.4.1. Concepts et ressources du gestionnaire du cycle de vie de l’opérateur
Ce guide donne un aperçu des concepts qui pilotent le gestionnaire de cycle de vie de l’opérateur (OLM) dans Red Hat OpenShift Service sur AWS.
2.4.1.1. En quoi consiste le gestionnaire de cycle de vie de l’opérateur (OLM) Classic?
L’opérateur Lifecycle Manager (OLM) Classic aide les utilisateurs à installer, mettre à jour et gérer le cycle de vie des applications natives Kubernetes (Operators) et de leurs services associés qui s’exécutent sur leur service OpenShift Red Hat sur les clusters AWS. Il s’inscrit dans le cadre de l’opérateur, une boîte à outils open source conçue pour gérer les opérateurs de manière efficace, automatisée et évolutive.
Figure 2.2. Flux de travail OLM (Classic)

Le service OLM fonctionne par défaut dans Red Hat OpenShift Service sur AWS 4, qui aide les administrateurs avec le rôle d’administrateur dédié dans l’installation, la mise à niveau et l’octroi d’un accès aux opérateurs fonctionnant sur leur cluster. Le service OpenShift Red Hat sur la console web AWS fournit des écrans de gestion aux administrateurs dédiés pour installer les opérateurs, ainsi que l’accès à des projets spécifiques pour utiliser le catalogue des opérateurs disponibles sur le cluster.
En ce qui concerne les développeurs, une expérience en libre-service permet de fournir et de configurer des instances de bases de données, de surveillance et de services de big data sans avoir à être des experts en la matière, car l’opérateur dispose de ces connaissances.
2.4.1.2. Les ressources OLM
Les définitions de ressources personnalisées (DCR) suivantes sont définies et gérées par Operator Lifecycle Manager (OLM):
| A) Ressources | Court nom | Description |
|---|---|---|
| ClusterServiceVersion (CSV) |
| Les métadonnées de l’application. Exemple : nom, version, icône, ressources requises. |
|
|
| Dépôt de CSV, CRD et packages qui définissent une application. |
|
|
| Garde les CSVs à jour en suivant un canal dans un paquet. |
|
|
| Liste calculée des ressources à créer pour installer ou mettre à jour automatiquement un CSV. |
|
|
| Configure tous les opérateurs déployés dans le même espace de noms que l’objet OperatorGroup pour surveiller leur ressource personnalisée (CR) dans une liste d’espaces de noms ou à l’échelle du cluster. |
|
| - | Crée un canal de communication entre OLM et un opérateur qu’il gère. Les opérateurs peuvent écrire dans le tableau Status.Conditions pour communiquer des états complexes à OLM. |
2.4.1.2.1. Cluster de service version
La version de service cluster (CSV) représente une version spécifique d’un opérateur en cours d’exécution sur un Red Hat OpenShift Service sur le cluster AWS. Il s’agit d’un manifeste YAML créé à partir des métadonnées de l’opérateur qui aide le gestionnaire de cycle de vie de l’opérateur (OLM) à exécuter l’opérateur dans le cluster.
L’OLM exige que ces métadonnées concernant un opérateur puissent être maintenues en toute sécurité sur un cluster et pour fournir des informations sur la façon dont les mises à jour devraient être appliquées au fur et à mesure que de nouvelles versions de l’opérateur sont publiées. Ceci est similaire au logiciel d’emballage pour un système d’exploitation traditionnel; pensez à l’étape d’emballage pour OLM comme le stade auquel vous faites votre rpm, deb ou apk bundle.
Le CSV comprend les métadonnées qui accompagnent une image de conteneur d’opérateur, utilisée pour remplir les interfaces utilisateur avec des informations telles que son nom, sa version, sa description, ses étiquettes, son lien de dépôt et son logo.
Le CSV est également une source d’informations techniques nécessaires à l’exécution de l’opérateur, telles que les ressources personnalisées (CR) dont il gère ou dépend, les règles RBAC, les exigences en cluster et les stratégies d’installation. Ces informations indiquent à OLM comment créer les ressources requises et configurer l’opérateur en tant que déploiement.
2.4.1.2.2. Catalogue source
La source du catalogue représente un magasin de métadonnées, généralement en faisant référence à une image d’index stockée dans un registre de conteneurs. Le gestionnaire de cycle de vie de l’opérateur (OLM) interroge les sources de catalogue pour découvrir et installer les opérateurs et leurs dépendances. OperatorHub dans le Red Hat OpenShift Service sur la console web AWS affiche également les opérateurs fournis par les sources du catalogue.
Les administrateurs de clusters peuvent afficher la liste complète des opérateurs fournis par une source de catalogue activée sur un cluster à l’aide de la page Administration
La spécification d’un objet CatalogSource indique comment construire un pod ou comment communiquer avec un service qui sert l’API GRPC du Registre de l’opérateur.
Exemple 2.9. Exemple d’objet CatalogSource
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
generation: 1
name: example-catalog
namespace: openshift-marketplace
annotations:
olm.catalogImageTemplate:
"quay.io/example-org/example-catalog:v{kube_major_version}.{kube_minor_version}.{kube_patch_version}"
spec:
displayName: Example Catalog
image: quay.io/example-org/example-catalog:v1
priority: -400
publisher: Example Org
sourceType: grpc
grpcPodConfig:
securityContextConfig: <security_mode>
nodeSelector:
custom_label: <label>
priorityClassName: system-cluster-critical
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
updateStrategy:
registryPoll:
interval: 30m0s
status:
connectionState:
address: example-catalog.openshift-marketplace.svc:50051
lastConnect: 2021-08-26T18:14:31Z
lastObservedState: READY
latestImageRegistryPoll: 2021-08-26T18:46:25Z
registryService:
createdAt: 2021-08-26T16:16:37Z
port: 50051
protocol: grpc
serviceName: example-catalog
serviceNamespace: openshift-marketplace- 1
- Le nom de l’objet CatalogSource. Cette valeur est également utilisée dans le nom du pod associé qui est créé dans l’espace de noms demandé.
- 2
- Espace de noms pour créer le catalogue. Afin de rendre le catalogue disponible à l’échelle du cluster dans tous les espaces de noms, définissez cette valeur sur openshift-marketplace. Les sources de catalogue Red Hat par défaut utilisent également l’espace de noms openshift-marketplace. Dans le cas contraire, définissez la valeur d’un espace de noms spécifique pour rendre l’opérateur disponible uniquement dans cet espace de noms.
- 3
- Facultatif: Pour éviter les mises à niveau de cluster potentiellement laissant les installations de l’opérateur dans un état non pris en charge ou sans chemin de mise à jour continu, vous pouvez activer la modification automatique de la version d’image d’index de votre catalogue d’opérateur dans le cadre des mises à niveau de cluster.
Définissez l’annotation olm.catalogImageTemplate sur votre nom d’image d’index et utilisez une ou plusieurs des variables de version du cluster Kubernetes comme indiqué lors de la construction du modèle pour la balise d’image. L’annotation écrase le champ spec.image au moment de l’exécution. Consultez la section « Modèle d’image pour les sources de catalogue personnalisées » pour plus de détails.
- 4
- Afficher le nom du catalogue dans la console Web et CLI.
- 5
- Index de l’image pour le catalogue. En option, peut être omis lors de l’utilisation de l’annotation olm.catalogImageTemplate, qui définit la spécification de traction au moment de l’exécution.
- 6
- Le poids pour la source du catalogue. L’OMM utilise le poids pour la priorisation lors de la résolution de dépendance. Le poids plus élevé indique que le catalogue est préféré aux catalogues moins pondérés.
- 7
- Les types de sources comprennent les éléments suivants:
- GRPC avec une référence d’image: OLM tire l’image et exécute le pod, qui est censé servir une API conforme.
- GRPC avec un champ d’adresse: OLM tente de contacter l’API gRPC à l’adresse donnée. Cela ne devrait pas être utilisé dans la plupart des cas.
- ConfigMap: OLM analyse la configuration des données cartographiques et exécute un pod qui peut servir l’API gRPC.
- 8
- Indiquez la valeur de l’héritage ou de la restriction. Lorsque le champ n’est pas défini, la valeur par défaut est héritée. Dans un futur service Red Hat OpenShift sur AWS, il est prévu que la valeur par défaut soit limitée. Dans le cas où votre catalogue ne peut pas fonctionner avec des autorisations restreintes, il est recommandé de définir manuellement ce champ sur l’héritage.
- 9
- Facultatif: Pour les sources de catalogue de type grpc, remplace le sélecteur de nœud par défaut pour le pod servant le contenu dans spec.image, si défini.
- 10
- Facultatif: Pour les sources de catalogue de type grpc, remplace le nom de classe de priorité par défaut pour le pod servant le contenu dans spec.image, si défini. Kubernetes fournit par défaut des classes de priorité critiques et critiques du cluster système. Définir le champ à vide ("") attribue à la pod la priorité par défaut. D’autres classes prioritaires peuvent être définies manuellement.
- 11
- Facultatif: Pour les sources de catalogue de type grpc, outrepasse les tolérances par défaut pour le pod servant le contenu dans spec.image, si défini.
- 12
- Vérifiez automatiquement les nouvelles versions à un intervalle donné pour rester à jour.
- 13
- Dernier état observé de la connexion au catalogue. À titre d’exemple:
- LIRE: Une connexion est établie avec succès.
- CONNECTING : Une connexion tente d’établir.
- FAILURE TRANSIENTE : Un problème temporaire s’est produit lors de la tentative d’établir une connexion, comme un délai d’attente. L’état finira par revenir à CONNECTING et essayer à nouveau.
Consultez les états de connectivité dans la documentation du GRPC pour plus de détails.
- 14
- La dernière fois que le registre conteneur stockant l’image du catalogue a été sondé pour s’assurer que l’image est à jour.
- 15
- Informations d’état pour le service de registre de l’opérateur du catalogue.
Faire référence au nom d’un objet CatalogSource dans un abonnement indique à OLM où chercher pour trouver un opérateur demandé:
Exemple 2.10. Exemple Objet d’abonnement faisant référence à une source de catalogue
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplace2.4.1.2.2.1. Modèle d’image pour les sources de catalogue personnalisées
La compatibilité de l’opérateur avec le cluster sous-jacent peut être exprimée par une source de catalogue de différentes manières. L’une des façons, qui est utilisée pour les sources de catalogue par défaut de Red Hat, est d’identifier les balises d’image pour les images d’index qui sont spécifiquement créées pour une version de la plate-forme particulière, par exemple Red Hat OpenShift Service sur AWS 4.
Lors d’une mise à niveau de cluster, la balise d’image d’index pour les sources de catalogue par défaut Red Hat est mise à jour automatiquement par l’opérateur de versions de cluster (CVO) de sorte que le gestionnaire de cycle de vie de l’opérateur (OLM) tire la version mise à jour du catalogue. Lors d’une mise à jour de Red Hat OpenShift Service sur AWS 4.17 vers 4, le champ spec.image dans l’objet CatalogSource pour le catalogue redhat-operators est mis à jour à partir de:
registry.redhat.io/redhat/redhat-operator-index:v4.18à:
registry.redhat.io/redhat/redhat-operator-index:v4.18Cependant, le CVO ne met pas automatiquement à jour les balises d’image pour les catalogues personnalisés. Afin de s’assurer que les utilisateurs disposent d’une installation d’opérateur compatible et prise en charge après une mise à niveau de cluster, les catalogues personnalisés doivent également être mis à jour pour faire référence à une image d’index mise à jour.
À partir de Red Hat OpenShift Service sur AWS 4.9, les administrateurs de clusters peuvent ajouter l’annotation olm.catalogImageTemplate dans l’objet CatalogSource pour les catalogues personnalisés à une référence d’image qui inclut un modèle. Les variables de version Kubernetes suivantes sont prises en charge pour être utilisées dans le modèle:
-
kube_major_version -
kube_minor_version -
kube_patch_version
Il faut spécifier la version du cluster Kubernetes et non un service Red Hat OpenShift sur la version du cluster AWS, car ce dernier n’est pas actuellement disponible pour templating.
À condition que vous ayez créé et poussé une image d’index avec une balise spécifiant la version mise à jour de Kubernetes, le réglage de cette annotation permet de modifier automatiquement les versions d’image d’index dans les catalogues personnalisés après une mise à niveau de cluster. La valeur d’annotation est utilisée pour définir ou mettre à jour la référence d’image dans le champ spec.image de l’objet CatalogSource. Cela permet d’éviter les mises à niveau de clusters laissant les installations de l’opérateur dans des états non pris en charge ou sans chemin de mise à jour continue.
Assurez-vous que l’image d’index avec la balise mise à jour, quel que soit le registre dans lequel elle est stockée, est accessible par le cluster au moment de la mise à jour du cluster.
Exemple 2.11. Exemple de source de catalogue avec un modèle d’image
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
generation: 1
name: example-catalog
namespace: openshift-marketplace
annotations:
olm.catalogImageTemplate:
"quay.io/example-org/example-catalog:v{kube_major_version}.{kube_minor_version}"
spec:
displayName: Example Catalog
image: quay.io/example-org/example-catalog:v1.31
priority: -400
publisher: Example OrgLorsque le champ spec.image et l’annotation olm.catalogImageTemplate sont toutes deux définies, le champ spec.image est écrasé par la valeur résolue de l’annotation. Lorsque l’annotation ne se résout pas à une spécification de traction utilisable, la source du catalogue revient à la valeur spec.image définie.
Lorsque le champ spec.image n’est pas défini et que l’annotation ne se résout pas à une spécification de traction utilisable, OLM arrête la réconciliation de la source du catalogue et le place dans une condition d’erreur lisible par l’homme.
Dans le cas d’un Red Hat OpenShift Service sur AWS 4 cluster, qui utilise Kubernetes 1.31, l’annotation olm.catalogImageTemplate dans l’exemple précédent résout la référence d’image suivante:
quay.io/example-org/example-catalog:v1.31En ce qui concerne les futures versions de Red Hat OpenShift Service sur AWS, vous pouvez créer des images d’index mises à jour pour vos catalogues personnalisés qui ciblent la version ultérieure de Kubernetes qui est utilisée par la version ultérieure de Red Hat OpenShift sur AWS. Avec l’annotation olm.catalogImageTemplate définie avant la mise à niveau, la mise à niveau du cluster vers le plus tard Red Hat OpenShift Service sur la version AWS mettrait alors automatiquement à jour l’image de l’index du catalogue.
2.4.1.2.2.2. Exigences en matière de santé du catalogue
Les catalogues d’opérateurs sur un cluster sont interchangeables du point de vue de la résolution d’installation; un objet d’abonnement peut faire référence à un catalogue spécifique, mais les dépendances sont résolues à l’aide de tous les catalogues du cluster.
À titre d’exemple, si Catalog A est malsain, un référencement d’abonnement Catalog A pourrait résoudre une dépendance dans Catalog B, que l’administrateur du cluster n’aurait peut-être pas attendu, car B avait normalement une priorité de catalogue inférieure à A.
En conséquence, OLM exige que tous les catalogues avec un espace de noms global donné (par exemple, l’espace de noms openshift-marketplace par défaut ou un espace de noms global personnalisé) soient sains. Lorsqu’un catalogue est malsain, toutes les opérations d’installation ou de mise à jour de l’opérateur au sein de son espace de noms global partagé échoueront avec une condition CatalogSourcesUnsanté. Lorsque ces opérations étaient autorisées dans un état malsain, OLM pourrait prendre des décisions de résolution et d’installation qui étaient inattendues pour l’administrateur du cluster.
En tant qu’administrateur de cluster, si vous observez un catalogue malsain et que vous souhaitez considérer le catalogue comme invalide et reprendre les installations de l’opérateur, consultez les sections "Supprimer les catalogues personnalisés" ou "Désactiver les sources de catalogue OperatorHub par défaut" pour obtenir des informations sur la suppression du catalogue malsain.
2.4.1.2.3. Abonnement
L’abonnement, défini par un objet Abonnement, représente une intention d’installer un Opérateur. C’est la ressource personnalisée qui relie un opérateur à une source de catalogue.
Les abonnements décrivent le canal d’un package Opérateur auquel s’abonner et s’il y a lieu d’effectuer des mises à jour automatiquement ou manuellement. En cas de configuration automatique, l’abonnement garantit que le gestionnaire de cycle de vie de l’opérateur (OLM) gère et met à niveau l’opérateur pour s’assurer que la dernière version est toujours en cours d’exécution dans le cluster.
Exemple d’objet d’abonnement
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplaceCet objet d’abonnement définit le nom et l’espace de noms de l’opérateur, ainsi que le catalogue à partir duquel les données de l’opérateur peuvent être trouvées. Le canal, tel que alpha, bêta ou stable, aide à déterminer quel flux d’opérateur doit être installé à partir de la source du catalogue.
Les noms des canaux dans un abonnement peuvent différer entre les opérateurs, mais le schéma de dénomination doit suivre une convention commune au sein d’un opérateur donné. À titre d’exemple, les noms de canaux peuvent suivre un flux de mise à jour de version mineure pour l’application fournie par l’opérateur (1.2, 1.3) ou une fréquence de libération (stable, rapide).
En plus d’être facilement visible à partir du service Red Hat OpenShift sur la console web AWS, il est possible d’identifier quand il y a une nouvelle version d’un opérateur disponible en inspectant l’état de l’abonnement connexe. La valeur associée au champ CurrentCSV est la version la plus récente connue de OLM, et installéeCSV est la version installée sur le cluster.
2.4.1.2.4. Installer le plan
Le plan d’installation, défini par un objet InstallPlan, décrit un ensemble de ressources créées par Operator Lifecycle Manager (OLM) pour installer ou mettre à niveau une version spécifique d’un opérateur. La version est définie par une version de service cluster (CSV).
L’installation d’un opérateur, d’un administrateur de cluster ou d’un utilisateur qui a obtenu les autorisations d’installation de l’opérateur doit d’abord créer un objet d’abonnement. L’abonnement représente l’intention de s’abonner à un flux de versions disponibles d’un opérateur à partir d’une source de catalogue. L’abonnement crée ensuite un objet InstallPlan pour faciliter l’installation des ressources pour l’opérateur.
Le plan d’installation doit ensuite être approuvé selon l’une des stratégies d’approbation suivantes:
- Lorsque le champ spec.installPlanApproval de l’abonnement est défini sur Automatique, le plan d’installation est approuvé automatiquement.
- Lorsque le champ spec.installPlanApproval de l’abonnement est défini sur Manuel, le plan d’installation doit être approuvé manuellement par un administrateur de cluster ou un utilisateur avec les autorisations appropriées.
Après l’approbation du plan d’installation, OLM crée les ressources spécifiées et installe l’opérateur dans l’espace de noms spécifié par l’abonnement.
Exemple 2.12. Exemple d’objet InstallPlan
apiVersion: operators.coreos.com/v1alpha1
kind: InstallPlan
metadata:
name: install-abcde
namespace: operators
spec:
approval: Automatic
approved: true
clusterServiceVersionNames:
- my-operator.v1.0.1
generation: 1
status:
...
catalogSources: []
conditions:
- lastTransitionTime: '2021-01-01T20:17:27Z'
lastUpdateTime: '2021-01-01T20:17:27Z'
status: 'True'
type: Installed
phase: Complete
plan:
- resolving: my-operator.v1.0.1
resource:
group: operators.coreos.com
kind: ClusterServiceVersion
manifest: >-
...
name: my-operator.v1.0.1
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1alpha1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: apiextensions.k8s.io
kind: CustomResourceDefinition
manifest: >-
...
name: webservers.web.servers.org
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1beta1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: ''
kind: ServiceAccount
manifest: >-
...
name: my-operator
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: Role
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: RoleBinding
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
...2.4.1.2.5. Groupes d’opérateurs
Le groupe d’opérateurs, défini par la ressource OperatorGroup, fournit une configuration multilocataires aux Opérateurs installés par OLM. Le groupe d’opérateur sélectionne les espaces de noms cibles dans lesquels générer l’accès RBAC requis pour ses opérateurs membres.
L’ensemble des espaces de noms cibles est fourni par une chaîne délimitée par virgule stockée dans l’annotation olm.targetNamespaces d’une version de service cluster (CSV). Cette annotation est appliquée aux instances CSV des opérateurs membres et est projetée dans leurs déploiements.
Ressources supplémentaires
2.4.1.2.6. Conditions de l’opérateur
Dans le cadre de son rôle dans la gestion du cycle de vie d’un opérateur, Operator Lifecycle Manager (OLM) infère l’état d’un opérateur à partir de l’état des ressources Kubernetes qui définissent l’opérateur. Bien que cette approche fournisse un certain niveau d’assurance qu’un exploitant est dans un état donné, il existe de nombreux cas où un opérateur pourrait avoir besoin de communiquer des informations à OLM qui ne pourraient pas être déduits autrement. Ces informations peuvent ensuite être utilisées par OLM pour mieux gérer le cycle de vie de l’opérateur.
L’ODM fournit une définition de ressource personnalisée (CRD) appelée OperatorCondition qui permet aux opérateurs de communiquer les conditions à OLM. Il existe un ensemble de conditions supportées qui influencent la gestion de l’opérateur par OLM lorsqu’elles sont présentes dans la gamme Spec.Conditions d’une ressource OperatorCondition.
Le tableau Spec.Conditions n’est pas présent dans un objet OperatorCondition tant qu’il n’est pas ajouté par un utilisateur ou à la suite de la logique personnalisée de l’opérateur.
2.4.2. Architecture du gestionnaire de cycle de vie de l’opérateur
Ce guide décrit l’architecture des composants de Operator Lifecycle Manager (OLM) dans Red Hat OpenShift Service sur AWS.
2.4.2.1. Les responsabilités des composantes
Le gestionnaire du cycle de vie de l’opérateur (OLM) est composé de deux opérateurs : l’opérateur OLM et l’opérateur de catalogue.
Les OLM et les opérateurs de catalogue sont responsables de la gestion des définitions de ressources personnalisées (DRC) qui constituent la base du cadre OLM:
| A) Ressources | Court nom | Le propriétaire | Description |
|---|---|---|---|
| ClusterServiceVersion (CSV) |
| LES OLM | Les métadonnées de l’application: nom, version, icône, ressources requises, installation, etc. |
|
|
| Catalogue | Liste calculée des ressources à créer pour installer ou mettre à jour automatiquement un CSV. |
|
|
| Catalogue | Dépôt de CSV, CRD et packages qui définissent une application. |
|
|
| Catalogue | Il est utilisé pour garder les CSV à jour en suivant un canal dans un paquet. |
|
|
| LES OLM | Configure tous les opérateurs déployés dans le même espace de noms que l’objet OperatorGroup pour surveiller leur ressource personnalisée (CR) dans une liste d’espaces de noms ou à l’échelle du cluster. |
Chacun de ces opérateurs est également responsable de la création des ressources suivantes:
| A) Ressources | Le propriétaire |
|---|---|
|
| LES OLM |
|
| |
|
| |
|
| |
| CustomResourceDefinitions (CRD) | Catalogue |
|
|
2.4.2.2. Opérateur OLM
L’opérateur OLM est responsable du déploiement des applications définies par les ressources CSV une fois que les ressources requises spécifiées dans le CSV sont présentes dans le cluster.
L’opérateur OLM n’est pas concerné par la création des ressources requises; vous pouvez choisir de créer manuellement ces ressources à l’aide du CLI ou à l’aide de l’opérateur de catalogue. Cette séparation des préoccupations permet aux utilisateurs d’adhérer progressivement en fonction de la quantité du cadre OLM qu’ils choisissent d’utiliser pour leur application.
L’opérateur OLM utilise le flux de travail suivant:
- Consultez les versions de service cluster (CSV) dans un espace de noms et vérifiez que les exigences sont satisfaites.
Lorsque les exigences sont remplies, exécutez la stratégie d’installation pour le CSV.
NoteLe CSV doit être un membre actif d’un groupe d’opérateurs pour que la stratégie d’installation s’exécute.
2.4.2.3. Opérateur de catalogue
L’opérateur de catalogue est responsable de la résolution et de l’installation des versions de services de cluster (CSV) et des ressources requises qu’ils spécifient. Il est également responsable de regarder les sources de catalogue pour les mises à jour des paquets dans les canaux et de les mettre à niveau, automatiquement si désiré, vers les dernières versions disponibles.
Afin de suivre un paquet dans un canal, vous pouvez créer un objet d’abonnement configurant le paquet, le canal et l’objet CatalogSource que vous souhaitez utiliser pour tirer les mises à jour. Lorsque des mises à jour sont trouvées, un objet InstallPlan approprié est écrit dans l’espace de noms pour le compte de l’utilisateur.
L’opérateur de catalogue utilise le flux de travail suivant:
- Connectez-vous à chaque source de catalogue dans le cluster.
Attention aux plans d’installation non résolus créés par un utilisateur, et s’il est trouvé:
- Cherchez le CSV correspondant au nom demandé et ajoutez le CSV en tant que ressource résolue.
- Ajoutez le CRD en tant que ressource résolue pour chaque CRD géré ou requis.
- Dans chaque CRD requis, trouvez le CSV qui le gère.
- Consultez les plans d’installation résolus et créez toutes les ressources découvertes pour elle, si elles sont approuvées par un utilisateur ou automatiquement.
- Consultez les sources de catalogue et les abonnements et créez des plans d’installation basés sur elles.
2.4.2.4. Registre du catalogue
Le registre de catalogue stocke les CSV et les CRD pour la création dans un cluster et stocke les métadonnées sur les paquets et les canaux.
Le manifeste de paquet est une entrée dans le Registre de catalogue qui associe une identité de paquet à des ensembles de CSV. Dans un paquet, les canaux pointent vers un CSV particulier. Comme les CSV se réfèrent explicitement au CSV qu’ils remplacent, un manifeste de paquets fournit à l’opérateur de catalogue toutes les informations nécessaires pour mettre à jour un CSV vers la dernière version d’un canal, passant par chaque version intermédiaire.
2.4.3. Flux de travail du gestionnaire de cycle de vie de l’opérateur
Ce guide décrit le flux de travail de Operator Lifecycle Manager (OLM) dans Red Hat OpenShift Service sur AWS.
2.4.3.1. Installation de l’opérateur et mise à niveau du flux de travail dans OLM
Dans l’écosystème Gestionnaire du cycle de vie de l’opérateur (GLO), les ressources suivantes sont utilisées pour résoudre les installations et les mises à niveau de l’opérateur:
- ClusterServiceVersion (CSV)
-
CatalogueSource -
Abonnement
Les métadonnées de l’opérateur, définies dans les CSV, peuvent être stockées dans une collection appelée source de catalogue. L’OLM utilise des sources de catalogue, qui utilisent l’API de registre de l’opérateur, pour interroger les opérateurs disponibles ainsi que des mises à niveau pour les opérateurs installés.
Figure 2.3. Aperçu de la source du catalogue

Au sein d’une source de catalogue, les opérateurs sont organisés en paquets et en flux de mises à jour appelées canaux, ce qui devrait être un modèle de mise à jour familier de Red Hat OpenShift Service sur AWS ou d’autres logiciels sur un cycle de publication continu comme les navigateurs Web.
Figure 2.4. Forfaits et canaux dans une source de catalogue

L’utilisateur indique un paquet et un canal particuliers dans une source de catalogue particulière dans un abonnement, par exemple un paquet etcd et son canal alpha. Lorsqu’un abonnement est effectué à un paquet qui n’a pas encore été installé dans l’espace de noms, le dernier opérateur de ce paquet est installé.
L’OLM évite délibérément les comparaisons de versions, de sorte que le "dernier" ou "plus récent" Opérateur disponible à partir d’un catalogue donné
Chaque CSV a un paramètre de remplacement qui indique quel opérateur il remplace. Cela crée un graphique de CSV qui peut être interrogé par OLM, et les mises à jour peuvent être partagées entre les canaux. Les canaux peuvent être considérés comme des points d’entrée dans le graphique des mises à jour:
Figure 2.5. Graphique OLM des mises à jour des canaux disponibles
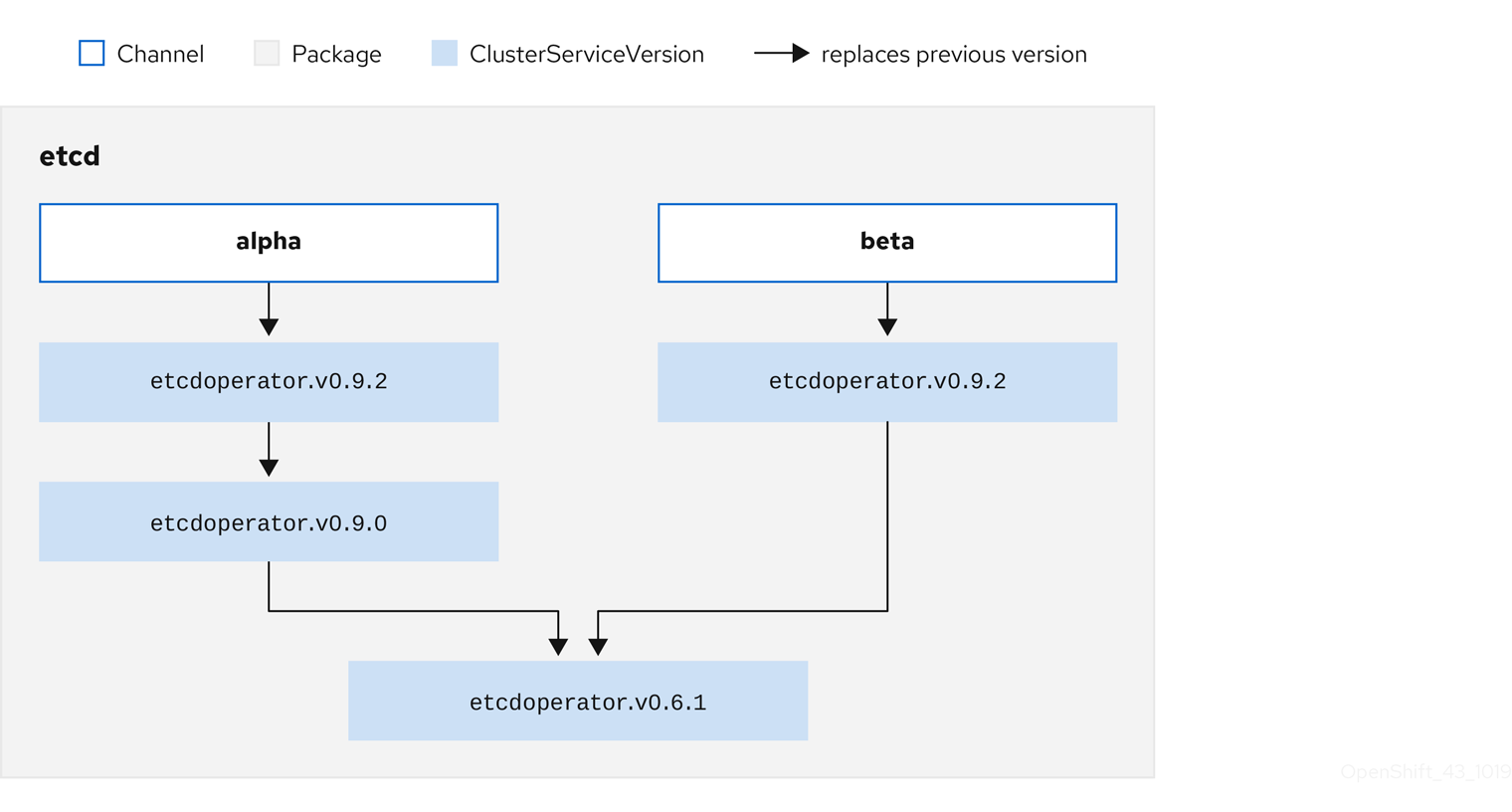
Exemples de canaux dans un paquet
packageName: example
channels:
- name: alpha
currentCSV: example.v0.1.2
- name: beta
currentCSV: example.v0.1.3
defaultChannel: alphaAfin que OLM puisse interroger avec succès les mises à jour, compte tenu d’une source de catalogue, d’un paquet, d’un canal et d’un CSV, un catalogue doit pouvoir retourner, sans ambiguïté et de façon déterministe, un seul CSV qui remplace le CSV d’entrée.
2.4.3.1.1. Exemple de chemin de mise à niveau
Dans un exemple de scénario de mise à niveau, envisagez un opérateur installé correspondant à la version 0.1.1 de CSV. L’OLM interroge la source du catalogue et détecte une mise à niveau dans le canal souscrit avec la nouvelle version CSV 0.1.3 qui remplace une version CSV ancienne mais non installée 0.1.2, qui remplace à son tour la version CSV plus ancienne et installée 0.1.1.
L’OLM retourne de la tête du canal aux versions précédentes via le champ de remplacement spécifié dans les CSV pour déterminer le chemin de mise à niveau 0.1.3
Dans ce scénario donné, OLM installe la version 0.1.2 de l’opérateur pour remplacer la version 0.1.1 de l’opérateur existant. Ensuite, il installe la version 0.1.3 de l’opérateur pour remplacer la version 0.1.2 de l’opérateur précédemment installé. À ce stade, la version 0.1.3 de l’opérateur installé correspond à la tête du canal et la mise à niveau est terminée.
2.4.3.1.2. Des mises à niveau de saut
Le chemin de base pour les mises à niveau dans OLM est:
- La source du catalogue est mise à jour avec une ou plusieurs mises à jour d’un opérateur.
- L’OLM traverse toutes les versions de l’Opérateur jusqu’à atteindre la dernière version que contient la source du catalogue.
Cependant, parfois, ce n’est pas une opération sûre à effectuer. Il y aura des cas où une version publiée d’un opérateur ne devrait jamais être installée sur un cluster s’il ne l’a pas déjà fait, par exemple parce qu’une version introduit une vulnérabilité grave.
Dans ces cas, OLM doit tenir compte de deux états de cluster et fournir un graphique de mise à jour qui prend en charge les deux:
- Le "mauvais" opérateur intermédiaire a été vu par le cluster et installé.
- Le "mauvais" opérateur intermédiaire n’a pas encore été installé sur le cluster.
En expédiant un nouveau catalogue et en ajoutant une version sautée, OLM est assuré qu’il peut toujours obtenir une seule mise à jour unique quel que soit l’état du cluster et s’il a vu la mauvaise mise à jour encore.
Exemple CSV avec version sautée
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: etcdoperator.v0.9.2
namespace: placeholder
annotations:
spec:
displayName: etcd
description: Etcd Operator
replaces: etcdoperator.v0.9.0
skips:
- etcdoperator.v0.9.1Considérez l’exemple suivant de Old CatalogSource et New CatalogSource.
Figure 2.6. Sauter les mises à jour

Ce graphique maintient que:
- Chaque opérateur trouvé dans Old CatalogSource a un seul remplacement dans New CatalogSource.
- Chaque opérateur trouvé dans New CatalogSource a un seul remplacement dans New CatalogSource.
- Lorsque la mauvaise mise à jour n’a pas encore été installée, elle ne le sera jamais.
2.4.3.1.3. Le remplacement de plusieurs opérateurs
Créer un nouveau catalogueSource comme décrit nécessite la publication de CSV qui remplacent un opérateur, mais peuvent en sauter plusieurs. Cela peut être accompli en utilisant l’annotation de skipRange:
olm.skipRange: <semver_range>lorsque <semver_range> a le format de plage de version pris en charge par la bibliothèque semver.
Lors de la recherche de catalogues pour les mises à jour, si la tête d’un canal a une annotation skipRange et que l’opérateur actuellement installé a un champ de version qui tombe dans la plage, OLM met à jour la dernière entrée dans le canal.
L’ordre de préséance est:
- Tête de canal dans la source spécifiée par sourceName sur l’abonnement, si les autres critères de saut sont remplis.
- L’opérateur suivant qui remplace le courant, dans la source spécifiée par sourceName.
- Canal tête dans une autre source qui est visible à l’abonnement, si les autres critères de saut sont remplis.
- L’opérateur suivant qui remplace le courant dans n’importe quelle source visible à l’abonnement.
Exemple CSV avec skipRange
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: elasticsearch-operator.v4.1.2
namespace: <namespace>
annotations:
olm.skipRange: '>=4.1.0 <4.1.2'2.4.3.1.4. Le support Z-stream
La version z-stream ou patch doit remplacer toutes les versions précédentes de z-stream pour la même version mineure. L’OLM ne considère pas les versions majeures, mineures ou patchées, il suffit de construire le graphique correct dans un catalogue.
En d’autres termes, OLM doit pouvoir prendre un graphique comme dans Old CatalogSource et, comme auparavant, générer un graphique comme dans New CatalogSource:
Figure 2.7. Le remplacement de plusieurs opérateurs

Ce graphique maintient que:
- Chaque opérateur trouvé dans Old CatalogSource a un seul remplacement dans New CatalogSource.
- Chaque opérateur trouvé dans New CatalogSource a un seul remplacement dans New CatalogSource.
- Chaque version z-stream dans Old CatalogSource sera mise à jour vers la dernière version z-stream dans New CatalogSource.
- Les versions indisponibles peuvent être considérées comme des nœuds graphiques « virtuels » ; leur contenu n’a pas besoin d’exister, le registre doit simplement répondre comme si le graphique ressemblait à cela.
2.4.4. La résolution de dépendance du gestionnaire de cycle de vie de l’opérateur
Ce guide décrit la résolution des dépendances et la définition de ressources personnalisées (CRD) mises à niveau des cycles de vie avec Operator Lifecycle Manager (OLM) dans Red Hat OpenShift Service sur AWS.
2.4.4.1. À propos de la résolution de dépendance
Le gestionnaire de cycle de vie de l’opérateur (OLM) gère la résolution de dépendance et la mise à niveau du cycle de vie des opérateurs en cours d’exécution. À bien des égards, les problèmes auxquels OLM est confronté sont similaires à d’autres gestionnaires de systèmes ou de paquets linguistiques, tels que yum et rpm.
Cependant, il y a une contrainte que les systèmes similaires n’ont généralement pas que OLM: parce que les opérateurs sont toujours en cours d’exécution, OLM tente de s’assurer que vous ne restez jamais avec un ensemble d’opérateurs qui ne fonctionnent pas les uns avec les autres.
En conséquence, OLM ne doit jamais créer les scénarios suivants:
- Installer un ensemble d’opérateurs nécessitant des API qui ne peuvent pas être fournies
- Actualisez un opérateur d’une manière qui en casse un autre qui en dépend
Cela est rendu possible avec deux types de données:
| Les propriétés | Dactylographié métadonnées sur l’opérateur qui constitue l’interface publique pour lui dans le résolveur de dépendance. Les exemples incluent le groupe/version/type (GVK) des API fournies par l’opérateur et la version sémantique (semver) de l’opérateur. |
| Contraintes ou dépendances | Les exigences d’un opérateur qui devraient être satisfaites par d’autres opérateurs qui auraient pu ou non déjà été installés sur le cluster cible. Ceux-ci agissent comme des requêtes ou des filtres sur tous les opérateurs disponibles et limitent la sélection lors de la résolution et de l’installation de dépendance. Les exemples incluent le fait d’exiger qu’une API spécifique soit disponible sur le cluster ou de s’attendre à ce qu’un opérateur particulier avec une version particulière soit installé. |
L’OLM convertit ces propriétés et contraintes en un système de formules booléennes et les transmet à un solveur SAT, un programme qui établit la satisfaction booléenne, qui fait le travail de déterminer ce que les opérateurs devraient être installés.
2.4.4.2. Les propriétés de l’opérateur
Les opérateurs d’un catalogue ont les propriétés suivantes:
emballage OLM.- Comprend le nom du paquet et la version de l’opérateur
à propos de OLM.gvk- D’une seule propriété pour chaque API fournie à partir de la version de service cluster (CSV)
Des propriétés supplémentaires peuvent également être déclarées directement par un auteur de l’opérateur en incluant un fichier properties.yaml dans les métadonnées/annuaire du paquet Opérateur.
Exemple de propriété arbitraire
properties:
- type: olm.kubeversion
value:
version: "1.16.0"2.4.4.2.1. Des propriétés arbitraires
Les auteurs d’opérateurs peuvent déclarer des propriétés arbitraires dans un fichier properties.yaml dans le répertoire métadonnées du paquet Opérateur. Ces propriétés sont traduites en une structure de données cartographiques qui est utilisée comme entrée pour le résolveur de cycle de vie de l’opérateur (OLM) au moment de l’exécution.
Ces propriétés sont opaques pour le résolveur car il ne comprend pas les propriétés, mais il peut évaluer les contraintes génériques par rapport à ces propriétés pour déterminer si les contraintes peuvent être satisfaites compte tenu de la liste des propriétés.
Exemple de propriétés arbitraires
properties:
- property:
type: color
value: red
- property:
type: shape
value: square
- property:
type: olm.gvk
value:
group: olm.coreos.io
version: v1alpha1
kind: myresourceCette structure peut être utilisée pour construire une expression du langage d’expression commune (CEL) pour des contraintes génériques.
Ressources supplémentaires
2.4.4.3. Dépendances des opérateurs
Les dépendances d’un opérateur sont listées dans un fichier de dépendances.yaml dans le dossier métadonnées d’un bundle. Ce fichier est facultatif et actuellement utilisé uniquement pour spécifier des dépendances explicites de version d’opérateur.
La liste de dépendances contient un champ de type pour chaque élément pour spécifier quel type de dépendance il s’agit. Les types de dépendances des opérateurs suivants sont pris en charge:
emballage OLM.- Ce type indique une dépendance pour une version spécifique de l’opérateur. Les informations de dépendance doivent inclure le nom du paquet et la version du paquet au format semver. À titre d’exemple, vous pouvez spécifier une version exacte telle que 0.5.2 ou une gamme de versions telles que >0.5.1.
à propos de OLM.gvk- Avec ce type, l’auteur peut spécifier une dépendance avec des informations de groupe/version/type (GVK), similaire à l’utilisation existante CRD et API dans un CSV. Il s’agit d’un chemin permettant aux auteurs de l’opérateur de consolider toutes les dépendances, API ou versions explicites, pour être au même endroit.
limite OLM.- Ce type déclare des contraintes génériques sur les propriétés arbitraires de l’opérateur.
Dans l’exemple suivant, les dépendances sont spécifiées pour un opérateur Prometheus et etcd CRD:
Exemple de fichier dépendances.yaml
dependencies:
- type: olm.package
value:
packageName: prometheus
version: ">0.27.0"
- type: olm.gvk
value:
group: etcd.database.coreos.com
kind: EtcdCluster
version: v1beta22.4.4.4. Contraintes génériques
La propriété olm.constraint déclare une contrainte de dépendance d’un type particulier, différenciant les propriétés non contraintes et les propriétés de contrainte. Le champ de valeur est un objet contenant un champ failMessage tenant une chaîne-représentation du message de contrainte. Ce message est présenté comme un commentaire informatif aux utilisateurs si la contrainte n’est pas satisfaisante au moment de l’exécution.
Les touches suivantes indiquent les types de contrainte disponibles:
GVK- Le type dont la valeur et l’interprétation sont identiques au type olm.gvk
forfait- Le type dont la valeur et l’interprétation sont identiques au type olm.package
CEL- Expression du langage d’expression commune (CEL) évaluée au cours de l’exécution par le résolveur du gestionnaire du cycle de vie de l’opérateur (OLM) sur les propriétés arbitraires des faisceaux et les informations de cluster
- de tout, n’importe quoi, pas
- Contraintes de conjonction, de disjonction et de négation, respectivement, contenant une ou plusieurs contraintes concrètes, telles que gvk ou une contrainte composée imbriquée
2.4.4.4.1. Les contraintes du langage d’expression commune (CEL)
Le type de contrainte Cel prend en charge le langage d’expression commun (CEL) comme langage d’expression. La structure de cel a un champ de règle qui contient la chaîne d’expression CEL qui est évaluée par rapport aux propriétés de l’opérateur à l’exécution pour déterminer si l’opérateur satisfait à la contrainte.
Exemple de contrainte cel
type: olm.constraint
value:
failureMessage: 'require to have "certified"'
cel:
rule: 'properties.exists(p, p.type == "certified")'La syntaxe CEL prend en charge un large éventail d’opérateurs logiques, tels que AND et OR. En conséquence, une seule expression CEL peut avoir plusieurs règles pour de multiples conditions qui sont liées entre elles par ces opérateurs logiques. Ces règles sont évaluées par rapport à un ensemble de données de plusieurs propriétés différentes à partir d’un faisceau ou d’une source donnée, et la sortie est résolue en un seul faisceau ou opérateur qui satisfait toutes ces règles à l’intérieur d’une seule contrainte.
Exemple de contrainte cel avec plusieurs règles
type: olm.constraint
value:
failureMessage: 'require to have "certified" and "stable" properties'
cel:
rule: 'properties.exists(p, p.type == "certified") && properties.exists(p, p.type == "stable")'2.4.4.4.2. Contraintes composées (toutes, toutes, pas)
Les types de contrainte composée sont évalués en fonction de leurs définitions logiques.
Ce qui suit est un exemple de contrainte conjonctive (tous) de deux paquets et d’un GVK. C’est-à-dire qu’ils doivent tous être satisfaits par des paquets installés:
Exemple toutes les contraintes
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: All are required for Red because...
all:
constraints:
- failureMessage: Package blue is needed for...
package:
name: blue
versionRange: '>=1.0.0'
- failureMessage: GVK Green/v1 is needed for...
gvk:
group: greens.example.com
version: v1
kind: GreenCe qui suit est un exemple d’une contrainte disjonctive (toute) de trois versions du même GVK. C’est-à-dire qu’au moins un doit être satisfait par des paquets installés:
Exemple de toute contrainte
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: Any are required for Red because...
any:
constraints:
- gvk:
group: blues.example.com
version: v1beta1
kind: Blue
- gvk:
group: blues.example.com
version: v1beta2
kind: Blue
- gvk:
group: blues.example.com
version: v1
kind: BlueCe qui suit est un exemple de contrainte de négation (non) d’une version d’un GVK. C’est-à-dire que ce GVK ne peut être fourni par aucun paquet dans l’ensemble de résultats:
Exemple non contrainte
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
all:
constraints:
- failureMessage: Package blue is needed for...
package:
name: blue
versionRange: '>=1.0.0'
- failureMessage: Cannot be required for Red because...
not:
constraints:
- gvk:
group: greens.example.com
version: v1alpha1
kind: greensLa sémantique de négation peut sembler floue dans le contexte non de contrainte. Afin de clarifier, la négation est vraiment d’ordonner au résolveur de supprimer toute solution possible qui inclut un GVK particulier, un paquet dans une version, ou satisfait une contrainte composée d’enfants à partir de l’ensemble de résultats.
En tant que corollaire, la contrainte non composée ne doit être utilisée que dans toutes les contraintes, car la négation sans d’abord sélectionner un ensemble possible de dépendances n’a pas de sens.
2.4.4.4.3. Contraintes des composés imbriqués
La contrainte composée imbriquée, qui contient au moins une contrainte composée enfantine ainsi que zéro ou plus contraintes simples, est évaluée à partir du bas vers le haut selon les procédures pour chaque type de contrainte décrit précédemment.
Ce qui suit est un exemple de disjonction de conjonctions, où l’une, l’autre, ou les deux peuvent satisfaire la contrainte:
Exemple de contrainte composée imbriquée
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: Required for Red because...
any:
constraints:
- all:
constraints:
- package:
name: blue
versionRange: '>=1.0.0'
- gvk:
group: blues.example.com
version: v1
kind: Blue
- all:
constraints:
- package:
name: blue
versionRange: '<1.0.0'
- gvk:
group: blues.example.com
version: v1beta1
kind: BlueLa taille brute maximale d’un type olm.constraint est de 64KB pour limiter les attaques d’épuisement des ressources.
2.4.4.5. Les préférences de dépendance
Il peut y avoir de nombreuses options qui répondent également à une dépendance d’un opérateur. Le résolveur de dépendance dans Operator Lifecycle Manager (OLM) détermine quelle option correspond le mieux aux exigences de l’opérateur demandé. En tant qu’auteur ou utilisateur de l’opérateur, il peut être important de comprendre comment ces choix sont faits afin que la résolution de dépendance soit claire.
2.4.4.5.1. La priorité du catalogue
Dans Red Hat OpenShift Service sur AWS cluster, OLM lit les sources du catalogue pour savoir quels opérateurs sont disponibles pour l’installation.
Exemple d’objet CatalogSource
apiVersion: "operators.coreos.com/v1alpha1"
kind: "CatalogSource"
metadata:
name: "my-operators"
namespace: "operators"
spec:
sourceType: grpc
grpcPodConfig:
securityContextConfig: <security_mode>
image: example.com/my/operator-index:v1
displayName: "My Operators"
priority: 100- 1
- Indiquez la valeur de l’héritage ou de la restriction. Lorsque le champ n’est pas défini, la valeur par défaut est héritée. Dans un futur service Red Hat OpenShift sur AWS, il est prévu que la valeur par défaut soit limitée. Dans le cas où votre catalogue ne peut pas fonctionner avec des autorisations restreintes, il est recommandé de définir manuellement ce champ sur l’héritage.
L’objet CatalogSource a un champ de priorité, qui est utilisé par le résolveur pour savoir comment préférer les options pour une dépendance.
Il y a deux règles qui régissent la préférence du catalogue:
- Les options dans les catalogues à priorité élevée sont préférées aux options dans les catalogues à priorité inférieure.
- Les options dans le même catalogue que la personne dépendante sont préférées à tout autre catalogue.
2.4.4.5.2. Commande de canaux
Le package Opérateur dans un catalogue est une collection de canaux de mise à jour auxquels un utilisateur peut s’abonner dans un service Red Hat OpenShift sur AWS cluster. Les canaux peuvent être utilisés pour fournir un flux particulier de mises à jour pour une libération mineure (1.2, 1.3) ou une fréquence de libération (stable, rapide).
Il est probable qu’une dépendance pourrait être satisfaite par les opérateurs dans le même paquet, mais différents canaux. À titre d’exemple, la version 1.2 d’un opérateur peut exister dans les canaux stables et rapides.
Chaque paquet a un canal par défaut, qui est toujours préféré aux canaux non par défaut. Dans le cas où aucune option dans le canal par défaut ne peut satisfaire une dépendance, des options sont envisagées à partir des canaux restants dans l’ordre lexicographique du nom du canal.
2.4.4.5.3. Commandez à l’intérieur d’un canal
Il y a presque toujours plusieurs options pour satisfaire une dépendance au sein d’un seul canal. À titre d’exemple, les opérateurs d’un seul paquet et d’un canal fournissent le même ensemble d’API.
Lorsqu’un utilisateur crée un abonnement, il indique quel canal recevoir des mises à jour. Cela réduit immédiatement la recherche à ce seul canal. Cependant, à l’intérieur du canal, il est probable que de nombreux opérateurs répondent à une dépendance.
Au sein d’un canal, les opérateurs plus récents qui sont plus haut dans le graphique de mise à jour sont préférés. Lorsque la tête d’un canal satisfait à une dépendance, elle sera d’abord essayée.
2.4.4.5.4. Autres contraintes
En plus des contraintes fournies par les dépendances de paquets, OLM inclut des contraintes supplémentaires pour représenter l’état utilisateur souhaité et imposer des invariants de résolution.
2.4.4.5.4.1. Contrainte d’abonnement
La contrainte d’abonnement filtre l’ensemble des opérateurs qui peuvent satisfaire un abonnement. Les abonnements sont des contraintes fournies par l’utilisateur pour le résolveur de dépendance. Ils déclarent avoir l’intention soit d’installer un nouvel opérateur s’il n’est pas déjà sur le cluster, soit de tenir à jour un opérateur existant.
2.4.4.5.4.2. Contrainte du paquet
Dans un espace de noms, aucun opérateur ne peut provenir du même paquet.
2.4.4.6. Les mises à niveau de CRD
L’ODM met immédiatement à niveau une définition de ressource personnalisée (CRD) s’il appartient à une version de service de cluster singulier (CSV). Lorsqu’un CRD est détenu par plusieurs CSV, le CRD est mis à niveau lorsqu’il a satisfait à toutes les conditions suivantes:
- Dans le nouveau CRD, toutes les versions de service existantes sont présentes dans le nouveau CRD.
- Les instances existantes, ou ressources personnalisées, associées aux versions de service du CRD sont valides lorsqu’elles sont validées par rapport au schéma de validation du nouveau CRD.
2.4.4.7. Les meilleures pratiques en matière de dépendance
Lorsque vous spécifiez les dépendances, il existe des pratiques exemplaires que vous devriez considérer.
- Dépendez des API ou d’une gamme de versions spécifique d’opérateurs
- Les opérateurs peuvent ajouter ou supprimer des API à tout moment; toujours spécifier une dépendance olm.gvk sur toutes les API requises par vos opérateurs. L’exception à cela est si vous spécifiez les contraintes olm.package à la place.
- Définir une version minimale
La documentation Kubernetes sur les modifications d’API décrit les changements autorisés pour les opérateurs de style Kubernetes. Ces conventions de version permettent à un opérateur de mettre à jour une API sans heurter la version API, tant que l’API est rétrocompatible.
En ce qui concerne les dépendances des opérateurs, cela signifie que connaître la version API d’une dépendance peut ne pas suffire à s’assurer que l’opérateur dépendant fonctionne comme prévu.
À titre d’exemple:
- Le TestOperator v1.0.0 fournit la version API v1alpha1 de la ressource MyObject.
- Le TestOperator v1.0.1 ajoute un nouveau champ spec.newfield à MyObject, mais toujours à v1alpha1.
Il se peut que votre opérateur ait besoin de la possibilité d’écrire spec.newfield dans la ressource MyObject. À elle seule, une contrainte olm.gvk ne suffit pas à OLM pour déterminer que vous avez besoin de TestOperator v1.0.1 et non TestOperator v1.0.0.
Dans la mesure du possible, si un opérateur spécifique qui fournit une API est connu à l’avance, spécifiez une contrainte supplémentaire olm.package pour définir un minimum.
- Omettre une version maximale ou permettre une très large gamme
Étant donné que les opérateurs fournissent des ressources en grappes telles que les services API et les CRD, un opérateur qui spécifie une petite fenêtre pour une dépendance peut entraver inutilement les mises à jour pour les autres consommateurs de cette dépendance.
Dans la mesure du possible, ne définissez pas une version maximale. Alternativement, définissez une gamme sémantique très large pour éviter les conflits avec d’autres opérateurs. À titre d’exemple, >1.0.0 <2.0.0.
Contrairement aux gestionnaires de paquets conventionnels, les auteurs d’opérateurs codent explicitement que les mises à jour sont sûres via les canaux dans OLM. Lorsqu’une mise à jour est disponible pour un abonnement existant, il est supposé que l’auteur de l’opérateur indique qu’il peut mettre à jour à partir de la version précédente. La définition d’une version maximale pour une dépendance remplace le flux de mise à jour de l’auteur en la tronquant inutilement à une limite supérieure particulière.
NoteLes administrateurs de cluster ne peuvent pas remplacer les dépendances définies par un auteur de l’opérateur.
Cependant, les versions maximales peuvent et doivent être définies s’il y a des incompatibilités connues qui doivent être évitées. Les versions spécifiques peuvent être omises avec la syntaxe de la plage de versions, par exemple > 1.0.0 !1.2.1.
2.4.4.8. Avertissements de dépendance
Lorsque vous spécifiez des dépendances, il y a des mises en garde que vous devriez considérer.
- Aucune contrainte composée (AND)
Il n’existe actuellement aucune méthode pour spécifier une relation ET entre les contraintes. En d’autres termes, il n’y a aucun moyen de spécifier qu’un opérateur dépend d’un autre opérateur qui fournit à la fois une API donnée et une version >1.1.0.
Cela signifie que lorsque vous spécifiez une dépendance telle que:
dependencies: - type: olm.package value: packageName: etcd version: ">3.1.0" - type: olm.gvk value: group: etcd.database.coreos.com kind: EtcdCluster version: v1beta2Il serait possible pour OLM de satisfaire cela avec deux opérateurs : l’un qui fournit EtcdCluster et l’autre qui a la version >3.1.0. La question de savoir si cela se produit, ou si un opérateur est sélectionné qui satisfait aux deux contraintes, dépend de la commande que les options potentielles sont visitées. Les préférences de dépendance et les options de commande sont bien définies et peuvent être motivées, mais pour faire preuve de prudence, les opérateurs devraient s’en tenir à un mécanisme ou à l’autre.
- Compatibilité cross-namespace
- L’ODM effectue une résolution de dépendance à la portée de l’espace de noms. Il est possible d’entrer dans une impasse de mise à jour si la mise à jour d’un opérateur dans un espace de noms serait un problème pour un opérateur dans un autre espace de noms, et vice-versa.
2.4.4.9. Exemples de scénarios de résolution de dépendance
Dans les exemples suivants, un fournisseur est un opérateur qui « possède » un service CRD ou API.
Exemple : Dépréciation des API dépendantes
A et B sont des API (CRD):
- Le fournisseur de A dépend de B.
- Le fournisseur de B a un abonnement.
- Le fournisseur de mises à jour B pour fournir C mais déprécie B.
Il en résulte:
- B n’a plus de fournisseur.
- A ne fonctionne plus.
C’est un cas que OLM empêche avec sa stratégie de mise à niveau.
Exemple : dans l’impasse de version
A et B sont des API:
- Le fournisseur de A nécessite B.
- Le fournisseur de B nécessite A.
- Le fournisseur de mises à jour A (fournir A2, nécessite B2) et déprécater A.
- Le fournisseur de mises à jour B (fournir B2, nécessite A2) et déprécier B.
Lorsque OLM tente de mettre à jour A sans mettre à jour simultanément B, ou vice-versa, il est impossible de passer à de nouvelles versions des Opérateurs, même si un nouvel ensemble compatible peut être trouvé.
C’est un autre cas que OLM empêche avec sa stratégie de mise à niveau.
2.4.5. Groupes d’opérateurs
Ce guide décrit l’utilisation des groupes d’opérateurs avec Operator Lifecycle Manager (OLM) dans Red Hat OpenShift Service sur AWS.
2.4.5.1. À propos des groupes d’opérateurs
Le groupe d’opérateurs, défini par la ressource OperatorGroup, fournit une configuration multilocataires aux Opérateurs installés par OLM. Le groupe d’opérateur sélectionne les espaces de noms cibles dans lesquels générer l’accès RBAC requis pour ses opérateurs membres.
L’ensemble des espaces de noms cibles est fourni par une chaîne délimitée par virgule stockée dans l’annotation olm.targetNamespaces d’une version de service cluster (CSV). Cette annotation est appliquée aux instances CSV des opérateurs membres et est projetée dans leurs déploiements.
2.4.5.2. Adhésion au groupe d’opérateurs
L’opérateur est considéré comme un membre d’un groupe d’opérateurs si les conditions suivantes sont vraies:
- Le CSV de l’Opérateur existe dans le même espace de noms que le groupe Opérateur.
- Les modes d’installation dans le CSV de l’Opérateur prennent en charge l’ensemble d’espaces de noms ciblés par le groupe Opérateur.
Le mode d’installation dans un CSV se compose d’un champ InstallModeType et d’un champ supporté booléen. La spécification d’un CSV peut contenir un ensemble de modes d’installation de quatre InstallModeTypes distincts:
| InstallerModeType | Description |
|---|---|
|
| L’opérateur peut être membre d’un groupe d’opérateurs qui sélectionne son propre espace de noms. |
|
| L’opérateur peut être membre d’un groupe d’opérateurs qui sélectionne un espace de noms. |
|
| L’opérateur peut être membre d’un groupe d’opérateurs qui sélectionne plus d’un espace de noms. |
|
| L’opérateur peut être membre d’un groupe d’opérateurs qui sélectionne tous les espaces de noms (le jeu d’espace de noms cible est la chaîne vide ""). |
Lorsque la spécification d’un CSV omet une entrée de InstallModeType, alors ce type est considéré comme non pris en charge, sauf si le support peut être déduit par une entrée existante qui le supporte implicitement.
2.4.5.3. Choix de l’espace de noms cible
Il est possible de nommer explicitement l’espace de noms cible pour un groupe d’opérateurs en utilisant le paramètre spec.targetNamespaces:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
targetNamespaces:
- my-namespaceAlternativement, vous pouvez spécifier un espace de noms à l’aide d’un sélecteur d’étiquettes avec le paramètre spec.selector:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
selector:
cool.io/prod: "true"L’inscription de plusieurs espaces de noms via spec.targetNamespaces ou l’utilisation d’un sélecteur d’étiquette via spec.selector n’est pas recommandée, car la prise en charge de plus d’un espace de noms cible dans un groupe d’opérateurs sera probablement supprimée dans une version ultérieure.
Lorsque spec.targetNamespaces et spec.selector sont définis, spec.selector est ignoré. Alternativement, vous pouvez omettre à la fois spec.selector et spec.targetNamespaces pour spécifier un groupe d’opérateur global, qui sélectionne tous les espaces de noms:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespaceL’ensemble résolu d’espaces de noms sélectionnés est affiché dans le paramètre status.namespaces d’un groupe Opeator. Le status.namespace d’un groupe d’opérateur mondial contient la chaîne vide (""), qui signale à un opérateur consommant qu’il devrait regarder tous les espaces de noms.
2.4.5.4. Annotations du groupe d’opérateurs CSV
Les CSV membres d’un groupe d’opérateurs ont les annotations suivantes:
| Annotation | Description |
|---|---|
|
| Contient le nom du groupe Opérateur. |
|
| Contient l’espace de noms du groupe Opérateur. |
|
| Contient une chaîne délimitée par virgule qui répertorie la sélection de l’espace de noms cible du groupe Opérateur. |
Les annotations sauf olm.targetNamespaces sont incluses avec des CSV copiés. L’omission de l’annotation olm.targetNamespaces sur les CSV copiés empêche la duplication des espaces de noms cibles entre les locataires.
2.4.5.5. Annotation d’API fournie
Groupe/version/type (GVK) est un identifiant unique pour une API Kubernetes. Les informations sur ce que les GVK sont fournis par un groupe d’opérateurs sont affichées dans une annotation des API olm. La valeur de l’annotation est une chaîne composée de <kind>.<version>.<group> délimitée avec des virgules. Les GVK de CRD et les services API fournis par tous les CSV membres actifs d’un groupe d’opérateurs sont inclus.
Examinez l’exemple suivant d’un objet OperatorGroup avec un seul membre actif CSV qui fournit la ressource PackageManifest:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
annotations:
olm.providedAPIs: PackageManifest.v1alpha1.packages.apps.redhat.com
name: olm-operators
namespace: local
...
spec:
selector: {}
serviceAccountName:
metadata:
creationTimestamp: null
targetNamespaces:
- local
status:
lastUpdated: 2019-02-19T16:18:28Z
namespaces:
- local2.4.5.6. Contrôle d’accès basé sur le rôle
Lorsqu’un groupe d’opérateurs est créé, trois rôles de cluster sont générés. Chacune contient une seule règle d’agrégation avec un sélecteur de rôle de cluster défini pour correspondre à une étiquette, comme indiqué ci-dessous:
| Le rôle des clusters | Étiquette à assortir |
|---|---|
|
|
|
|
|
|
|
|
|
Les ressources RBAC suivantes sont générées lorsqu’un CSV devient un membre actif d’un groupe d’opérateurs, tant que le CSV surveille tous les espaces de noms avec le mode d’installation AllNamespaces et n’est pas dans un état défaillant avec la raison InterOperatorGroupOwnerConflict:
- Les rôles de cluster pour chaque ressource API à partir d’un CRD
- Les rôles de cluster pour chaque ressource API à partir d’un service API
- Autres rôles et liens de rôle
| Le rôle des clusters | Les paramètres |
|---|---|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
|
| Les verbes sur apiextensions.k8s.io customresourcedefinitions <crd-name>:
Étiquettes d’agrégation:
|
| Le rôle des clusters | Les paramètres |
|---|---|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
|
| Les verbes sur <kind>:
Étiquettes d’agrégation:
|
Autres rôles et liens de rôle
- Lorsque le CSV définit exactement un espace de noms cible qui contient *, un rôle de cluster et une liaison de rôle de cluster correspondante sont générés pour chaque autorisation définie dans le champ permissions du CSV. L’ensemble des ressources générées sont les étiquettes olm.owner: <csv_name> et olm.owner.namespace: <csv_namespace>.
- Lorsque le CSV ne définit pas exactement un espace de noms cible qui contient *, alors toutes les liaisons de rôles et de rôles dans l’espace de noms de l’opérateur avec les étiquettes olm.owner: <csv_name> et olm.owner.namespace: <csv_namespace> les étiquettes sont copiées dans l’espace de noms cible.
2.4.5.7. CSV copiés
L’OLM crée des copies de tous les CSV membres actifs d’un groupe d’opérateurs dans chacun des espaces de noms cibles de ce groupe d’opérateurs. Le but d’un CSV copié est de dire aux utilisateurs d’un espace de noms cible qu’un opérateur spécifique est configuré pour regarder les ressources créées là-bas.
Les CSV copiés ont une raison de statut Copié et sont mis à jour pour correspondre à l’état de leur CSV source. L’annotation olm.targetNamespaces est dépouillée des CSV copiés avant qu’ils ne soient créés sur le cluster. L’omission de la sélection de l’espace de noms cible évite la duplication des espaces de noms cibles entre les locataires.
Les CSV copiés sont supprimés lorsque leur CSV source n’existe plus ou que le groupe Opérateur que leur source CSV appartient à ne plus cibler l’espace de noms du CSV copié.
Le champ de désactivationCopiedCSVs est désactivé par défaut. Après avoir activé un champ de désactivationCopiedCSVs, l’OMM supprime les CSV existants copiés sur un cluster. Lorsqu’un champ de désactivationCopiedCSVs est désactivé, l’OMM ajoute à nouveau des CSV copiés.
Désactiver le champ de désactivationCopiedCSVs:
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OLMConfig metadata: name: cluster spec: features: disableCopiedCSVs: false EOFActiver le champ de désactivationCopiedCSVs:
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OLMConfig metadata: name: cluster spec: features: disableCopiedCSVs: true EOF
2.4.5.8. Groupes d’opérateurs statiques
Le groupe opérateur est statique si son champ spec.staticProvidedAPIs est défini sur true. En conséquence, OLM ne modifie pas l’annotation olm.suppldAPIs d’un groupe d’opérateurs, ce qui signifie qu’il peut être défini à l’avance. Ceci est utile lorsqu’un utilisateur souhaite utiliser un groupe d’opérateurs pour empêcher la contention des ressources dans un ensemble d’espaces de noms, mais n’a pas de CSV membre actif qui fournissent les API pour ces ressources.
Ci-dessous est un exemple d’un groupe d’opérateurs qui protège les ressources Prometheus dans tous les espaces de noms avec le something.cool.io/cluster-monitoring: "vrai" annotation:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-monitoring
namespace: cluster-monitoring
annotations:
olm.providedAPIs: Alertmanager.v1.monitoring.coreos.com,Prometheus.v1.monitoring.coreos.com,PrometheusRule.v1.monitoring.coreos.com,ServiceMonitor.v1.monitoring.coreos.com
spec:
staticProvidedAPIs: true
selector:
matchLabels:
something.cool.io/cluster-monitoring: "true"2.4.5.9. Intersection du groupe d’opérateurs
Deux groupes d’opérateurs auraient des API fournies si l’intersection de leurs jeux d’espace de noms n’est pas vide et que l’intersection des jeux d’API fournis, définies par les annotations olm.providedAPIs, n’est pas un ensemble vide.
Le problème potentiel réside dans le fait que les groupes d’opérateurs dotés d’API intersectées peuvent rivaliser pour les mêmes ressources dans l’ensemble des espaces de noms croisés.
Lors de la vérification des règles d’intersection, un espace de noms de groupe d’opérateur est toujours inclus dans les espaces de noms cibles sélectionnés.
Les règles pour l’intersection
Chaque fois qu’un membre actif se synchronise, OLM interroge le cluster pour l’ensemble d’intersecting fourni des API entre le groupe Opérateur du CSV et tous les autres. Ensuite, OLM vérifie si cet ensemble est un jeu vide:
Lorsque true et les API fournies par le CSV sont un sous-ensemble du groupe d’opérateurs:
- Continuez la transition.
Lorsque true et les API fournies par le CSV ne sont pas un sous-ensemble du groupe d’opérateurs:
Lorsque le groupe d’opérateurs est statique:
- Nettoyer tous les déploiements appartenant au CSV.
- La transition du CSV vers un état défaillant avec la raison de statut CannotModifierStaticOperatorGroupProvidedAPIs.
B) Si le groupe d’opérateurs n’est pas statique:
- De remplacer l’annotation olm.fourdAPIs du groupe d’opérateurs par l’union de lui-même et les API fournies par le CSV.
En cas de faux et les API fournies par le CSV ne sont pas un sous-ensemble du groupe d’opérateurs:
- Nettoyer tous les déploiements appartenant au CSV.
- Faites passer le CSV à un état défaillant avec raison de statut InterOperatorGroupOwnerConflict.
En cas de faux et les API fournies par le CSV sont un sous-ensemble du groupe d’opérateurs:
Lorsque le groupe d’opérateurs est statique:
- Nettoyer tous les déploiements appartenant au CSV.
- La transition du CSV vers un état défaillant avec la raison de statut CannotModifierStaticOperatorGroupProvidedAPIs.
B) Si le groupe d’opérateurs n’est pas statique:
- De remplacer l’annotation olm.fourdAPIs du groupe d’opérateurs par la différence entre lui-même et les API fournies par le CSV.
Les états de défaillance causés par les groupes d’opérateurs sont non-terminaux.
Les actions suivantes sont effectuées chaque fois qu’un groupe d’opérateurs synchronise:
- L’ensemble d’API fournies à partir des CSV membres actifs est calculé à partir du cluster. Il est à noter que les CSV copiés sont ignorés.
- L’ensemble de clusters est comparé à olm.providedAPIs, et si olm.providedAPIs contient des API supplémentaires, ces API sont taillées.
- Les CSV qui fournissent les mêmes API dans tous les espaces de noms sont requeued. Cela informe les CSV conflictuels des groupes croisés que leur conflit a pu être résolu, soit par le redimensionnement ou par la suppression du CSV conflictuel.
2.4.5.10. Limites pour la gestion des opérateurs multilocataires
Le service OpenShift Red Hat sur AWS fournit une prise en charge limitée pour l’installation simultanée de différentes versions d’un opérateur sur le même cluster. Le gestionnaire de cycle de vie de l’opérateur (OLM) installe des opérateurs plusieurs fois dans différents espaces de noms. L’une des contraintes est que les versions API de l’opérateur doivent être les mêmes.
Les opérateurs sont des extensions de plan de contrôle en raison de leur utilisation des objets CustomResourceDefinition (CRD), qui sont des ressources globales dans Kubernetes. Différentes versions majeures d’un opérateur ont souvent des CRD incompatibles. Cela les rend incompatibles à installer simultanément dans différents espaces de noms sur un cluster.
Les locataires, ou espaces de noms, partagent le même plan de contrôle d’un cluster. Ainsi, les locataires d’un cluster multilocataires partagent également des CRD mondiaux, ce qui limite les scénarios dans lesquels différents cas d’un même opérateur peuvent être utilisés en parallèle sur le même cluster.
Les scénarios pris en charge comprennent les éléments suivants:
- Les opérateurs de différentes versions qui envoient exactement la même définition CRD (dans le cas des CRD versionnés, le même ensemble de versions)
- Les opérateurs de différentes versions qui n’expédient pas de CRD, et ont plutôt leur CRD disponible dans un paquet séparé sur OperatorHub
Les autres scénarios ne sont pas pris en charge, car l’intégrité des données du cluster ne peut pas être garantie s’il existe plusieurs CRD concurrents ou qui se chevauchent de différentes versions de l’opérateur à concilier sur le même cluster.
2.4.5.11. Dépannage Groupes d’opérateurs
Adhésion
L’espace de noms d’un plan d’installation ne doit contenir qu’un seul groupe d’opérateurs. Lors de la tentative de générer une version de service cluster (CSV) dans un espace de noms, un plan d’installation considère un groupe opérateur invalide dans les scénarios suivants:
- Aucun groupe d’opérateur n’existe dans l’espace de noms du plan d’installation.
- Des groupes d’opérateurs multiples existent dans l’espace de noms du plan d’installation.
- Le nom de compte de service incorrect ou inexistant est spécifié dans le groupe Opérateur.
Lorsqu’un plan d’installation rencontre un groupe d’opérateur invalide, le CSV n’est pas généré et la ressource InstallPlan continue d’installer avec un message pertinent. À titre d’exemple, le message suivant est fourni si plus d’un groupe d’opérateurs existe dans le même espace de noms:
attenuated service account query failed - more than one operator group(s) are managing this namespace count=2lorsque Count= spécifie le nombre de groupes d’opérateurs dans l’espace de noms.
- Lorsque les modes d’installation d’un CSV ne prennent pas en charge la sélection de l’espace de noms cible du groupe Opérateur dans son espace de noms, le CSV passe à un état de défaillance avec la raison pour laquelle UnsupportedOperatorGroup. Les CSV dans un état défaillant pour cette raison passent en attente après que la sélection de l’espace de noms cible du groupe d’opérateurs modifie une configuration prise en charge, soit les modes d’installation du CSV ont été modifiés pour prendre en charge la sélection de l’espace de noms cible.
2.4.6. Colocation multitenance et opérateur
Ce guide décrit la multitenance et la colocalisation de l’opérateur dans Operator Lifecycle Manager (OLM).
2.4.6.1. Colocation d’opérateurs dans un espace de noms
Le gestionnaire de cycle de vie de l’opérateur (OLM) gère les opérateurs gérés par OLM qui sont installés dans le même espace de noms, ce qui signifie que leurs ressources d’abonnement sont situées dans le même espace de noms, que les opérateurs associés. Bien qu’ils ne soient pas réellement liés, OLM considère leurs états, tels que leur version et leur politique de mise à jour, lorsque l’un d’entre eux est mis à jour.
Ce comportement par défaut se manifeste de deux façons:
- Les ressources InstallPlan des mises à jour en attente incluent les ressources ClusterServiceVersion (CSV) de tous les autres opérateurs qui se trouvent dans le même espace de noms.
- Dans le même espace de noms, tous les opérateurs partagent la même stratégie de mise à jour. À titre d’exemple, si un opérateur est configuré sur des mises à jour manuelles, toutes les politiques de mise à jour des autres opérateurs sont également définies sur manuel.
Ces scénarios peuvent entraîner les problèmes suivants:
- Il devient difficile de raisonner au sujet des plans d’installation pour les mises à jour de l’opérateur, car il y a beaucoup plus de ressources définies en eux que l’opérateur mis à jour.
- Il devient impossible d’avoir certains opérateurs dans une mise à jour de l’espace de noms automatiquement tandis que d’autres sont mis à jour manuellement, ce qui est un désir commun pour les administrateurs de clusters.
Ces problèmes apparaissent généralement parce que, lors de l’installation d’opérateurs avec le service Red Hat OpenShift sur la console Web AWS, le comportement par défaut installe des opérateurs qui prennent en charge le mode d’installation de Tous les espaces de noms dans l’espace de noms global openshift-operators par défaut.
En tant qu’administrateur avec le rôle admin dédié, vous pouvez contourner ce comportement par défaut manuellement en utilisant le flux de travail suivant:
- Créer un projet pour l’installation de l’opérateur.
- Créez un groupe d’opérateurs mondial personnalisé, qui est un groupe d’opérateurs qui surveille tous les espaces de noms. En associant ce groupe d’opérateurs à l’espace de noms que vous venez de créer, il fait de l’espace de noms d’installation un espace de noms global, ce qui rend les opérateurs installés là-bas disponibles dans tous les espaces de noms.
- Installez l’opérateur souhaité dans l’espace de noms d’installation.
Lorsque l’opérateur a des dépendances, les dépendances sont automatiquement installées dans l’espace de noms pré-créé. En conséquence, il est alors valable pour les opérateurs de dépendance d’avoir la même stratégie de mise à jour et des plans d’installation partagés. Dans le cadre d’une procédure détaillée, voir « Installation des opérateurs mondiaux dans des espaces de noms personnalisés ».
2.4.7. Conditions de l’opérateur
Ce guide décrit comment le gestionnaire de cycle de vie de l’opérateur (OLM) utilise les conditions de l’opérateur.
2.4.7.1. À propos des conditions de l’opérateur
Dans le cadre de son rôle dans la gestion du cycle de vie d’un opérateur, Operator Lifecycle Manager (OLM) infère l’état d’un opérateur à partir de l’état des ressources Kubernetes qui définissent l’opérateur. Bien que cette approche fournisse un certain niveau d’assurance qu’un exploitant est dans un état donné, il existe de nombreux cas où un opérateur pourrait avoir besoin de communiquer des informations à OLM qui ne pourraient pas être déduits autrement. Ces informations peuvent ensuite être utilisées par OLM pour mieux gérer le cycle de vie de l’opérateur.
L’ODM fournit une définition de ressource personnalisée (CRD) appelée OperatorCondition qui permet aux opérateurs de communiquer les conditions à OLM. Il existe un ensemble de conditions supportées qui influencent la gestion de l’opérateur par OLM lorsqu’elles sont présentes dans la gamme Spec.Conditions d’une ressource OperatorCondition.
Le tableau Spec.Conditions n’est pas présent dans un objet OperatorCondition tant qu’il n’est pas ajouté par un utilisateur ou à la suite de la logique personnalisée de l’opérateur.
2.4.7.2. Conditions prises en charge
Gestionnaire de cycle de vie de l’opérateur (OLM) prend en charge les conditions suivantes de l’opérateur.
2.4.7.2.1. Condition de mise à niveau
La condition de l’opérateur mis à niveau empêche une version existante de service de cluster (CSV) d’être remplacée par une version plus récente du CSV. Cette condition est utile lorsque:
- L’opérateur est sur le point de démarrer un processus critique et ne doit pas être mis à niveau tant que le processus n’est pas terminé.
- L’opérateur effectue une migration de ressources personnalisées (CR) qui doit être complétée avant que l’opérateur ne soit prêt à être mis à niveau.
La mise à niveau de la condition de l’opérateur sur la valeur False n’évite pas la perturbation de la pod. Dans le cas où vous devez vous assurer que vos pods ne sont pas perturbés, consultez « Utiliser les budgets de perturbation de pods pour spécifier le nombre de gousses qui doivent être en hausse » et « Termination Grace » dans la section « Ressources supplémentaires ».
Exemple État de l’opérateur mis à niveau
apiVersion: operators.coreos.com/v1
kind: OperatorCondition
metadata:
name: my-operator
namespace: operators
spec:
conditions:
- type: Upgradeable
status: "False"
reason: "migration"
message: "The Operator is performing a migration."
lastTransitionTime: "2020-08-24T23:15:55Z"2.4.8. Gestion du cycle de vie de l’opérateur
2.4.8.1. Les métriques exposées
Le gestionnaire de cycle de vie de l’opérateur (OLM) expose certaines ressources spécifiques aux OLM destinées à être utilisées par le service Red Hat OpenShift basé sur Prometheus sur la pile de surveillance de cluster AWS.
| Le nom | Description |
|---|---|
|
| Le nombre de sources de catalogue. |
|
| État d’une source de catalogue. La valeur 1 indique que la source du catalogue est dans un état READY. La valeur de 0 indique que la source du catalogue n’est pas dans un état READY. |
|
| Lors de la réconciliation d’une version de service cluster (CSV), présentez chaque fois qu’une version CSV est dans un état autre que Succeed, par exemple lorsqu’elle n’est pas installée. Inclut le nom, l’espace de noms, la phase, la raison et les étiquettes de version. Lorsque cette métrique est présente, une alerte Prometheus est créée. |
|
| Le nombre de CSV enregistrés avec succès. |
|
| Lors de la réconciliation d’un CSV, représente si une version CSV est dans un état Succeed (valeur 1) ou non (valeur 0). Inclut le nom, l’espace de noms et les étiquettes de version. |
|
| Comptage monotonique des mises à niveau CSV. |
|
| Le nombre de plans d’installation. |
|
| Compte monotone des avertissements générés par les ressources, telles que les ressources dépréciées, inclus dans un plan d’installation. |
|
| La durée d’une tentative de résolution de dépendance. |
|
| Le nombre d’abonnements. |
|
| Comptage monotonique des synchronisations d’abonnement. Inclut le canal, les étiquettes CSV installées et les étiquettes de nom d’abonnement. |
2.4.9. Gestion Webhook dans Operator Lifecycle Manager
Les webhooks permettent aux auteurs de l’opérateur d’intercepter, de modifier et d’accepter ou de rejeter des ressources avant qu’elles ne soient enregistrées dans le magasin d’objets et traitées par le contrôleur de l’opérateur. Le gestionnaire de cycle de vie de l’opérateur (OLM) peut gérer le cycle de vie de ces webhooks lorsqu’ils sont expédiés aux côtés de votre opérateur.
Consultez Définir les versions de services de cluster (CSV) pour plus de détails sur la façon dont un développeur d’opérateur peut définir des webhooks pour son opérateur, ainsi que des considérations lors de l’exécution sur OLM.