18.5. チュートリアル: ヘルスチェック
意図的に Pod をクラッシュさせ、Kubernetes liveness プローブに応答しないようにすることで、Kubernetes が Pod の障害にどのように対応するかを確認できます。
18.5.1. デスクトップの準備
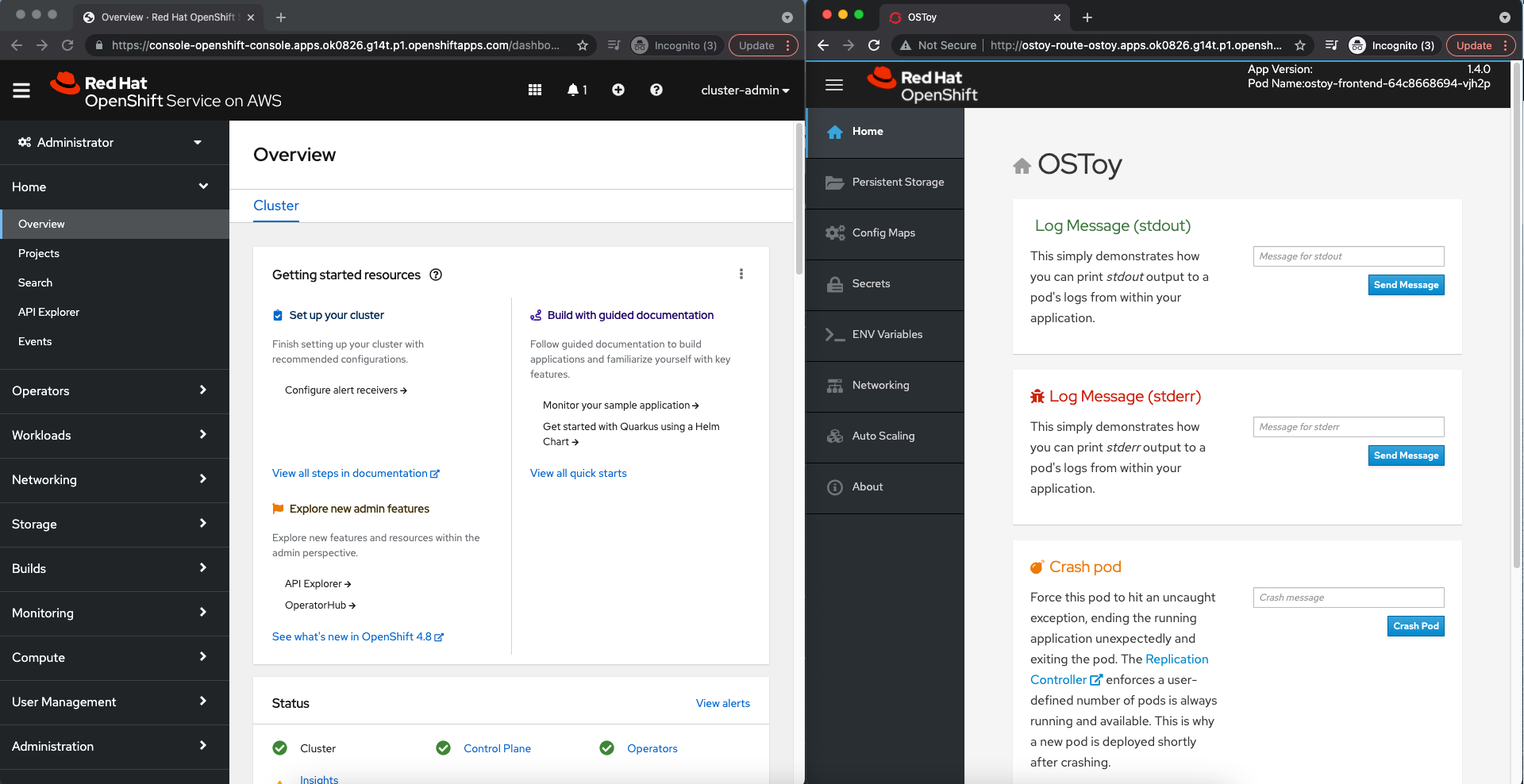
デスクトップ画面を OpenShift Web コンソールと OSToy アプリケーションの Web コンソールに分割して、アクションの結果をすぐに確認できるようにします。
画面を分割できない場合は、別のタブで OSToy アプリケーションの Web コンソールを開き、アプリケーションの機能を有効にした後で OpenShift Web コンソールにすばやく切り替えられるようにします。
OpenShift Web コンソールから、Workloads > Deployments > ostoy-frontend を選択して、OSToy デプロイメントを表示します。
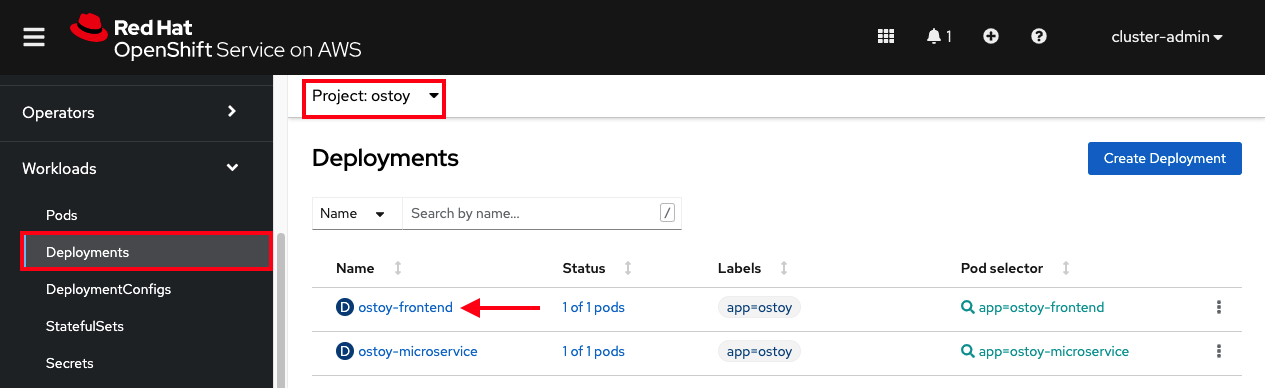
18.5.2. Pod のクラッシュ
-
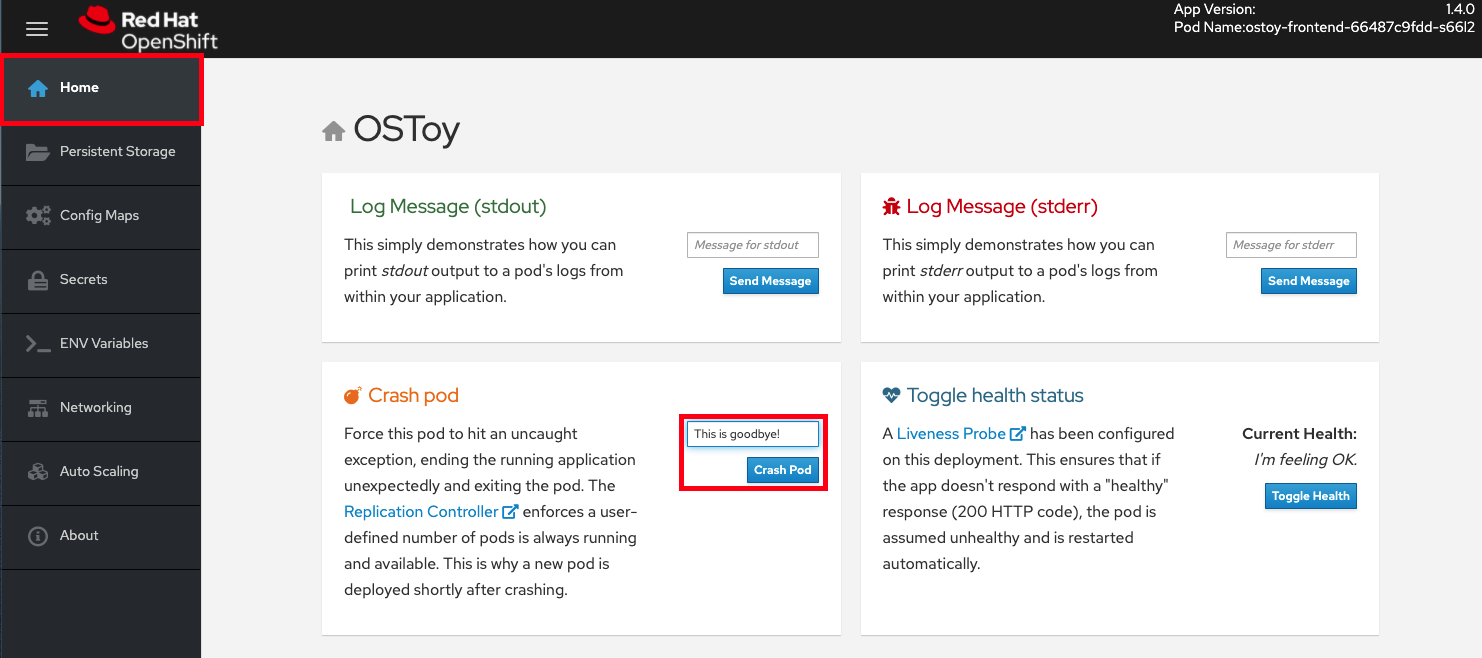
OSToy アプリケーションの Web コンソールから、左側のメニューの Home をクリックし、Crash Pod ボックスに
This is goodbye!などのメッセージを入力します。 Crash Pod をクリックします。
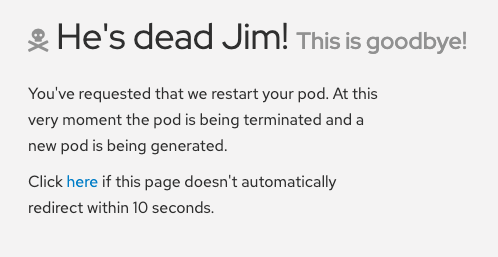
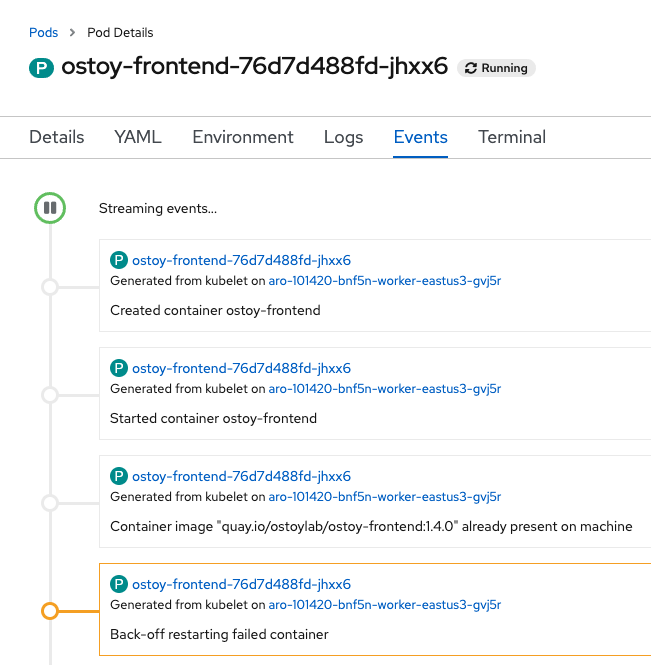
Pod がクラッシュし、Kubernetes が Pod を再起動するはずです。
18.5.3. 復活した Pod の確認
OpenShift Web コンソールから、Deployments 画面にすばやく切り替えます。Pod が黄色に変わり、ダウンしていることがわかります。すぐに復活して青色に変わるはずです。復活プロセスはすぐに行われるため、見逃さないよう注意してください。
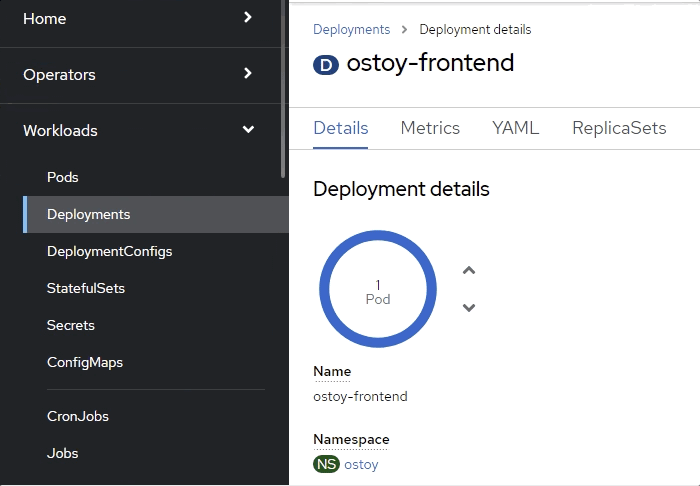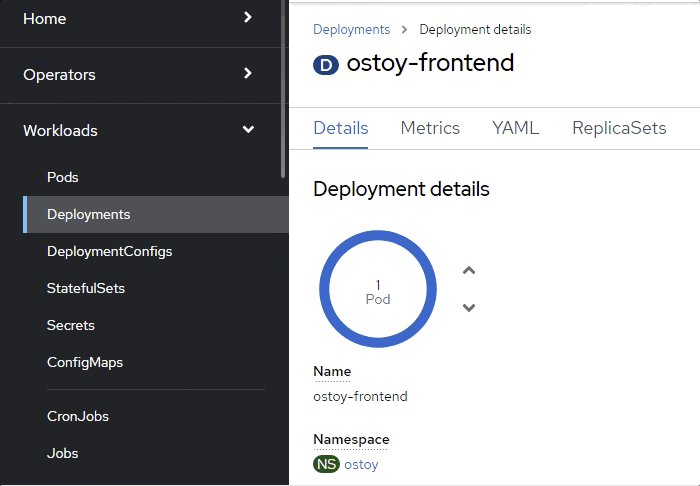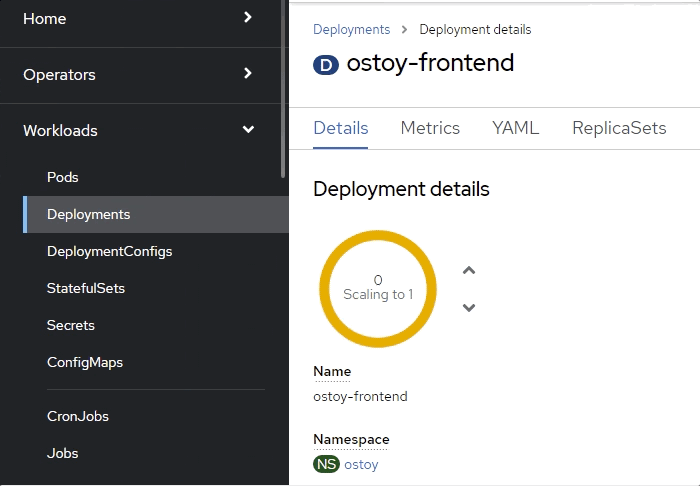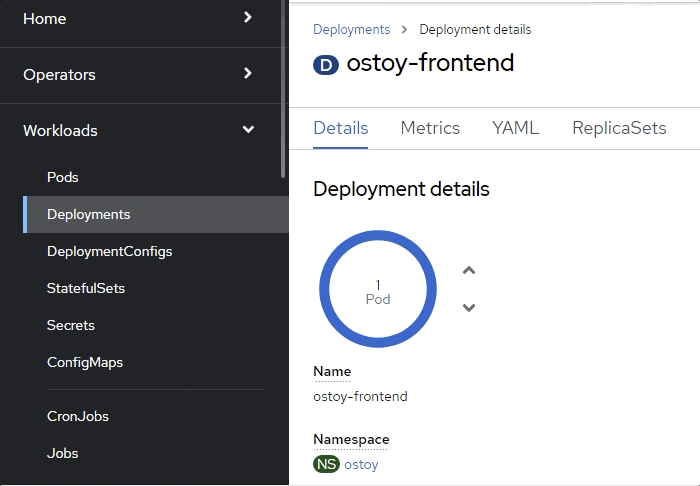
検証
Web コンソールから、Pods > ostoy-frontend-xxxxxxx-xxxx をクリックして、Pod 画面に切り替えます。
Events サブタブをクリックし、コンテナーがクラッシュして再起動したことを確認します。
18.5.4. アプリケーションを誤動作させる
前の手順の Pod イベントページを開いたままにしておきます。
OSToy アプリケーションから、Toggle Health Status タイルの Toggle Health をクリックします。Current Health 状態が I’m not feeling all that well に切り替わるのを確認します。

検証
前のステップを実行すると、アプリケーションが 200 HTTP code で応答を停止します。3 回連続して失敗すると、Kubernetes が Pod を停止して再起動します。Web コンソールから Pod イベントページに戻ると、liveness プローブが失敗し、Pod が再起動されたことがわかります。
次の画像は、Pod イベントページに表示される内容の例を示しています。
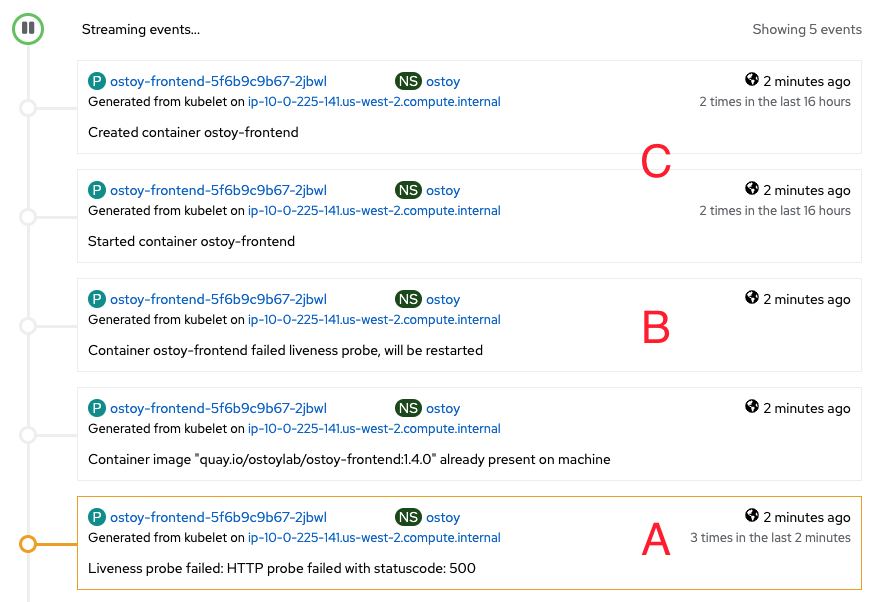
A. Pod で失敗が 3 回連続で発生しました。
B. Kubernetes が Pod を停止します。
C. Kubernetes が Pod を再起動します。