3.5. インストールのトラブルシューティング
3.5.1. インストールプログラムワークフローのトラブルシューティング
インストール環境のトラブルシューティングを行う前に、ベアメタルへの installer-provisioned installation の全体的なフローを理解することが重要です。次の図は、環境のトラブルシューティングフローをステップごとに示したものです。

ワークフロー 1/4 は、install-config.yaml ファイルにエラーがある場合や Red Hat Enterprise Linux CoreOS (RHCOS) イメージにアクセスできない場合のトラブルシューティングのワークフローを説明しています。トラブルシューティングに関する提案は、install-config.yaml のトラブルシューティング を参照してください。
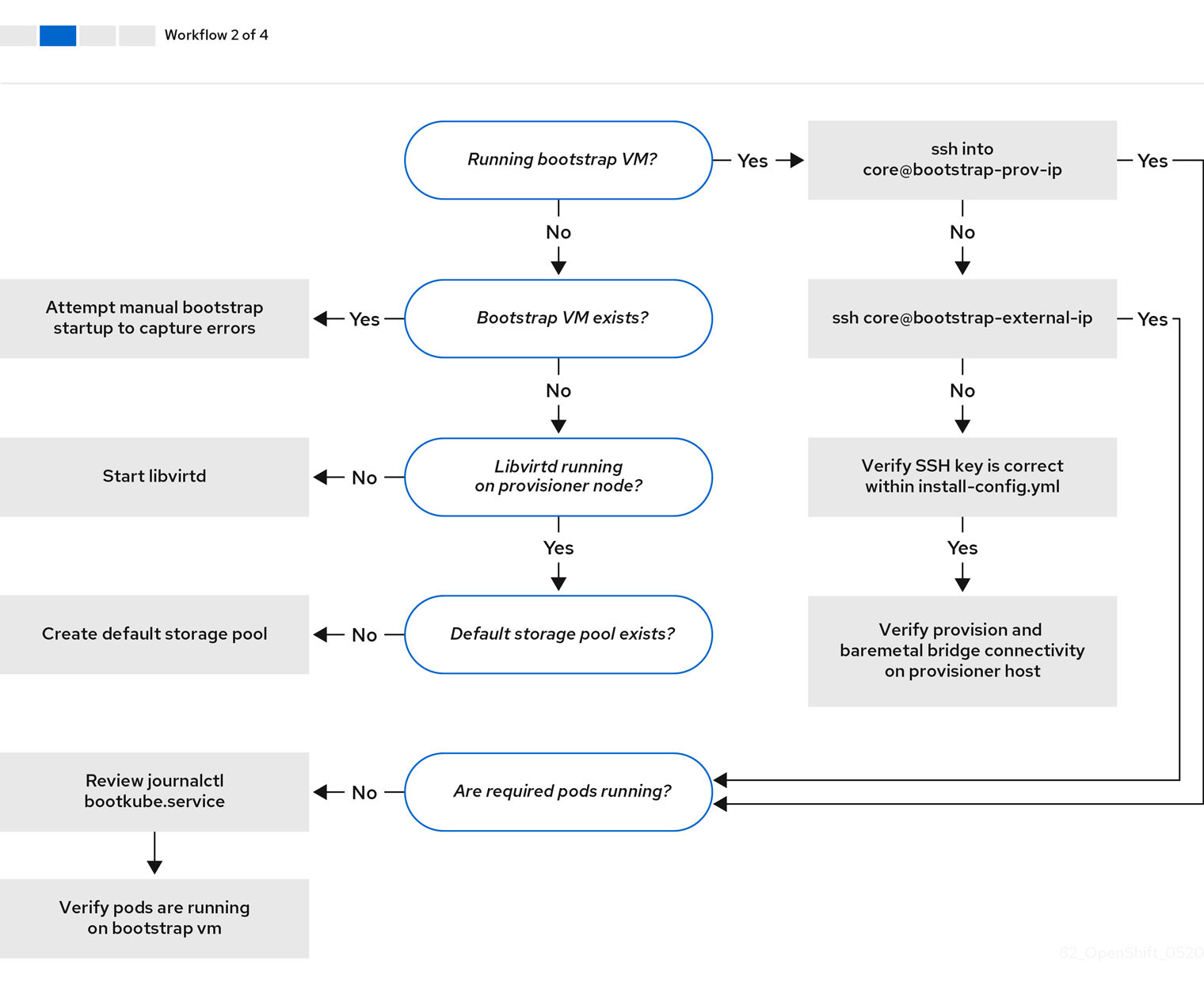
ワークフロー 2/4 は、ブートストラップ仮想マシンの問題、クラスターノードを起動できないブートストラップ仮想マシン、および ログの検査 に関するトラブルシューティングのワークフローを説明しています。provisioning ネットワークなしに OpenShift Container Platform クラスターをインストールする場合は、このワークフローは適用されません。
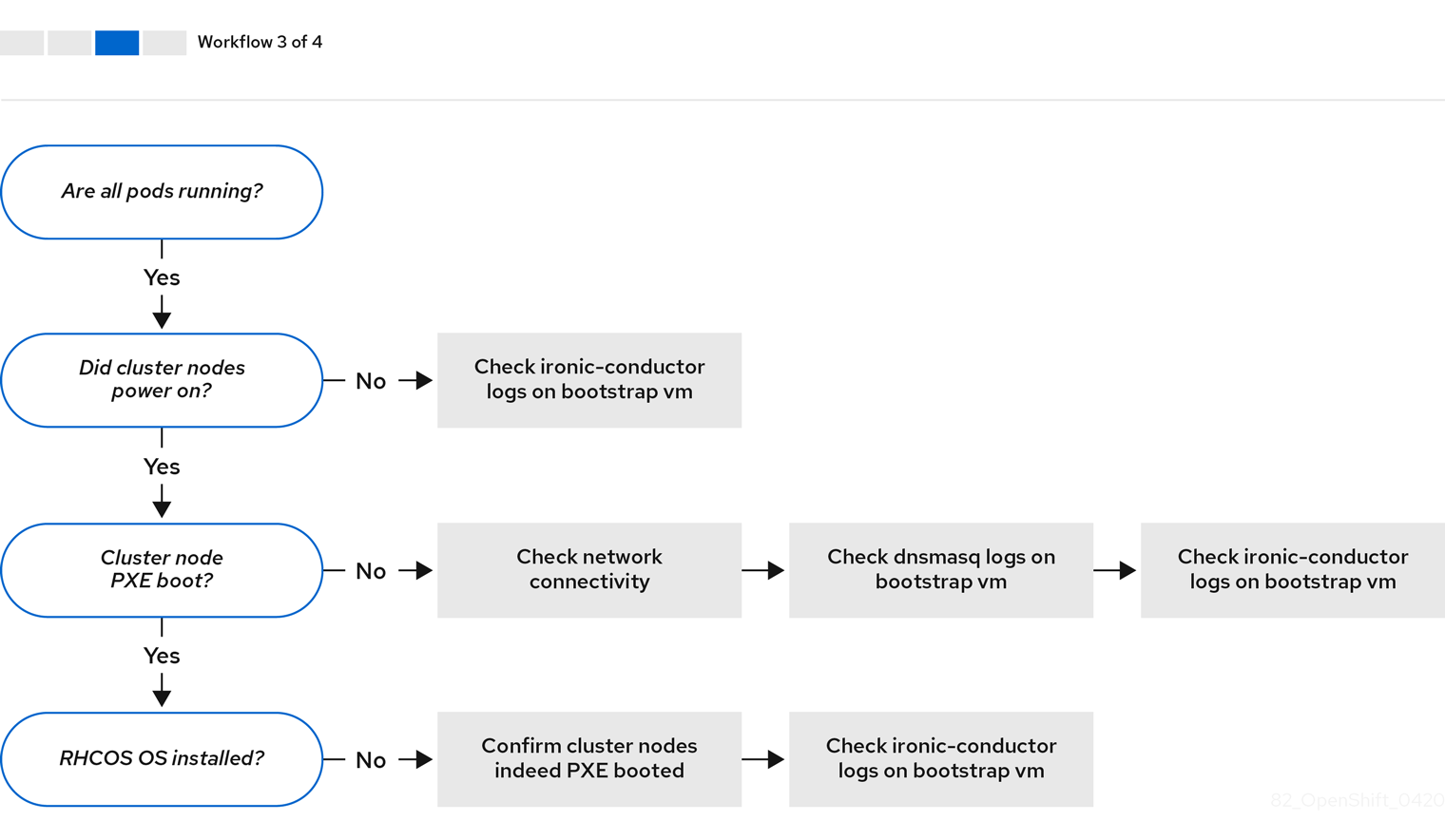
ワークフロー 3/4 は、PXE ブートしないクラスターノード のトラブルシューティングワークフローを示しています。Redfish 仮想メディアを使用してインストールする場合、インストールプログラムによるノードのデプロイに必要な最小ファームウェア要件を各ノードが満たしている必要があります。詳細は、前提条件 セクションの 仮想メディアを使用したインストールのファームウェア要件 を参照してください。
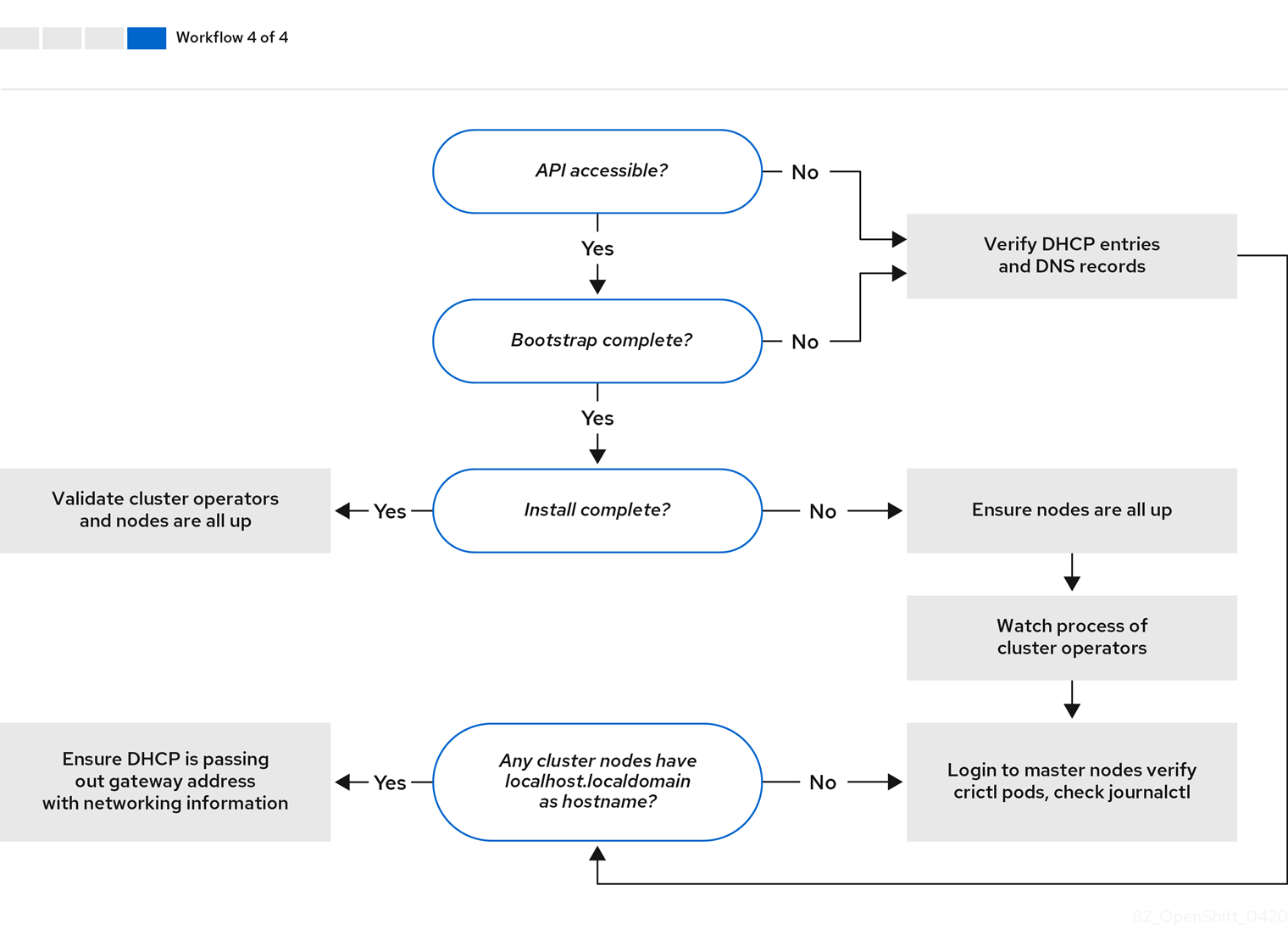
ワークフロー 4/4 は、アクセスできない API から 検証済みのインストール までのトラブルシューティングワークフローを示しています。
3.5.2. install-config.yaml のトラブルシューティング
install-config.yaml 設定ファイルは、OpenShift Container Platform クラスターの一部であるすべてのノードを表します。このファイルには、apiVersion、baseDomain、imageContentSources、および仮想 IP アドレスのみで構成されるがこれらに制限されない必要なオプションが含まれます。OpenShift Container Platform クラスターのデプロイメントの初期段階でエラーが発生した場合、エラーは install-config.yaml 設定ファイルにある可能性があります。
手順
- YAML-tips のガイドラインを使用します。
- syntax-check を使用して YAML 構文が正しいことを確認します。
Red Hat Enterprise Linux CoreOS (RHCOS) QEMU イメージが適切に定義され、
install-config.yamlで提供される URL 経由でアクセスできることを確認します。以下に例を示します。$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7出力が
200の場合、ブートストラップ仮想マシンイメージを保存する Web サーバーからの有効な応答があります。
3.5.3. ブートストラップ仮想マシンの問題のトラブルシューティング
OpenShift Container Platform インストールプログラムは、OpenShift Container Platform クラスターノードのプロビジョニングを処理するブートストラップノードの仮想マシンを起動します。
手順
インストールプログラムをトリガー後の約 10 分から 15 分後に、
virshコマンドを使用してブートストラップ仮想マシンが機能していることを確認します。$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running注記ブートストラップ仮想マシンの名前は常にクラスター名で始まり、その後にランダムな文字セットが続き、"bootstrap" という単語で終わります。
10 - 15 分経ってもブートストラップ仮想マシンが実行されない場合は、次のコマンドを実行して、システム上で
libvirtdが実行されていることを確認します。$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtdブートストラップ仮想マシンが動作している場合は、これにログインします。
virsh consoleコマンドを使用して、ブートストラップ仮想マシンの IP アドレスを見つけます。$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:重要provisioningネットワークなしで OpenShift Container Platform クラスターをデプロイする場合、172.22.0.2などのプライベート IP アドレスではなく、パブリック IP アドレスを使用する必要があります。IP アドレスを取得したら、
sshコマンドを使用してブートストラップ仮想マシンにログインします。注記直前の手順のコンソール出力では、
ens3で提供される IPv6 IP アドレスまたはens4で提供される IPv4 IP を使用できます。$ ssh core@172.22.0.2
ブートストラップ仮想マシンへのログインに成功しない場合は、以下いずれかのシナリオが発生した可能性があります。
-
172.22.0.0/24ネットワークにアクセスできない。プロビジョナーとprovisioningネットワークブリッジ間のネットワーク接続を確認します。この問題は、provisioningネットワークを使用している場合に発生することがあります。 -
パブリックネットワーク経由でブートストラップ仮想マシンにアクセスできない。
baremetalネットワークで SSH を試行する際に、provisionerホストの、とくにbaremetalネットワークブリッジについて接続を確認します。 -
Permission denied (publickey,password,keyboard-interactive)が出される。ブートストラップ仮想マシンへのアクセスを試行すると、Permission deniedエラーが発生する可能性があります。仮想マシンへのログインを試行するユーザーの SSH キーがinstall-config.yamlファイル内で設定されていることを確認します。
3.5.3.1. ブートストラップ仮想マシンがクラスターノードを起動できない
デプロイメント時に、ブートストラップ仮想マシンがクラスターノードの起動に失敗する可能性があり、これにより、仮想マシンがノードに RHCOS イメージをプロビジョニングできなくなります。このシナリオは、以下の原因で発生する可能性があります。
-
install-config.yamlファイルに関連する問題。 - ベアメタルネットワークを使用してアウトオブバンド (out-of-band) ネットワークアクセスに関する問題
この問題を確認するには、ironic に関連する 3 つのコンテナーを使用できます。
-
ironic -
ironic-inspector
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2コンテナーログを確認するには、以下を実行します。
[core@localhost ~]$ sudo podman logs -f <container_name><container_name>をironicまたはironic-inspectorのいずれかに置き換えます。コントロールプレーンノードが PXE から起動しないという問題が発生した場合は、ironicPod を確認してください。ironicPod は、IPMI 経由でノードにログインしようとするため、クラスターノードを起動しようとする試みに関する情報を含んでいます。
考えられる理由
クラスターノードは、デプロイメントの開始時に ON 状態にある可能性があります。
解決策
IPMI でのインストールを開始する前に、OpenShift Container Platform クラスターノードの電源をオフにします。
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off3.5.3.2. ログの検査
RHCOS イメージのダウンロードまたはアクセスに問題が発生した場合には、最初に install-config.yaml 設定ファイルで URL が正しいことを確認します。
RHCOS イメージをホストする内部 Web サーバーの例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader コンテナーは、Web サーバーまたは外部の quay.io レジストリー (install-config.yaml 設定ファイルで指定されている方) からリソースをダウンロードします。coreos-downloader コンテナーが稼働していることを確認し、必要に応じて、そのログを調べます。
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2次のコマンドを実行して、ブートストラップ VM 内の
coreos-downloaderコンテナーのステータスを確認します。[core@localhost ~]$ sudo podman logs -f coreos-downloaderブートストラップ仮想マシンがイメージへの URL にアクセスできない場合、
curlコマンドを使用して、仮想マシンがイメージにアクセスできることを確認します。すべてのコンテナーがデプロイメントフェーズで起動されているかどうかを示す
bootkubeログを検査するには、以下を実行します。[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.servicednsmasq、mariadb、httpd、およびironicを含むすべての Pod が実行中であることを確認します。[core@localhost ~]$ sudo podman psPod に問題がある場合には、問題のあるコンテナーのログを確認します。
ironicサービスのログを確認するには、次のコマンドを実行します。[core@localhost ~]$ sudo podman logs ironic
3.5.5. クラスターの初期化失敗のトラブルシューティング
インストールプログラムは、Cluster Version Operator を使用して、OpenShift Container Platform クラスターのすべてのコンポーネントを作成します。インストールプログラムがクラスターの初期化に失敗した場合は、ClusterVersion オブジェクトと ClusterOperator オブジェクトから最も重要な情報を取得できます。
手順
次のコマンドを実行して
ClusterVersionオブジェクトを検査します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion -o yaml出力例
apiVersion: config.openshift.io/v1 kind: ClusterVersion metadata: creationTimestamp: 2019-02-27T22:24:21Z generation: 1 name: version resourceVersion: "19927" selfLink: /apis/config.openshift.io/v1/clusterversions/version uid: 6e0f4cf8-3ade-11e9-9034-0a923b47ded4 spec: channel: stable-4.1 clusterID: 5ec312f9-f729-429d-a454-61d4906896ca status: availableUpdates: null conditions: - lastTransitionTime: 2019-02-27T22:50:30Z message: Done applying 4.1.1 status: "True" type: Available - lastTransitionTime: 2019-02-27T22:50:30Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:30Z message: Cluster version is 4.1.1 status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:24:31Z message: 'Unable to retrieve available updates: unknown version 4.1.1 reason: RemoteFailed status: "False" type: RetrievedUpdates desired: image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a version: 4.1.1 history: - completionTime: 2019-02-27T22:50:30Z image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a startedTime: 2019-02-27T22:24:31Z state: Completed version: 4.1.1 observedGeneration: 1 versionHash: Wa7as_ik1qE=次のコマンドを実行して状態を表示します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion version \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'最も重要な状態は、
Failing、Available、Progressingです。出力例
Available True Done applying 4.1.1 Failing False Progressing False Cluster version is 4.0.0-0.alpha-2019-02-26-194020 RetrievedUpdates False Unable to retrieve available updates: unknown version 4.1.1次のコマンドを実行して
ClusterOperatorオブジェクトを検査します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperatorこのコマンドは、クラスター Operators のステータスを返します。
出力例
NAME VERSION AVAILABLE PROGRESSING FAILING SINCE cluster-baremetal-operator True False False 17m cluster-autoscaler True False False 17m cluster-storage-operator True False False 10m console True False False 7m21s dns True False False 31m image-registry True False False 9m58s ingress True False False 10m kube-apiserver True False False 28m kube-controller-manager True False False 21m kube-scheduler True False False 25m machine-api True False False 17m machine-config True False False 17m marketplace-operator True False False 10m monitoring True False False 8m23s network True False False 13m node-tuning True False False 11m openshift-apiserver True False False 15m openshift-authentication True False False 20m openshift-cloud-credential-operator True False False 18m openshift-controller-manager True False False 10m openshift-samples True False False 8m42s operator-lifecycle-manager True False False 17m service-ca True False False 30m次のコマンドを実行して、個々のクラスター Operator を検査します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> -oyaml1 - 1
<operator>は、クラスター Operator の名前に置き換えます。このコマンドは、クラスター Operator のステータスがAvailableにならない理由、またはFailedになる理由を特定するために使用できます。
出力例
apiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:47:04Z generation: 1 name: monitoring resourceVersion: "24677" selfLink: /apis/config.openshift.io/v1/clusteroperators/monitoring uid: 9a6a5ef9-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:49:10Z message: Successfully rolled out the stack. status: "True" type: Available - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Failing extension: null relatedObjects: null version: ""クラスター Operator のステータス条件を取得するには、次のコマンドを実行します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'<operator>は、上記のいずれかの Operator の名前に置き換えます。出力例
Available True Successfully rolled out the stack Progressing False Failing Falseクラスター Operator が所有するオブジェクトのリストを取得するには、次のコマンドを実行します。
oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator kube-apiserver \ -o=jsonpath='{.status.relatedObjects}'出力例
[map[resource:kubeapiservers group:operator.openshift.io name:cluster] map[group: name:openshift-config resource:namespaces] map[group: name:openshift-config-managed resource:namespaces] map[group: name:openshift-kube-apiserver-operator resource:namespaces] map[group: name:openshift-kube-apiserver resource:namespaces]]
3.5.6. コンソール URL の取得に失敗した場合のトラブルシューティング
インストールプログラムは、openshift-console namespace 内の [route][route-object] を使用して、OpenShift Container Platform コンソールの URL を取得します。インストールプログラムがコンソールの URL の取得に失敗した場合は、次の手順に従います。
手順
次のコマンドを実行して、コンソールルーターが
Available状態かFailing状態かを確認します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator console -oyamlapiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:46:57Z generation: 1 name: console resourceVersion: "19682" selfLink: /apis/config.openshift.io/v1/clusteroperators/console uid: 960364aa-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:46:58Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:12Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:50:12Z status: "True" type: Available - lastTransitionTime: 2019-02-27T22:46:57Z status: "True" type: Upgradeable extension: null relatedObjects: - group: operator.openshift.io name: cluster resource: consoles - group: config.openshift.io name: cluster resource: consoles - group: oauth.openshift.io name: console resource: oauthclients - group: "" name: openshift-console-operator resource: namespaces - group: "" name: openshift-console resource: namespaces versions: null次のコマンドを実行して、コンソール URL を手動で取得します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get route console -n openshift-console \ -o=jsonpath='{.spec.host}' console-openshift-console.apps.adahiya-1.devcluster.openshift.com
3.5.7. kubeconfig に Ingress 証明書を追加できない場合のトラブルシューティング
インストールプログラムは、${INSTALL_DIR}/auth/kubeconfig 内の信頼できるクライアント認証局のリストにデフォルトの Ingress 証明書を追加します。インストールプログラムが Ingress 証明書を kubeconfig ファイルに追加できない場合は、クラスターから証明書を取得して追加できます。
手順
次のコマンドを使用して、クラスターから証明書を取得します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get configmaps default-ingress-cert \ -n openshift-config-managed -o=jsonpath='{.data.ca-bundle\.crt}'-----BEGIN CERTIFICATE----- MIIC/TCCAeWgAwIBAgIBATANBgkqhkiG9w0BAQsFADAuMSwwKgYDVQQDDCNjbHVz dGVyLWluZ3Jlc3Mtb3BlcmF0b3JAMTU1MTMwNzU4OTAeFw0xOTAyMjcyMjQ2Mjha Fw0yMTAyMjYyMjQ2MjlaMC4xLDAqBgNVBAMMI2NsdXN0ZXItaW5ncmVzcy1vcGVy YXRvckAxNTUxMzA3NTg5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA uCA4fQ+2YXoXSUL4h/mcvJfrgpBfKBW5hfB8NcgXeCYiQPnCKblH1sEQnI3VC5Pk 2OfNCF3PUlfm4i8CHC95a7nCkRjmJNg1gVrWCvS/ohLgnO0BvszSiRLxIpuo3C4S EVqqvxValHcbdAXWgZLQoYZXV7RMz8yZjl5CfhDaaItyBFj3GtIJkXgUwp/5sUfI LDXW8MM6AXfuG+kweLdLCMm3g8WLLfLBLvVBKB+4IhIH7ll0buOz04RKhnYN+Ebw tcvFi55vwuUCWMnGhWHGEQ8sWm/wLnNlOwsUz7S1/sW8nj87GFHzgkaVM9EOnoNI gKhMBK9ItNzjrP6dgiKBCQIDAQABoyYwJDAOBgNVHQ8BAf8EBAMCAqQwEgYDVR0T AQH/BAgwBgEB/wIBADANBgkqhkiG9w0BAQsFAAOCAQEAq+vi0sFKudaZ9aUQMMha CeWx9CZvZBblnAWT/61UdpZKpFi4eJ2d33lGcfKwHOi2NP/iSKQBebfG0iNLVVPz vwLbSG1i9R9GLdAbnHpPT9UG6fLaDIoKpnKiBfGENfxeiq5vTln2bAgivxrVlyiq +MdDXFAWb6V4u2xh6RChI7akNsS3oU9PZ9YOs5e8vJp2YAEphht05X0swA+X8V8T C278FFifpo0h3Q0Dbv8Rfn4UpBEtN4KkLeS+JeT+0o2XOsFZp7Uhr9yFIodRsnNo H/Uwmab28ocNrGNiEVaVH6eTTQeeZuOdoQzUbClElpVmkrNGY0M42K0PvOQ/e7+y AQ== -----END CERTIFICATE------
${INSTALL_DIR}/auth/kubeconfigファイルのclient-certificate-authority-dataフィールドに証明書を追加します。
3.5.8. クラスターノードへの SSH アクセスのトラブルシューティング
セキュリティーを強化するために、デフォルトではクラスターの外部からクラスターに SSH 接続することは禁止されています。ただし、プロビジョナーノードからコントロールプレーンノードとワーカーノードにアクセスすることはできます。プロビジョナーノードからクラスターノードに SSH 接続できない場合、クラスターノードがブートストラップ仮想マシンを待機している可能性があります。コントロールプレーンノードはブートストラップ仮想マシンからブート設定を取得します。コントロールプレーンノードはブート設定を取得しないと、正常に起動できません。
手順
- ノードに物理的にアクセスできる場合は、コンソールの出力をチェックして、正常に起動したかどうかを確認します。ノードがまだブート設定を取得中の場合は、ブートストラップ仮想マシンに問題がある可能性があります。
-
install-config.yamlファイルでsshKey: '<ssh_pub_key>'が設定されていることを確認します。<ssh_pub_key>は、プロビジョナーノード上のkniユーザーの公開鍵です。
3.5.9. クラスターノードが PXE ブートしない
OpenShift Container Platform クラスターノードが PXE ブートしない場合、PXE ブートしないクラスターノードで以下のチェックを実行します。この手順は、provisioning ネットワークなしで OpenShift Container Platform クラスターをインストールする場合には適用されません。
手順
-
provisioningネットワークへのネットワークの接続を確認します。 -
PXE が
provisioningネットワークの NIC で有効にされており、PXE がその他のすべての NIC について無効にされていることを確認します。 install-config.yaml設定ファイルに、provisioningネットワークに接続されている NIC のrootDeviceHintsパラメーターとブート MAC アドレスが含まれていることを確認します。以下に例を示します。コントロールプレーンノードの設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NICワーカーノード設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC
3.5.10. インストールしてもワーカーノードが作成されない
インストールプログラムはワーカーノードを直接プロビジョニングしません。代わりに、Machine API Operator が、サポートされているプラットフォーム上でノードをスケールアップおよびスケールダウンします。クラスターのインターネット接続の速度によって異なりますが、15 - 20 分経ってもワーカーノードが作成されない場合は、Machine API Operator を調査してください。
手順
次のコマンドを実行して、Machine API Operator を確認します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api get deploymentsご使用の環境で
${INSTALL_DIR}が設定されていない場合は、値をインストールディレクトリーの名前に置き換えます。出力例
NAME READY UP-TO-DATE AVAILABLE AGE cluster-autoscaler-operator 1/1 1 1 86m cluster-baremetal-operator 1/1 1 1 86m machine-api-controllers 1/1 1 1 85m machine-api-operator 1/1 1 1 86m次のコマンドを実行して、マシンコントローラーのログを確認します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api logs deployments/machine-api-controllers \ --container=machine-controller
3.5.11. Cluster Network Operator のトラブルシューティング
Cluster Network Operator は、ネットワークコンポーネントのデプロイを担当します。この Operator は、コントロールプレーンノードが起動した後、インストールプログラムがブートストラップコントロールプレーンを削除する前に、インストールプロセスの初期段階で実行されます。この Operator に問題がある場合、インストールプログラムに問題がある可能性があります。
手順
次のコマンドを実行して、ネットワーク設定が存在することを確認します。
$ oc get network -o yaml cluster存在しない場合は、インストールプログラムによって作成されていません。理由を確認するには、次のコマンドを実行します。
$ openshift-install create manifestsマニフェストを確認して、インストールプログラムがネットワーク設定を作成しなかった理由を特定します。
次のコマンドを入力して、ネットワークが実行中であることを確認します。
$ oc get po -n openshift-network-operator
3.5.12. BMC を使用して、新しいベアメタルホストを検出できない
場合によっては、リモート仮想メディア共有をマウントできないため、インストールプログラムが新しいベアメタルホストを検出できず、エラーが発生することがあります。
以下に例を示します。
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST
https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia
returned code 400.
Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information
Extended information: [
{
"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.",
"MessageArgs": [
"https://<ironic_address>/redfish/boot-<uuid>.iso"
],
"MessageArgs@odata.count": 1,
"MessageId": "IDRAC.2.5.RAC0720",
"RelatedProperties": [
"#/Image"
],
"RelatedProperties@odata.count": 1,
"Resolution": "Retry the operation.",
"Severity": "Informational"
}
].この状況で、認証局が不明な仮想メディアを使用している場合は、不明な認証局を信頼するように、ベースボード管理コントローラー (BMC) のリモートファイル共有設定を行って、このエラーを回避できます。
この解決策は、Dell iDRAC 9 およびファームウェアバージョン 5.10.50 を搭載した OpenShift Container Platform 4.11 でテストされました。
3.5.13. クラスターに参加できないワーカーノードのトラブルシューティング
installer-provisioned クラスターは、api-int.<cluster_name>.<base_domain> URL の DNS エントリーが含まれる DNS サーバーと共にデプロイされます。クラスター内のノードが外部またはアップストリーム DNS サーバーを使用して api-int.<cluster_name>.<base_domain> URL を解決し、そのようなエントリーがない場合、ワーカーノードはクラスターに参加できない可能性があります。クラスター内のすべてのノードがドメイン名を解決できることを確認します。
手順
DNS A/AAAA または CNAME レコードを追加して、API ロードバランサーを内部的に識別します。たとえば、dnsmasq を使用する場合は、
dnsmasq.conf設定ファイルを変更します。$ sudo nano /etc/dnsmasq.confaddress=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334DNS PTR レコードを追加して、API ロードバランサーを内部的に識別します。たとえば、dnsmasq を使用する場合は、
dnsmasq.conf設定ファイルを変更します。$ sudo nano /etc/dnsmasq.confptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.comDNS サーバーを再起動します。たとえば、dnsmasq を使用する場合は、以下のコマンドを実行します。
$ sudo systemctl restart dnsmasq
これらのレコードは、クラスター内のすべてのノードで解決できる必要があります。
3.5.14. 以前のインストールのクリーンアップ
以前にデプロイが失敗した場合は、OpenShift Container Platform を再度デプロイする前に、失敗した試行のアーティファクトを削除します。
手順
OpenShift Container Platform クラスターをインストールする前に、次のコマンドを使用して、すべてのベアメタルノードの電源をオフにします。
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off次のスクリプトを使用して、以前のデプロイ試行時に残った古いブートストラップリソースをすべて削除します。
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done次のコマンドを使用して、以前のインストールにより生成されたアーティファクトを削除します。
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json次のコマンドを使用して、OpenShift Container Platform マニフェストを再作成します。
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
3.5.15. レジストリーの作成に関する問題
非接続レジストリーの作成時に、レジストリーのミラーリングを試行する際に "User Not Authorized" エラーが発生する場合があります。このエラーは、新規の認証を既存の pull-secret.txt ファイルに追加できない場合に生じる可能性があります。
手順
認証が正常に行われていることを確認します。
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO注記インストールイメージのミラーリングに使用される変数の出力例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'RELEASE_IMAGEおよびVERSIONの値は、OpenShift インストールの環境のセットアップ セクションの OpenShift Installer の取得 の手順で設定されています。レジストリーのミラーリング後に、非接続環境でこれにアクセスできることを確認します。
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}
3.5.16. その他の問題点
3.5.16.1. runtime network not ready エラーへの対応
クラスターのデプロイメント後に、以下のエラーが発生する可能性があります。
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator は、インストールプログラムによって作成される特別なオブジェクトに応じてネットワークコンポーネントをデプロイします。これは、コントロールプレーン (マスター) ノードが起動した後、ブートストラップコントロールプレーンが停止する前にインストールプロセスの初期段階で実行されます。これは、コントロールプレーン (マスター) ノードの起動の長い遅延や apiserver の通信の問題など、より判別しにくいインストールプログラムの問題を示している可能性があります。
手順
openshift-network-operatornamespace の Pod を検査します。$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149mprovisionerノードで、ネットワーク設定が存在することを判別します。$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OVNKubernetes存在しない場合は、インストールプログラムによって作成されていません。インストールプログラムによって作成されなかった理由を確認するには、次のコマンドを実行します。
$ openshift-install create manifestsnetwork-operatorが実行されていることを確認します。$ kubectl -n openshift-network-operator get podsログを取得します。
$ kubectl -n openshift-network-operator logs -l "name=network-operator"3 つ以上のコントロールプレーンノードを持つ高可用性クラスターでは、Operator がリーダー選択を実行し、他のすべての Operator がスリープ状態になります。詳細は、Troubleshooting を参照してください。
3.5.16.2. "No disk found with matching rootDeviceHints" エラーメッセージへの対処
クラスターをデプロイした後、次のエラーメッセージが表示される場合があります。
No disk found with matching rootDeviceHints
No disk found with matching rootDeviceHints エラーメッセージに対処するための一時的な回避策は、rootDeviceHints を minSizeGigabytes: 300 に変更することです。
rootDeviceHints 設定を変更した後、CoreOS を起動し、次のコマンドを使用してディスク情報を確認します。
$ udevadm info /dev/sda
DL360 Gen 10 サーバーを使用している場合は、/dev/sda デバイス名が割り当てられている SD カードスロットがあることに注意してください。サーバーに SD カードが存在しない場合は、競合が発生する可能性があります。サーバーの BIOS 設定で SD カードスロットが無効になっていることを確認してください。
minSizeGigabytes の回避策が要件を満たしていない場合は、rootDeviceHints を /dev/sda に戻さないといけない場合があります。この変更により、Ironic イメージが正常に起動できるようになります。
この問題を解決する別の方法は、ディスクのシリアル ID を使用することです。ただし、シリアル ID を見つけるのは困難な場合があり、設定ファイルが読みにくくなる可能性があることに注意してください。このパスを選択する場合は、前に説明したコマンドを使用してシリアル ID を収集し、それを設定に組み込んでください。
3.5.16.3. クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない
クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない場合は、以下の点を確認してください。
- 予約された IPv6 アドレスが DHCP 範囲外にあることを確認します。
DHCP サーバーの IP アドレス予約では、予約で正しい DUID (DHCP 固有識別子) が指定されていることを確認します。以下に例を示します。
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- Route Announcement が機能していることを確認します。
- DHCP サーバーが、IP アドレス範囲を提供する必要なインターフェイスでリッスンしていることを確認します。
3.5.16.4. クラスターノードが DHCP 経由で正しいホスト名を取得しない
IPv6 のデプロイメント時に、クラスターノードは DHCP でホスト名を取得する必要があります。NetworkManager はホスト名をすぐに割り当てない場合があります。コントロールプレーン (マスター) ノードは、以下のようなエラーを報告する可能性があります。
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
このエラーは、最初に DHCP サーバーからホスト名を受信せずにクラスターノードが起動する可能性があることを示しています。これにより、kubelet が localhost.localdomain ホスト名で起動します。エラーに対処するには、ノードによるホスト名の更新を強制します。
手順
hostnameを取得します。[core@master-X ~]$ hostnameホスト名が
localhostの場合は、以下の手順に進みます。注記Xはコントロールプレーンノード番号です。クラスターノードによる DHCP リースの更新を強制します。
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"<bare_metal_nic>を、baremetalネットワークに対応する有線接続に置き換えます。hostnameを再度確認します。[core@master-X ~]$ hostnameホスト名が
localhost.localdomainの場合は、NetworkManagerを再起動します。[core@master-X ~]$ sudo systemctl restart NetworkManager-
ホスト名がまだ
localhost.localdomainの場合は、数分待機してから再度確認します。ホスト名がlocalhost.localdomainのままの場合は、直前の手順を繰り返します。 nodeip-configurationサービスを再起動します。[core@master-X ~]$ sudo systemctl restart nodeip-configuration.serviceこのサービスは、正しいホスト名の参照で
kubeletサービスを再設定します。kubelet が直前の手順で変更された後にユニットファイル定義を再読み込みします。
[core@master-X ~]$ sudo systemctl daemon-reloadkubeletサービスを再起動します。[core@master-X ~]$ sudo systemctl restart kubelet.servicekubeletが正しいホスト名で起動されていることを確認します。[core@master-X ~]$ sudo journalctl -fu kubelet.service
再起動時など、クラスターの稼働後にクラスターノードが正しいホスト名を取得しない場合、クラスターの csr は保留中になります。csr は承認 しません。承認すると、他の問題が生じる可能性があります。
csr の対応
クラスターで CSR を取得します。
$ oc get csr保留中の
csrにSubject Name: localhost.localdomainが含まれているかどうかを確認します。$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -textSubject Name: localhost.localdomainが含まれるcsrを削除します。$ oc delete csr <wrong_csr>
3.5.16.5. ルートがエンドポイントに到達しない
インストールプロセス時に、VRRP (Virtual Router Redundancy Protocol) の競合が発生する可能性があります。この競合は、特定のクラスター名を使用してクラスターデプロイメントの一部であった、以前に使用された OpenShift Container Platform ノードが依然として実行中であるものの、同じクラスター名を使用した現在の OpenShift Container Platform クラスターデプロイメントの一部ではない場合に発生する可能性があります。たとえば、クラスターはクラスター名 openshift を使用してデプロイされ、3 つのコントロールプレーン (マスター) ノードと 3 つのワーカーノードをデプロイします。後に、別のインストールで同じクラスター名 openshift が使用されますが、この再デプロイメントは 3 つのコントロールプレーン (マスター) ノードのみをインストールし、以前のデプロイメントの 3 つのワーカーノードを ON 状態のままにします。これにより、VRID (Virtual Router Identifier) の競合が発生し、VRRP が競合する可能性があります。
ルートを取得します。
$ oc get route oauth-openshiftサービスエンドポイントを確認します。
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59mコントロールプレーン (マスター) ノードからサービスへのアクセスを試行します。
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403provisionerノードからのauthentication-operatorエラーを特定します。$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
解決策
- すべてのデプロイメントのクラスター名が一意であり、競合が発生しないことを確認します。
- 同じクラスター名を使用するクラスターデプロイメントの一部ではない不正なノードをすべてオフにします。そうしないと、OpenShift Container Platform クラスターの認証 Pod が正常に起動されなくなる可能性があります。
3.5.16.6. 初回起動時の Ignition の失敗
初回起動時に、Ignition 設定が失敗する可能性があります。
手順
Ignition 設定が失敗したノードに接続します。
Failed Units: 1 machine-config-daemon-firstboot.servicemachine-config-daemon-firstbootサービスを再起動します。[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
3.5.16.7. NTP が同期しない
OpenShift Container Platform クラスターのデプロイメントは、クラスターノード間の NTP の同期クロックによって異なります。同期クロックがない場合、時間の差が 2 秒を超えるとクロックのドリフトによりデプロイメントが失敗する可能性があります。
手順
クラスターノードの
AGEの差異の有無を確認します。以下に例を示します。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.31.3 master-1.cloud.example.com Ready master 135m v1.31.3 master-2.cloud.example.com Ready master 145m v1.31.3 worker-2.cloud.example.com Ready worker 100m v1.31.3クロックのドリフトによる一貫性のないタイミングの遅延を確認します。以下に例を示します。
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out_of_band_ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
既存のクラスターでのクロックドリフトへの対応
ノードに配信される
chrony.confファイルの内容を含む Butane 設定ファイルを作成します。以下の例で、99-master-chrony.buを作成して、ファイルをコントロールプレーンノードに追加します。ワーカーノードのファイルを変更するか、ワーカーロールに対してこの手順を繰り返すことができます。注記Butane の詳細は、「Butane を使用したマシン設定の作成」を参照してください。
variant: openshift version: 4.18.0 metadata: name: 99-master-chrony labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | server <NTP_server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
<NTP_server>を NTP サーバーの IP アドレスに置き換えます。
Butane を使用して、ノードに配信される設定を含む
MachineConfigオブジェクトファイル (99-master-chrony.yaml) を生成します。$ butane 99-master-chrony.bu -o 99-master-chrony.yamlMachineConfigオブジェクトファイルを適用します。$ oc apply -f 99-master-chrony.yamlSystem clock synchronizedの値が yes であることを確認します。$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: noデプロイメントの前にクロック同期を設定するには、マニフェストファイルを生成し、このファイルを
openshiftディレクトリーに追加します。以下に例を示します。$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yamlクラスターの作成を継続します。
3.5.17. インストールの確認
インストール後、インストールプログラムによってノードと Pod が正常にデプロイされたことを確認します。
手順
OpenShift Container Platform クラスターノードが適切にインストールされると、以下の
Ready状態がSTATUS列に表示されます。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.31.3 master-1.example.com Ready master,worker 4h v1.31.3 master-2.example.com Ready master,worker 4h v1.31.3インストールプログラムによってすべての Pod が正常にデプロイされたことを確認します。以下のコマンドは、実行中の Pod、または出力の一部として完了した Pod を削除します。
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete