18.5. Didacticiel: Vérification de la santé
Il est possible de voir comment Kubernetes réagit à l’échec de la pod en plantant intentionnellement votre gousse et en le rendant insensible aux sondes de vivacité Kubernetes.
18.5.1. La préparation de votre bureau
Divisez votre écran de bureau entre la console Web OpenShift et la console Web de l’application OSToy afin que vous puissiez voir immédiatement les résultats de vos actions.
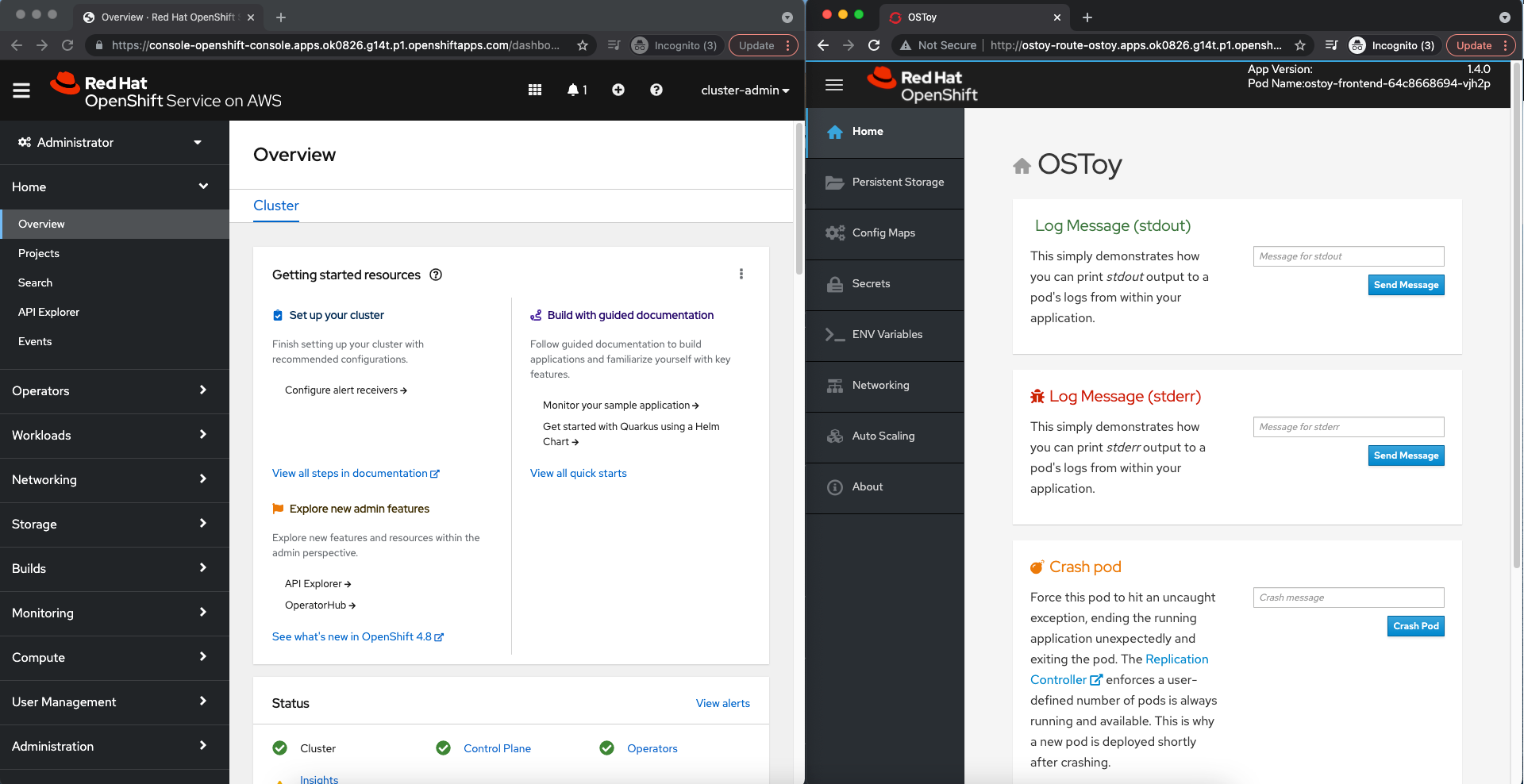
Lorsque vous ne pouvez pas diviser votre écran, ouvrez la console Web de l’application OSToy dans un autre onglet afin que vous puissiez passer rapidement à la console Web OpenShift après avoir activé les fonctionnalités de l’application.
Dans la console Web OpenShift, sélectionnez Charges de travail > Déploiements > ostoy-frontend pour afficher le déploiement OSToy.

18.5.2. Écraser la gousse
- À partir de la console Web de l’application OSToy, cliquez sur Accueil dans le menu de gauche, et entrez un message dans la boîte Crash Pod, par exemple, C’est au revoir!.
Cliquez sur Crash Pod.
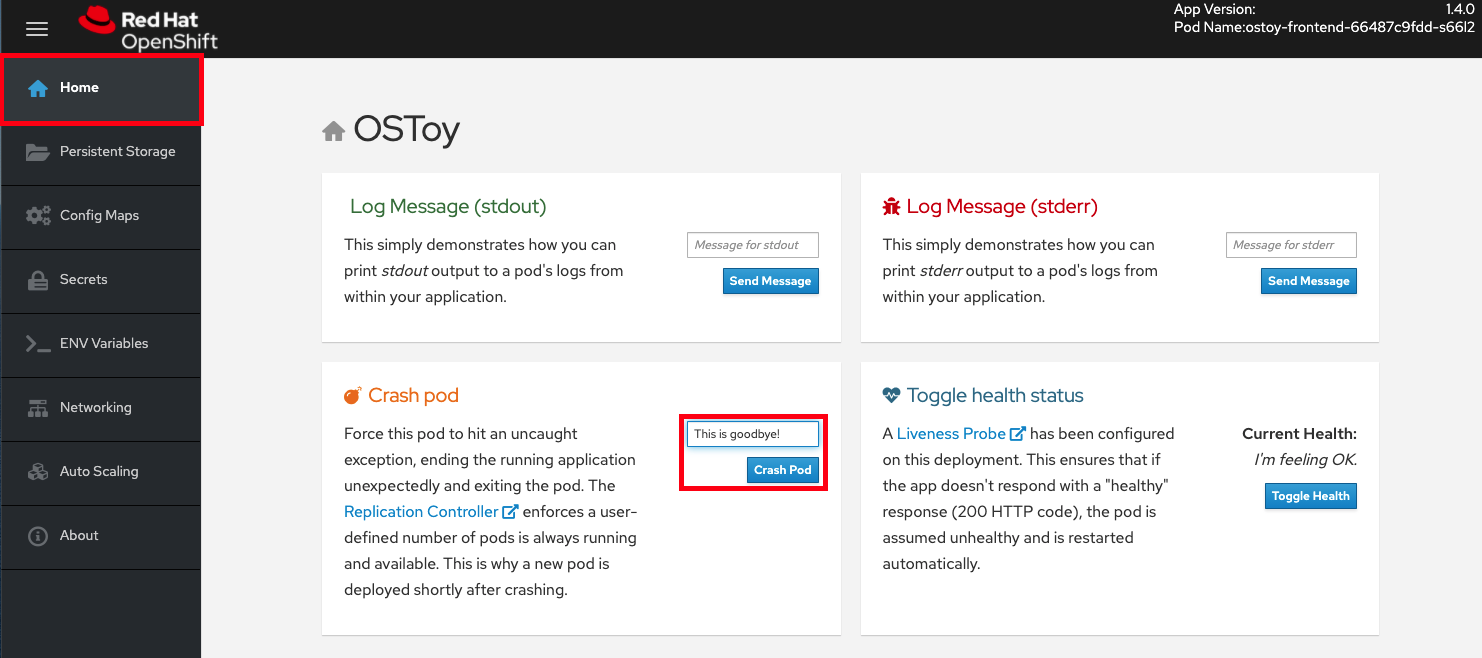
La gousse s’écrase et les Kubernetes devraient redémarrer la gousse.
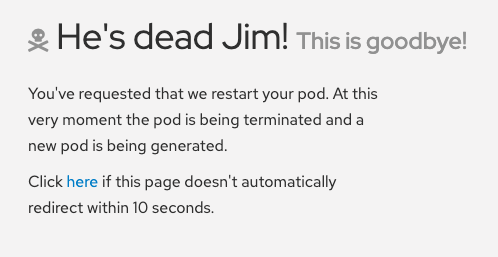
18.5.3. Affichage de la gousse relancée
À partir de la console Web OpenShift, passez rapidement à l’écran Déploiements. « vous verrez que la gousse devient jaune, ce qui signifie qu’elle est en baisse. Il devrait rapidement revivre et devenir bleu. Le processus de réveil se produit rapidement afin que vous puissiez le manquer.

La vérification
À partir de la console Web, cliquez sur Pods > ostoy-frontend-xxxxxxx-xxxx pour changer à l’écran des pods.
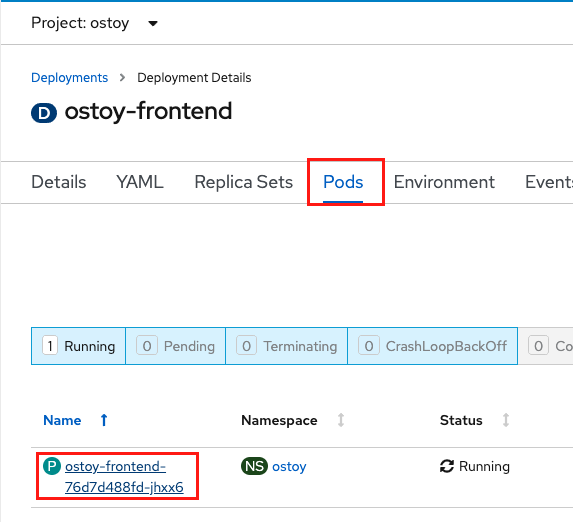
Cliquez sur le sous-onglet Événements et vérifiez que le conteneur s’est écrasé et redémarré.

18.5.4. Faire le mauvais fonctionnement de l’application
Gardez la page d’événements de pod ouverte à partir de la procédure précédente.
À partir de l’application OSToy, cliquez sur Toggle Health in the Toggle Health Status tile. La santé actuelle passe à je ne me sens pas si bien.

La vérification
Après l’étape précédente, l’application cesse de répondre avec un code HTTP 200. Après 3 échecs consécutifs, Kubernetes arrêtera le pod et le redémarrera. De la console Web, retournez à la page des événements de pod et vous verrez que la sonde de vivacité a échoué et que le pod a redémarré.
L’image suivante montre un exemple de ce que vous devriez voir sur la page des événements de votre pod.

A. La gousse a trois échecs consécutifs.
B. Kubernetes arrête le pod.
C. Kubernetes redémarre le pod.