2.5. トラブルシューティング
移行用のカスタムリソース (CR) を表示し、ログをダウンロードして失敗した移行の失敗についてのトラブルシューティングを行うことができます。
移行の失敗時にアプリケーションが停止した場合は、データ破損を防ぐために手作業でアプリケーションをロールバックする必要があります。
移行時にアプリケーションが停止しなかった場合には、手動のロールバックは必要ありません。元のアプリケーションがソースクラスター上で依然として実行されているためです。
2.5.1. 移行カスタムリソース (CR) の表示
Cluster Application Migration (CAM) ツールは移行用に以下の CR を作成します。
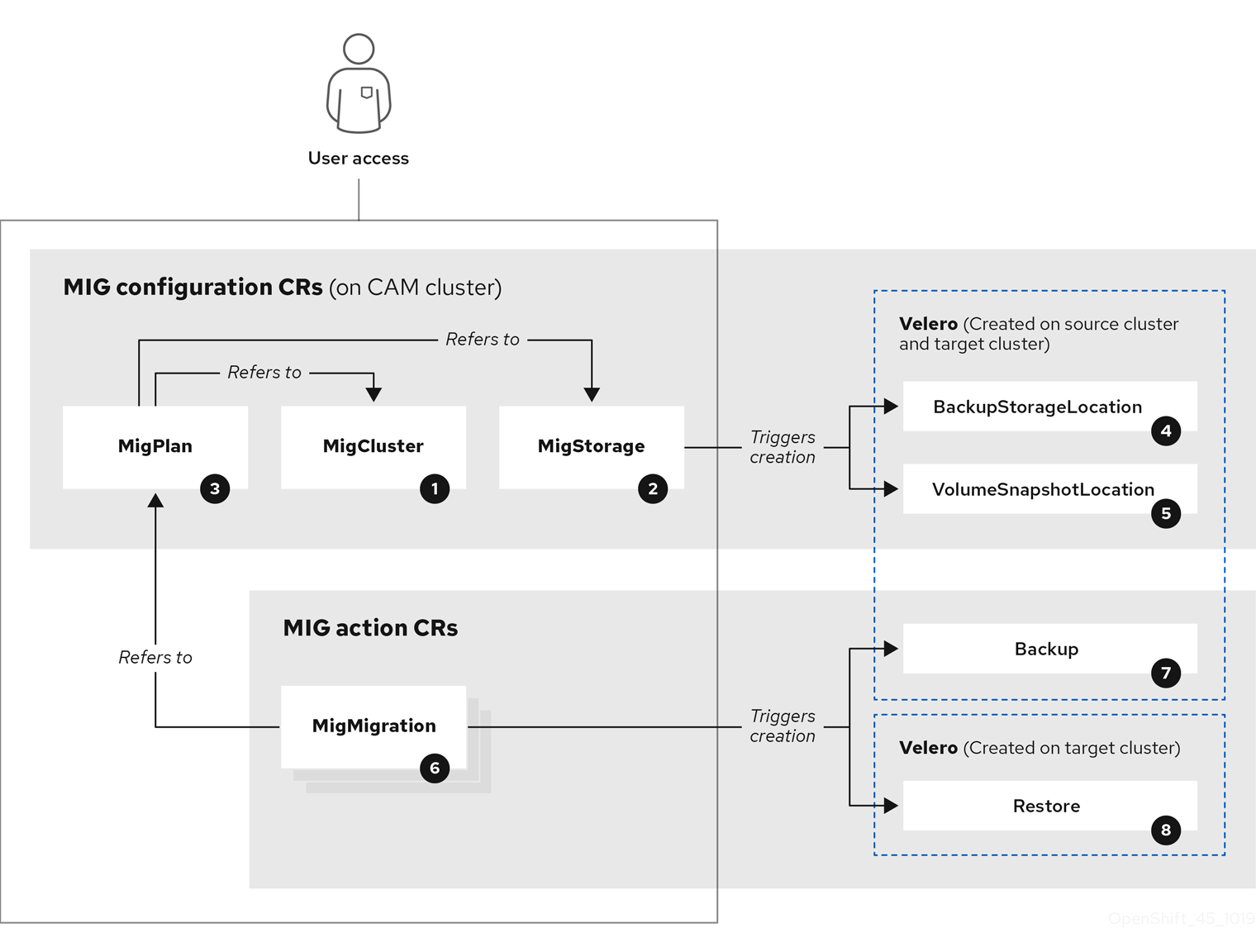
![]() MigCluster (設定、 CAM クラスター): クラスター定義
MigCluster (設定、 CAM クラスター): クラスター定義
![]() MigStorage (設定、CAM クラスター): ストレージ定義
MigStorage (設定、CAM クラスター): ストレージ定義
![]() MigPlan (設定、CAM クラスター): 移行計画
MigPlan (設定、CAM クラスター): 移行計画
MigPlan CR は移行されるソースおよびターゲットクラスター、リポジトリー、および namespace を記述します。これは 0、1 または多数の MigMigration CR に関連付けられます。
MigPlan CR を削除すると、関連付けられた MigMigration CR が削除されます。
![]() BackupStorageLocation (設定、CAM クラスター): Velero バックアップオブジェクトの場所
BackupStorageLocation (設定、CAM クラスター): Velero バックアップオブジェクトの場所
![]() VolumeSnapshotLocation (設定、CAM クラスター): ボリュームスナップショットの場所
VolumeSnapshotLocation (設定、CAM クラスター): ボリュームスナップショットの場所
![]() MigMigration (アクション、CAM クラスター): 移行、移行時に作成される
MigMigration (アクション、CAM クラスター): 移行、移行時に作成される
MigMigration CR は、データのステージングまたは移行を実行するたびに作成されます。各 MigMigration CR は MigPlan CR に関連付けられます。
![]() Backup (アクション、ソースクラスター): 移行計画の実行時に、MigMigration CR は各ソースクラスターに 2 つの Velero バックアップ CR を作成します。
Backup (アクション、ソースクラスター): 移行計画の実行時に、MigMigration CR は各ソースクラスターに 2 つの Velero バックアップ CR を作成します。
- Kubernetes オブジェクトのバックアップ CR #1
- PV データのバックアップ CR #2
![]() Restore (アクション、ターゲットクラスター): 移行計画の実行時に、MigMigration CR はターゲットクラスターに 2 つのリストア CR を作成します。
Restore (アクション、ターゲットクラスター): 移行計画の実行時に、MigMigration CR はターゲットクラスターに 2 つのリストア CR を作成します。
- PV データのリストア CR #1 (バックアップ CR #2 の使用)
- Kubernetes オブジェクトのリストア CR #2 (バックアップ CR #1 の使用)
手順
CR 名を取得します。
$ oc get <cr> -n openshift-migration1 NAME AGE 88435fe0-c9f8-11e9-85e6-5d593ce65e10 6m42s- 1
- 表示する移行 CR を指定します。
CR を表示します。
$ oc describe <cr> 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migration出力は以下の例のようになります。
MigMigration の例
$ oc describe migmigration 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migration
Name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10
Namespace: openshift-migration
Labels: <none>
Annotations: touch: 3b48b543-b53e-4e44-9d34-33563f0f8147
API Version: migration.openshift.io/v1alpha1
Kind: MigMigration
Metadata:
Creation Timestamp: 2019-08-29T01:01:29Z
Generation: 20
Resource Version: 88179
Self Link: /apis/migration.openshift.io/v1alpha1/namespaces/openshift-migration/migmigrations/88435fe0-c9f8-11e9-85e6-5d593ce65e10
UID: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
Spec:
Mig Plan Ref:
Name: socks-shop-mig-plan
Namespace: openshift-migration
Quiesce Pods: true
Stage: false
Status:
Conditions:
Category: Advisory
Durable: true
Last Transition Time: 2019-08-29T01:03:40Z
Message: The migration has completed successfully.
Reason: Completed
Status: True
Type: Succeeded
Phase: Completed
Start Timestamp: 2019-08-29T01:01:29Z
Events: <none>Velero バックアップ CR #2 の例 (PV データ)
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.105.179:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-44dd3bd5-c9f8-11e9-95ad-0205fe66cbb6
creationTimestamp: "2019-08-29T01:03:15Z"
generateName: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-
generation: 1
labels:
app.kubernetes.io/part-of: migration
migmigration: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
migration-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
velero.io/storage-location: myrepo-vpzq9
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
namespace: openshift-migration
resourceVersion: "87313"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/backups/88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
uid: c80dbbc0-c9f8-11e9-95ad-0205fe66cbb6
spec:
excludedNamespaces: []
excludedResources: []
hooks:
resources: []
includeClusterResources: null
includedNamespaces:
- sock-shop
includedResources:
- persistentvolumes
- persistentvolumeclaims
- namespaces
- imagestreams
- imagestreamtags
- secrets
- configmaps
- pods
labelSelector:
matchLabels:
migration-included-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
storageLocation: myrepo-vpzq9
ttl: 720h0m0s
volumeSnapshotLocations:
- myrepo-wv6fx
status:
completionTimestamp: "2019-08-29T01:02:36Z"
errors: 0
expiration: "2019-09-28T01:02:35Z"
phase: Completed
startTimestamp: "2019-08-29T01:02:35Z"
validationErrors: null
version: 1
volumeSnapshotsAttempted: 0
volumeSnapshotsCompleted: 0
warnings: 0Velero リストア CR #2 の例 (Kubernetes リソース)
apiVersion: velero.io/v1
kind: Restore
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.90.187:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-36f54ca7-c925-11e9-825a-06fa9fb68c88
creationTimestamp: "2019-08-28T00:09:49Z"
generateName: e13a1b60-c927-11e9-9555-d129df7f3b96-
generation: 3
labels:
app.kubernetes.io/part-of: migration
migmigration: e18252c9-c927-11e9-825a-06fa9fb68c88
migration-final-restore: e18252c9-c927-11e9-825a-06fa9fb68c88
name: e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
namespace: openshift-migration
resourceVersion: "82329"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/restores/e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
uid: 26983ec0-c928-11e9-825a-06fa9fb68c88
spec:
backupName: e13a1b60-c927-11e9-9555-d129df7f3b96-sz24f
excludedNamespaces: null
excludedResources:
- nodes
- events
- events.events.k8s.io
- backups.velero.io
- restores.velero.io
- resticrepositories.velero.io
includedNamespaces: null
includedResources: null
namespaceMapping: null
restorePVs: true
status:
errors: 0
failureReason: ""
phase: Completed
validationErrors: null
warnings: 152.5.2. 移行ログのダウンロード
CAM Web コンソールで Velero、Restic、および Migration コントローラーログをダウンロードして、移行の失敗についてのトラブルシューティングを行うことができます。
手順
- CAM Web コンソールにログインします。
- Plans をクリックし、 移行計画の一覧を表示します。
-
Options メニュー
 をクリックし (特定の移行計画について)、Logs を選択します。
をクリックし (特定の移行計画について)、Logs を選択します。
- Download Logs をクリックし、すべてのクラスターの Migration コントローラー、Velero、および Restic のログをダウンロードします。
特定のログをダウンロードするには、以下を実行します。
ログオプションを指定します。
- Cluster: ソース、ターゲット、または CAM ホストクラスターを選択します。
- Log source: Velero、Restic、または Controller を選択します。
Pod source: Pod 名を選択します (例:
controller-manager-78c469849c-v6wcf)。選択したログが表示されます。
選択した内容を変更することで、ログ選択の設定をクリアできます。
- Download Selected をクリックし、選択したログをダウンロードします。
オプションで、以下の例にあるように CLI を使用してログにアクセスできます。
$ oc get pods -n openshift-migration | grep controller
controller-manager-78c469849c-v6wcf 1/1 Running 0 4h49m
$ oc logs controller-manager-78c469849c-v6wcf -f -n openshift-migration2.5.3. Restic タイムアウトエラー
Restic のタイムアウトにより移行が失敗する場合、以下のエラーが Velero ログに表示されます。
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete" error.file="/go/src/github.com/heptio/velero/pkg/restic/backupper.go:165" error.function="github.com/heptio/velero/pkg/restic.(*backupper).BackupPodVolumes" group=v1
restic_timeout のデフォルト値は 1 時間です。大規模な移行では、この値を大きくすることができます。値を高くすると、エラーメッセージが返されるタイミングが送れる可能性があることに注意してください。
手順
-
OpenShift Container Platform Web コンソールで、Operators
Installed Operators に移動します。 - Cluster Application Migration Operator をクリックします。
- MigrationController タブで、migration-controller をクリックします。
YAML タブで、以下のパラメーター値を更新します。
spec: restic_timeout: 1h1 - 1
- 有効な単位は
h(時間)、m(分)、およびs(秒) です (例:3h30m15s)。
- Save をクリックします。
2.5.4. 移行の手動ロールバック
移行の失敗時にアプリケーションが停止された場合は、PV でのデータの破損を防ぐために手動でこれをロールバックする必要があります。
移行時にアプリケーションが停止しなかった場合には、この手順は必要ありません。元のアプリケーションがソースクラスター上で依然として実行されているためです。
手順
ターゲットクラスター上で、移行したプロジェクトに切り替えます。
$ oc project <project>デプロイされたリソースを取得します。
$ oc get allデプロイされたリソースを削除し、アプリケーションがターゲットクラスターで実行されておらず、PVC 上にあるデータにアクセスできるようにします。
$ oc delete <resource_type>これを削除せずに DaemonSet を停止するには、YAML ファイルで
nodeSelectorを更新します。apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: hello-daemonset spec: selector: matchLabels: name: hello-daemonset template: metadata: labels: name: hello-daemonset spec: nodeSelector: role: worker1 - 1
- いずれのノードにも存在しない
nodeSelector値を指定します。
不要なデータが削除されるように、各 PV の回収ポリシーを更新します。移行時に、バインドされた PV の回収ポリシーは
Retainであり、アプリケーションがソースクラスターから削除される際にデータの損失が生じないようにされます。ロールバック時にこれらの PV を削除できます。apiVersion: v1 kind: PersistentVolume metadata: name: pv0001 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain1 ... status: ...- 1
RecycleまたはDeleteを指定します。
ソースクラスターで、移行したプロジェクトに切り替え、そのデプロイされたリソースを取得します。
$ oc project <project> $ oc get allデプロイされた各リソースのレプリカを開始します。
$ oc scale --replicas=1 <resource_type>/<resource_name>-
手順の実行時に変更した場合は、DaemonSet の
nodeSelectorを元の値に更新します。
2.5.5. カスタマーサポートケース用のデータの収集
カスタマーサポートケースを作成する場合、 openshift-migration-must-gather-rhel8 イメージを使用して must-gather ツールを実行し、クラスターについての情報を収集し、これを Red Hat カスタマーポータルにアップロードできます。
openshift-migration-must-gather-rhel8 イメージは、デフォルトの must-gather イメージで収集されないログおよびカスタムリソースデータを収集します。
手順
-
must-gatherデータを保存するディレクトリーに移動します。 oc adm must-gatherコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/rhcam-1-2/openshift-migration-must-gather-rhel8must-gatherツールはクラスター情報を収集し、これをmust-gather.local.<uid>ディレクトリーに保存します。-
認証キーおよびその他の機密情報を
must-gatherデータから削除します。 must-gather.local.<uid>ディレクトリーの内容を含むアーカイブファイルを作成します。$ tar cvaf must-gather.tar.gz must-gather.local.<uid>/圧縮ファイルを Red Hat カスタマーポータル上のサポートケースに添付します。
2.5.6. 既知の問題
本リリースには、以下の既知の問題があります。
移行中に、CAM ツールは以下の namespace アノテーションを保持します。
-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups openshift.io/sa.scc.uid-rangeこれらのアノテーションは UID 範囲を保持し、コンテナーがターゲットクラスターのファイルシステムのパーミッションを保持できるようにします。移行された UID が、ターゲットクラスターの既存の namespace または今後の namespace 内の UID を重複させるリスクがあります。(BZ#1748440)
-
-
S3 エンドポイントを CAM Web コンソールに追加する場合、
https://は AWS でのみサポートされます。他の S3 プロバイダーの場合はhttp://を使用します。 -
AWS バケットが CAM Web コンソールに追加された後に削除される場合、MigStorage CR は更新されないため、そのステータスは
Trueのままになります。(BZ#1738564) -
Migration コントローラーが、ターゲットクラスター以外のクラスターで実行されている場合は移行に失敗します。
EnsureCloudSecretPropagatedフェーズはログに記録された警告を出して省略されます。(BZ#1757571) - クラスターのロールバインディングおよび SCC (Security Context Constraints) を含むクラスタースコープのリソースは CAM によって処理されません。アプリケーションがクラスタースコープのリソースを必要とする場合、ターゲットクラスターでそれらを手動で作成する必要があります。(BZ#1759804)
- 移行計画の作成時に、ソースクラスターのストレージクラスが誤って表示されます。(BZ#1777869)
- CAM Web コンソールのクラスターにアクセス不可の場合、これはオープン状態の移行計画のクローズを試行します。(BZ#1758269)
- 移行に失敗すると、移行計画は休止状態の Pod のカスタム PV 設定を保持しません。移行を手動でロールバックし、移行計画を削除し、PV 設定で新たな移行計画を作成する必要があります。(BZ#1784899)