13.2.22.2. 最も近いレプリカからのメッセージの消費
ラックアウェアネスをコンシューマーで使用して、最も近いレプリカからデータを取得することもできます。これは、Kafka クラスターが複数のデータセンターにまたがる場合に、ネットワークの負荷を軽減するのに役立ちます。また、パブリッククラウドで Kafka を実行する場合にコストを削減することもできます。ただし、レイテンシーが増加する可能性があります。
最も近いレプリカから利用するためには、Kafkaクラスターでラックアウェアが設定されており、RackAwareReplicaSelectorが有効になっている必要があります。レプリカセレクタープラグインは、クライアントが最も近いレプリカから消費できるようにするロジックを提供します。デフォルトの実装では、LeaderSelectorを使って、常にクライアントのリーダーレプリカを選択します。replica.selector.classにRackAwareReplicaSelectorを指定すると、デフォルトの実装から切り替わります。
レプリカ対応セレクタを有効にしたrack構成例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
topologyKey: topology.kubernetes.io/zone
config:
# ...
replica.selector.class: org.apache.kafka.common.replica.RackAwareReplicaSelector
# ...
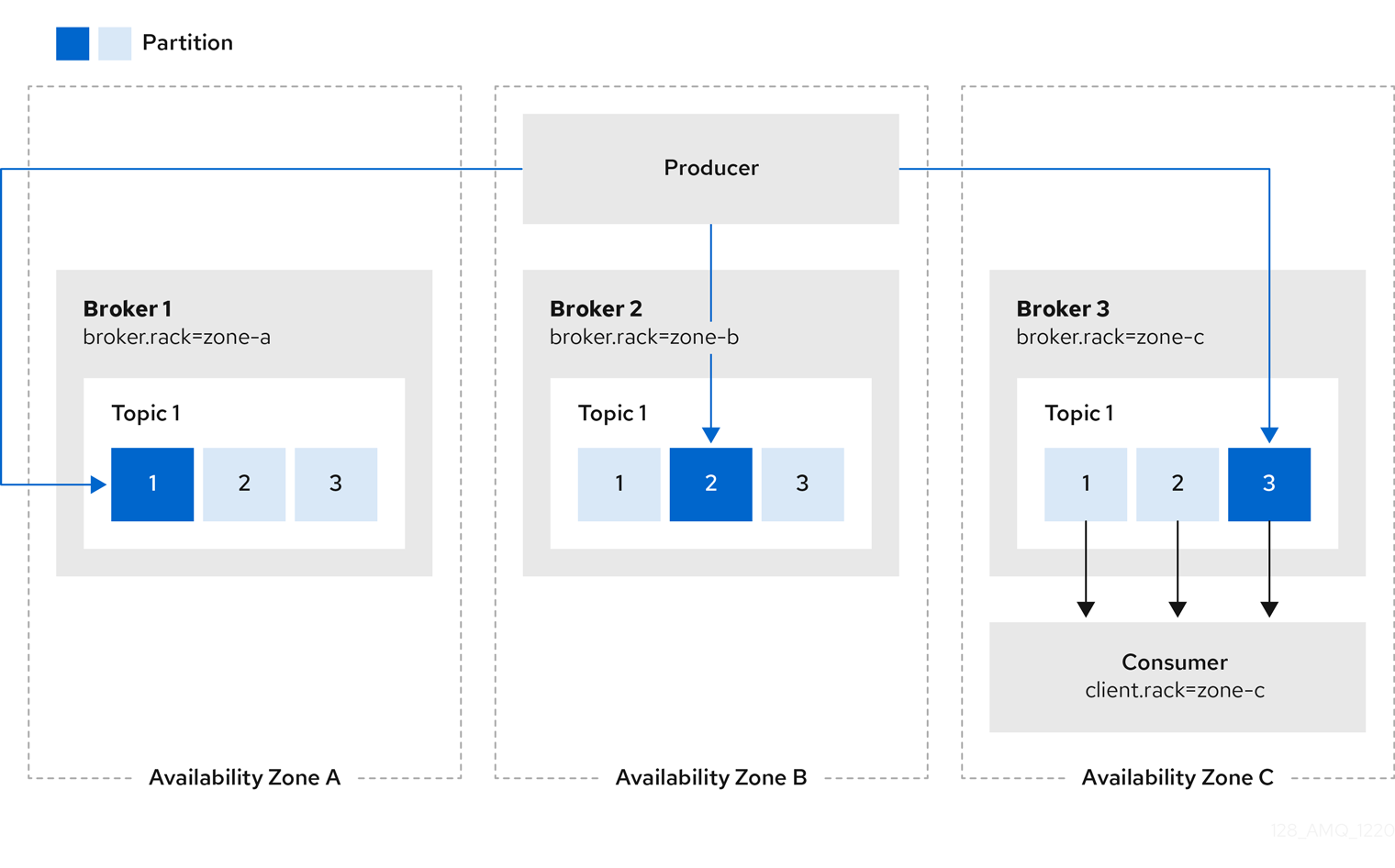
Kafkaブローカーの設定に加えて、コンシューマーにclient.rackオプションを指定する必要があります。client.rackオプションには、コンシューマーが稼動しているrack IDを指定する必要があります。RackAwareReplicaSelectorは、マッチングしたbroker.rackとclient.rackIDを関連付けて、最も近いレプリカを見つけ、そこからデータを取得します。同じラック内に複数のレプリカがある場合、RackAwareReplicaSelectorは常に最新のレプリカを選択します。ラック ID が指定されていない場合や、同じラック ID を持つレプリカが見つからない場合は、リーダーレプリカにフォールバックします。
図13.1 同じアベイラビリティーゾーンのレプリカから消費するクライアントの例
最も近いレプリカからメッセージを消費することは、メッセージを消費しているシンクコネクターの Kafka Connect でも行えます。AMQ Streamsを使用してKafka Connectを展開する場合、KafkaConnect または KafkaConnectS2I カスタムリソースのrackセクションを使用して、client.rack オプションを自動的に設定することができます。
Kafka Connectのrack設定例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
# ...
spec:
kafka:
# ...
rack:
topologyKey: topology.kubernetes.io/zone
# ...
KafkaConnect または KafkaConnectS2I のカスタムリソースで rack awareness を有効にすると、アフィニティルールは設定されませんが、affinity または topologySpreadConstraintsも設定できます。詳細は、「Pod スケジューリングの設定」 を参照してください。