第3章 ホストの推奨プラクティス
3.1. OpenShift Container Platform マスターホストの推奨プラクティス
OpenShift Container Platform インフラストラクチャーで、Pod トラフィックの他に最も使用されるデータパスは OpenShift Container Platform マスターホストと etcd 間のデータパスです。OpenShift Container Platform API サーバー (マスターバイナリーの一部) は、ノードのステータス、ネットワーク設定、シークレットなどについて etcd に確認します。
以下を実行してこのトラフィックパスを最適化します。
- マスターホストと etcd サーバーを共存させる
- マスターホスト間でレイテンシーが低く、混雑しない LAN 通信リンクを確保する
OpenShift Container Platform マスターは、CPU 負荷を軽減するためにデシリアライズされたバージョンのリソースを積極的にキャッシュします。ただし、1000 Pod 未満の小規模なクラスターでは、このキャッシュにより、無視できる程度の CPU 負荷を削減するために大量のメモリーが浪費される可能性があります。デフォルトのキャッシュサイズは 50,000 エントリーですが、リソースのサイズによっては 1 から 2 GB メモリーを占有する程度まで拡大する可能性があります。キャッシュのサイズは、/etc/origin/master/master-config.yaml で以下の設定を使用して縮小できます。
kubernetesMasterConfig:
apiServerArguments:
deserialization-cache-size:
- "1000"3.2. OpenShift Container Platform ノードホストの推奨プラクティス
/etc/origin/node/node-config.yaml にある OpenShift Container Platform ノード設定ファイルには、iptables 同期期間、SDN ネットワークの Maximum Transmission Unit (MTU)、プロキシーモードなどの重要なオプションが含まれます。
ノード設定ファイルでは、kubelet (node) プロセスに引数を渡すことができます。kubelet --help を実行すると、利用可能なオプション一覧を表示できます。
kubelet オプションは、OpenShift Container Platform ですべてサポートされておらず、アップストリームの Kubernetes ですべてが使用されている訳ではないので、オプションによってはサポートに制限があります。
/etc/origin/node/node-config.yaml ファイルでは、pods-per-core および max-pods の 2 つのパラメーターがノードにスケジュールできる Pod の最大数を制御します。オプションがどちらも使用されている場合には、2 つの内の低い値を使用して、ノードの Pod 数が制限されます。これらの値を超えると、以下の状況が発生します。
- OpenShift Container Platform と Docker の両方で CPU 使用率が上昇する。
- Pod のスケジューリングの速度が遅くなる。
- メモリー不足のシナリオが生じる可能性がある (ノードのメモリー量による)。
- IP アドレスのプールを消費する。
- リソースのオーバーコミットが起こり、ユーザーアプリケーションのパフォーマンスが低下する。
Kubernetes では、単一コンテナーを保持する Pod は実際には 2 つのコンテナーを使用します。2 つ目のコンテナーは実際のコンテナーの起動前にネットワークを設定するために使用されます。そのため、10 の Pod を実行するシステムでは、実際には 20 のコンテナーが実行されていることになります。
pods-per-core は、ノードのプロセッサーコア数に基づいてノードが実行できる Pod 数を設定します。たとえば、4 プロセッサーコアを搭載したノードで pods-per-core が 10 に設定される場合、このノードで許可される Pod の最大数は 40 になります。
kubeletArguments:
pods-per-core:
- "10"
pods-per-core を 0 に設定すると、この制限が無効になります。
max-pods は、ノードのプロパティーにかかわらず、ノードが実行できる Pod 数を固定値に設定します。
kubeletArguments:
max-pods:
- "250"
上記の例では、pods-per-core のデフォルト値は 10 であり、max-pods のデフォルト値は 250 です。これは、ノードにあるコア数が 25 以上でない場合、デフォルトでは pods-per-core が制限を設定する要素になります。
OpenShift Container Platform クラスターの推奨制限については、インストールドキュメントの「サイジングに関する考慮事項」セクションを参照してください。推奨のサイズは、コンテナーのステータス更新時の OpenShift Container Platform と Docker の連携が基になっています。このように連携されることで、大量のログデータの書き込みなど、マスターや Docker プロセスの CPU に負荷がかかります。
3.3. OpenShift Container Platform etcd ホストの推奨プラクティス
etcd は、OpenShift Container Platform が設定に使用するキーと値の分散ストアです。
|
OpenShift Container Platform のバージョン |
etcd のバージョン |
ストレージスキーマのバージョン |
|
3.3 以前 |
2.x |
v2 |
|
3.4 および 3.5 |
3.x |
v2 |
|
3.6 |
3.x |
v2 (アップグレード) |
|
3.6 |
3.x |
v3 (新規インストール) |
etcd 3.x では、クラスターのサイズに拘わらず、CPU、メモリー、ネットワーク、ディスク要件を軽減する、スケーラビリティーおよびパフォーマンスの重要な強化機能が導入されました。etcd 3.x は、on-disk etcd データベースの 2 ステップ移行を簡素化する後方互換対応のストレージ API を実装します。移行の目的で、OpenShift Container Platform 3.5 の etcd 3.x は v2 モードのままとなっています。OpenShift Container Platform 3.6 以降では、新規インストールで v3 のストレージモードが使用されます。OpenShift Container Platform の以前のバージョンからアップグレードしても、v2 から v3 に自動で 移行されません。提供されている Playbook を使用して、ドキュメントに記載のプロセスに従い、データを移行する必要があります。
etcd バージョン 3 には、on-disk etcd データベースの 2 ステップ移行を簡素化する後方互換対応のストレージ API が実装されています。移行の目的で、OpenShift Container Platform 3.5 の etcd 3.x は v2 モードのままとなっています。OpenShift Container Platform 3.6 以降では、新規インストールで v3 のストレージモードが使用されます。お客様が etcd スキーマを v2 から v3 に移行する準備 (移行に関連するダウンタイムや検証など含む) ができるように、OpenShift Container Platform 3.6 では強制的にこのアップグレードは実行されません。ただし、幅広いテストを行った結果、Red Hat は既存の OpenShift Container Platform クラスターを etcd 3.x ストレージモード v3 に移行することを強く推奨します。これは特に、大規模なクラスターを使用されている場合や、SSD ストレージを利用できないシナリオなどが該当します。
今後の OpenShift Container Platform のアップグレードでは、etcd スキーマの移行が必要です。
新規インストールでストレージモードを v3 に変更するのに加え、OpenShift Container Platform 3.6 は、全 OpenShift Container Platform タイプに対して強制的に quorum reads を実行します。これは、etcd に対するクエリーが陳腐データを返さないようにするためです。単一ノードの etcd クラスターでは、陳腐データが入っていても懸念はありませんが、実稼働クラスターで一般的に使用される、高可用性の etcd デプロイメントでは、通常、quorum read でクエリーの結果が有効であるように確保します。quorum read は、データベース用語で 線形化可能性 のことで、すべてのクライアントにクラスターが最新の状態に更新されたものが表示され、同じ順番の読み取りおよび書き込みが表示されます。パフォーマンスの向上に関する情報は、etcd 3.1 「announcement」を参照してください。
OpenShift Container Platform は、etcd を使用して Kubernetes 自体が必要な情報以外の追加情報を保存する点を留意することが重要です。たとえば、Kubernetes 以外に OpenShift Container Platform が追加する機能で必要になるので、OpenShift Container Platform は、etcd にイメージ、ビルド、他のコンポーネントの情報を保存します。最終的に、etcd ホストのパフォーマンスやサイジングに関する指針やその他の推奨事項は、Kubernetes とは大幅に異なります。Red Hat は、OpenShift Container Platform のユースケースやパラメーターを考慮に入れて etcd のスケーラビリティーやパフォーマンスをテストし、最も正確な推奨事項を提案できるようにしています。
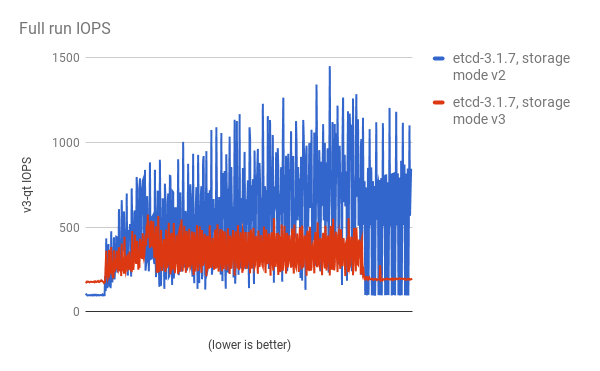
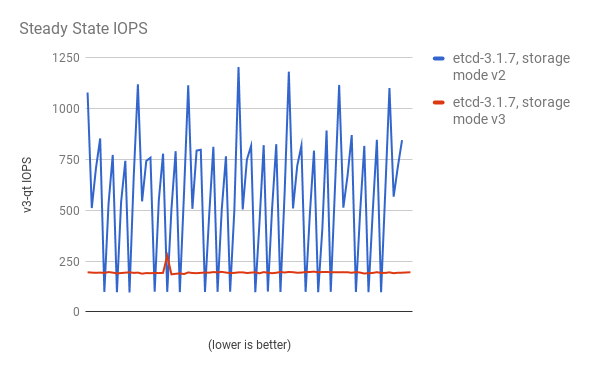
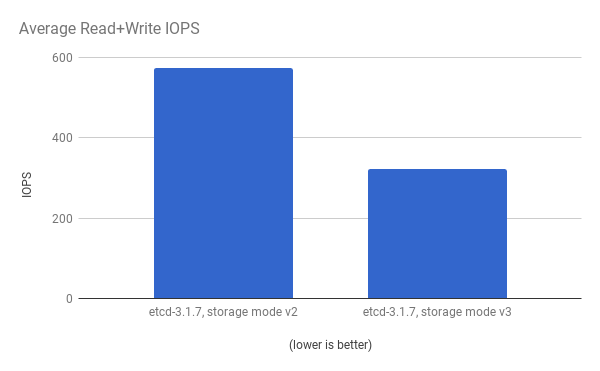
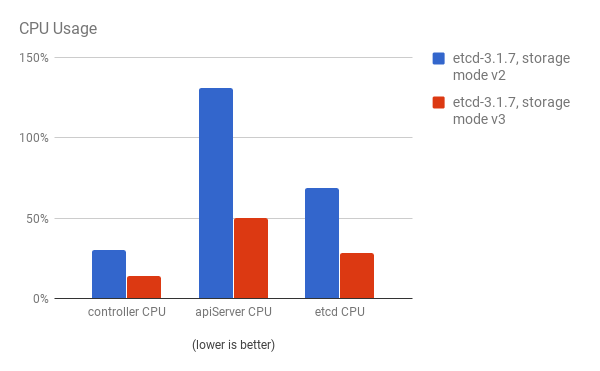
パフォーマンスの向上は、cluster-loader ユーティリティーで 300 ノードの OpenShift Container Platform 3.6 クラスターを使用して、定量化されています。etcd 3.x (ストレージモード v2) と etcd 3.x (ストレージモード v3) を比較すると、以下の図に示されるようにパフォーマンスの向上が明確に確認できます。
負荷のある状態でのストレージ IOPS が大幅に減少している:
安定した状態でのストレージ IOPS が大幅に減少している:
同じ I/O データの表示。両モードでの平均 IOPS
API サーバー (マスター) と etcd プロセスの両方の CPU 使用率が減少している:
API サーバー (マスター) と etcd プロセスの両方のメモリー使用率も減少している:

OpenShift Container Platform で etcd をプロファイリングした後に、etcd は少量のストレージインプットおよびアウトプットを頻繁に実行しています。SSD など、少量の読み取り/書き込み操作をすばやく処理するストレージで etcd を使用することを強く推奨します。
etcd 3.1 の 3 ノードクラスター (quorum reads を有効にしてストレージ v3 モードを使用) で実行したサイズ I/O 操作を確認してみると、読み取りサイズは以下のようになります。
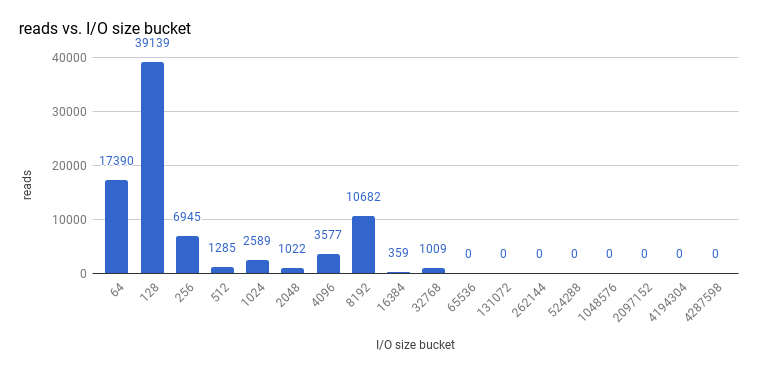
また、書き込みサイズは以下のようになります。

etcd プロセスは通常はメモリー集約型であり、マスター/ API サーバープロセスは CPU 集約型です。これらは、単一マシンや仮想マシン内で共同設置する上で有効なペアになります。etcd とマスターホスト間の通信を最適化するには、同じホストにマスターと etcd を共同設置するか、専用のネットワークを設定します。
3.3.1. OpenStack で PCI パススルーを使用した etcd ノードへのストレージ提供
大規模な環境で etcd を安定させるために etcd ノードにストレージをすばやく提供するには、NVMe (Non-Volatile Memory express) デバイスを直接 etcd ノードに渡す PCI パススルーを使用します。これを Red Hat OpenStack 11 以降で設定するには、PCI デバイスが存在する OpenStack コンピュートノードで以下を実行してください。
- Intel Vt-x が BIOS で有効化されているようにします。
-
IOMMU (Input-Output Memory Management Unit) を有効化します。/etc/sysconfig/grub ファイルで、
GRUB_CMDLINX_LINUXの行末に、引用符で囲ってintel_iommu=on iommu=ptを追加します。 以下を実行して /etc/grub2.cfg を再生成します。
$ grub2-mkconfig -o /etc/grub2.cfg- システムを再起動します。
コントローラーの /etc/nova.conf を以下のように設定します。
[filter_scheduler] enabled_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,DiskFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,PciPassthroughFilter available_filters=nova.scheduler.filters.all_filters [pci] alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }-
コントローラーで
nova-apiとnova-schedulerを再起動します。 コンピュートノードの /etc/nova/nova.conf で以下のように設定します。
[pci] passthrough_whitelist = { "address": "0000:06:00.0" } alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }パススルーする NVMe デバイスの
address、vendor_idおよびproduct_idの必須値を取得するには、以下を実行します。# lspci -nn | grep devicename-
コンピュートノードで
nova-computeを再起動します。 - 実行する OpenStack バージョンで NVMe を使用するように設定し、etcd ノードで起動します。
3.4. Tuned プロファイルを使用したホストのスケーリング
Tuned は、Red Hat Enterprise Linux (RHEL) および他の Red Hat 製品で有効な Tuning プロファイルの配信メカニズムです。Tuned は、sysctls、電源管理、カーネルコマンドラインオプションなどの Linux の設定をカスタマイズして、異なるワークロードのパフォーマンスやスケーラビリティーの要件に対応するために、オペレーティングシステムを最適化します。
OpenShift Container Platform は tuned デーモンを活用して、openshift、openshift-node および openshift-control-plane と呼ばれる Tuned プロファイルを追加します。これらのプロファイルは、カーネルで一般的に発生する垂直スケーリングの上限を安全に増やし、インストール時に自動的にシステムに適用されます。
Tuned プロファイルは、プロファイル間の継承や、プロファイルが仮想環境で使用されるかどうかにより、親プロファイルを選択する親の自動割り当て機能もサポートします。openshift プロファイルは、openshift-node と openshift-control-plane プロファイルの親で、これらの両機能を使用します。OpenShift Container Platform アプリケーションノードとコントロールプレーンノードの両方に関連するチューニングが含まれます。openshift-node および openshift-control-plane プロファイルは、アプリケーションおよびコントロールプレーンノードにそれぞれ設定されます。
openshift プロファイルがプロファイル階層の親である場合に、OpenShift Container Platform システムに配信されるチューニングは、ベアメタルホスト向けの throughput-performance (RHEL のデフォルト) と、RHEL 向けの virtual-guest または RHEL Atomic Host ノード向けの atomic-guest を組み合わせて作成されます。
お使いのシステムでどの Tuned プロファイルが有効になっているかを確認するには以下を実行します。
# tuned-adm active
Current active profile: openshift-nodeTuned に関する詳細情報は、『Red Hat Enterprise Linux パフォーマンスチューニングガイド』を参照してください。