1.4.2.3. 클러스터 Operator 업데이트 기간의 예
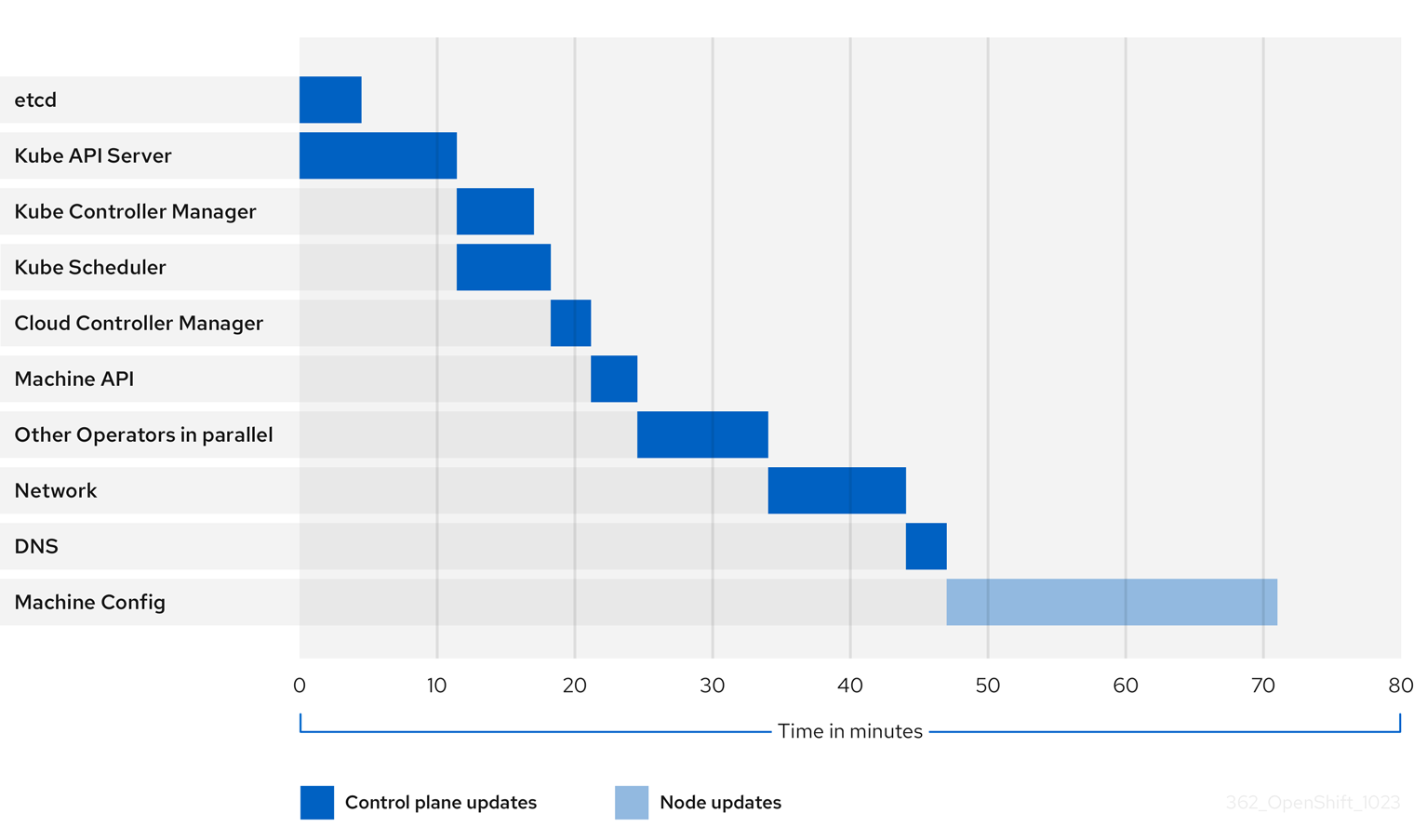
이전 다이어그램에서는 클러스터 Operator가 새 버전으로 업데이트하는 데 사용할 수 있는 시간의 예를 보여줍니다. 이 예제에서는 정상 컴퓨팅 MachineConfigPool 이 있고 4.13에서 4.14로 업데이트하는 데 오래 걸리는 워크로드가 없는 3-노드 AWS OVN 클러스터를 기반으로 합니다.
- 클러스터 및 Operator의 특정 업데이트 기간은 대상 버전, 노드 양, 노드에 예약된 워크로드 유형과 같은 여러 클러스터 특성에 따라 달라질 수 있습니다.
- Cluster Version Operator와 같은 일부 Operator는 짧은 시간 내에 자체적으로 업데이트합니다. 이러한 Operator는 다이어그램에서 생략되었거나 "Other Operators in parallel"이라는 광범위한 Operator 그룹에 포함되어 있습니다.
각 클러스터 Operator에는 자체 업데이트하는 데 걸리는 시간에 영향을 미치는 특성이 있습니다. 예를 들어 kube-apiserver 가 정상 종료 지원을 제공하므로 이 예제의 Kube API Server Operator는 업데이트하는 데 11분 이상 걸렸습니다. 즉 기존의 in-flight 요청이 정상적으로 완료될 수 있습니다. 이로 인해 kube-apiserver 가 더 오래 종료될 수 있습니다. 이 Operator의 경우 업데이트 속도가 향상되어 업데이트 중에 클러스터 기능 중단을 방지하고 제한하는 데 도움이 됩니다.
Operator의 업데이트 기간에 영향을 미치는 또 다른 특성은 Operator가 DaemonSets를 사용하는지 여부입니다. 네트워크 및 DNS Operator는 전체 클러스터 DaemonSet을 사용하므로 버전 변경 사항을 롤아웃하는 데 시간이 걸릴 수 있으며 이러한 Operator가 자체 업데이트하는 데 시간이 더 오래 걸릴 수 있는 몇 가지 이유 중 하나입니다.
일부 Operator의 업데이트 기간은 클러스터 자체의 특성에 따라 크게 달라집니다. 예를 들어 Machine Config Operator 업데이트는 클러스터의 각 노드에 머신 구성 변경 사항을 적용합니다. 많은 노드가 있는 클러스터에는 노드가 적은 클러스터에 비해 Machine Config Operator의 업데이트 기간이 길어집니다.
각 클러스터 Operator에는 업데이트할 수 있는 단계가 할당됩니다. 동일한 단계 내의 Operator는 동시에 업데이트할 수 있으며 지정된 단계의 Operator는 이전 단계가 모두 완료될 때까지 업데이트를 시작할 수 없습니다. 자세한 내용은 "추가 리소스" 섹션의 "업데이트 중에 매니페스트를 적용하는 방법 이해"를 참조하십시오.