1.2. モニタリングスタックについて
OpenShift Container Platform モニタリングスタックは、Prometheus オープンソースプロジェクトおよびその幅広いエコシステムをベースとしています。モニタリングスタックには、以下のコンポーネントが含まれます。
デフォルトのプラットフォームモニタリングコンポーネント。プラットフォームモニタリングコンポーネントのセットは、OpenShift Container Platform のインストール時にデフォルトで
openshift-monitoringプロジェクトにインストールされます。これにより、Kubernetes サービスを含むコアクラスターコンポーネントのモニタリングが可能になります。デフォルトのモニタリングスタックは、クラスターのリモートのヘルスモニタリングも有効にします。これらのコンポーネントは、以下の図の Installed by default (デフォルトのインストール) セクションで説明されています。
-
ユーザー定義のプロジェクトをモニターするためのコンポーネント。オプションでユーザー定義プロジェクトのモニタリングを有効にした後に、追加のモニタリングコンポーネントは
openshift-user-workload-monitoringプロジェクトにインストールされます。これにより、ユーザー定義プロジェクトのモニタリング機能が提供されます。これらのコンポーネントは、以下の図の User (ユーザー) セクションで説明されています。
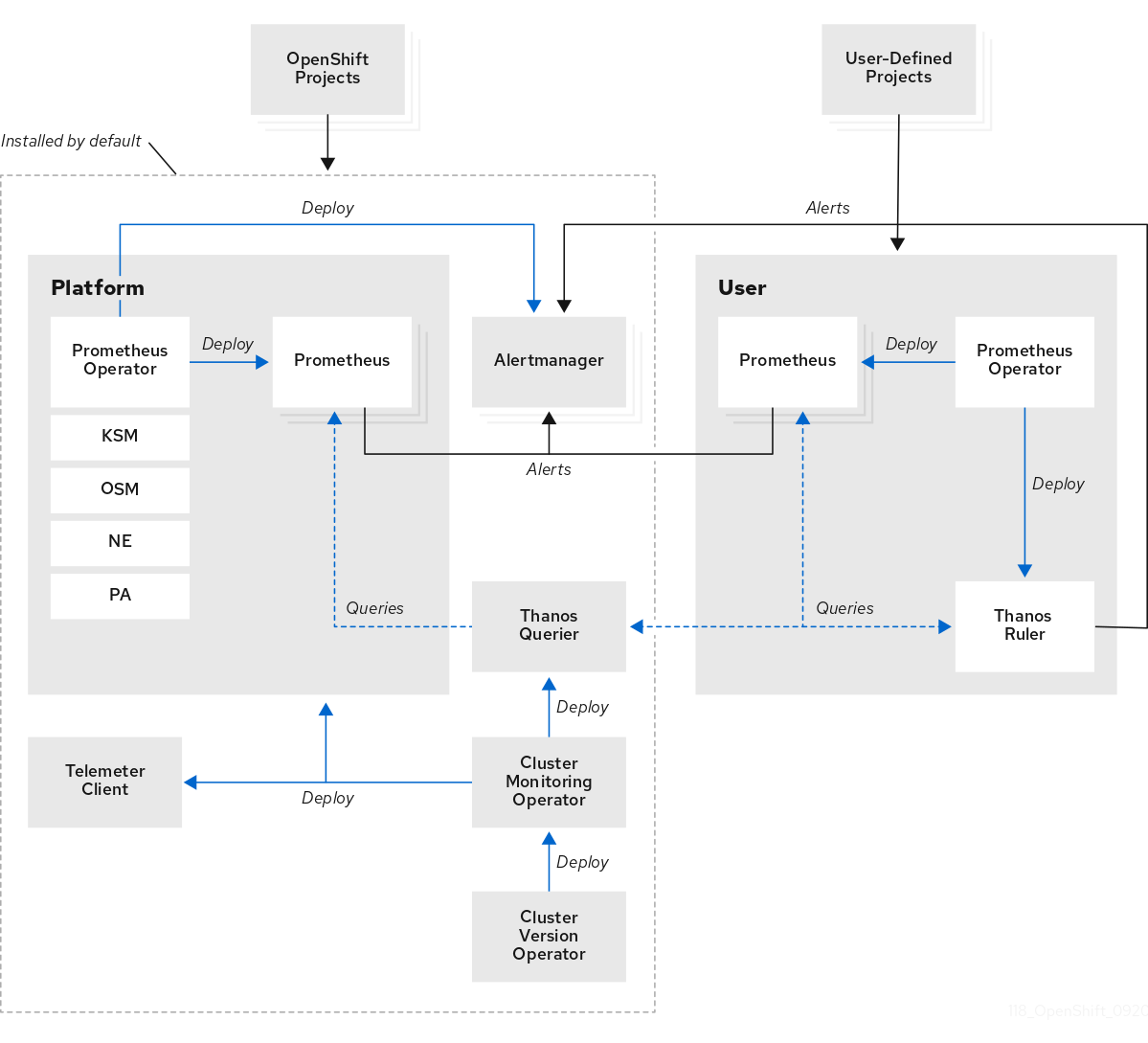
1.2.1. デフォルトのモニタリングコンポーネント
デフォルトで、OpenShift Container Platform 4.14 モニタリングスタックには、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Cluster Monitoring Operator | Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Prometheus および Alertmanager インスタンス、Thanos Querier、Telemeter Client、およびメトリクスターゲットをデプロイ、管理、および自動更新します。CMO は Cluster Version Operator (CVO) によってデプロイされます。 |
| Prometheus Operator |
|
| Prometheus | Prometheus は、OpenShift Container Platform モニタリングスタックのベースとなるモニタリングシステムです。Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Prometheus アダプター |
Prometheus アダプター (上記の図の PA) は、Prometheus で使用する Kubernetes ノードおよび Pod クエリーを変換します。変換されるリソースメトリクスには、CPU およびメモリーの使用率メトリクスが含まれます。Prometheus アダプターは、Horizontal Pod Autoscaling のクラスターリソースメトリクス API を公開します。Prometheus アダプターは |
| Alertmanager | Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。 |
| kube-state-metrics エージェント | kube-state-metrics エクスポーターエージェント (上記の図の KSM) は、Kubernetes オブジェクトを Prometheus が使用できるメトリクスに変換します。 |
| monitoring-plugin | monitoring-plugin 動的プラグインコンポーネントは、OpenShift Container Platform Web コンソールの Observe セクションにモニタリングページをデプロイします。Cluster Monitoring Operator (CMO) config map 設定を使用すると、Web コンソールページの monitoring-plugin リソースを管理できます。 |
| openshift-state-metrics エージェント | openshift-state-metrics エクスポーター (上記の図の OSM) は、OpenShift Container Platform 固有のリソースのメトリクスを追加して、kube-state-metrics を拡張します。 |
| node-exporter エージェント | ノードエクスポーターエージェント (上記の図の NE) は、クラスター内のすべてのノードに関するメトリクスを収集します。node-exporter エージェントはすべてのノードにデプロイされます。 |
| Thanos Querier | Thanos Querier は、単一のマルチテナントインターフェイスで、OpenShift Container Platform のコアメトリクスおよびユーザー定義プロジェクトのメトリクスを集約し、オプションでこれらの重複を排除します。 |
| Telemeter クライアント | Telemeter Client は、クラスターのリモートヘルスモニタリングを容易にするために、プラットフォーム Prometheus インスタンスから Red Hat にデータのサブセクションを送信します。 |
モニターリグスタックのすべてのコンポーネントはスタックによってモニターされ、OpenShift Container Platform の更新時に自動的に更新されます。
モニタリングスタックのすべてのコンポーネントは、クラスター管理者が一元的に設定する TLS セキュリティープロファイル設定を使用します。TLS セキュリティー設定を使用するモニタリングスタックコンポーネントを設定する場合、コンポーネントはグローバル OpenShift Container Platform apiservers.config.openshift.io/cluster リソースの tlsSecurityProfile フィールドにすでに存在する TLS セキュリティープロファイル設定を使用します。
1.2.2. デフォルトのモニタリングターゲット
スタック自体のコンポーネントに加えて、デフォルトのモニタリングスタックは追加のプラットフォームコンポーネントを監視します。
以下は、監視ターゲットの例です。
- CoreDNS
- etcd
- HAProxy
- イメージレジストリー
- Kubelets
- Kubernetes API サーバー
- Kubernetes コントローラーマネージャー
- Kubernetes スケジューラー
- OpenShift API サーバー
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
- ターゲットの正確なリストは、クラスターの機能とインストールされているコンポーネントによって異なる場合があります。
- 各 OpenShift Container Platform コンポーネントはそれぞれのモニタリング設定を行います。OpenShift Container Platform コンポーネントのモニタリングに関する問題は、Jira 問題 で一般的なモニタリングコンポーネントについてではなく、特定のコンポーネントに対してバグを報告してください。
他の OpenShift Container Platform フレームワークのコンポーネントもメトリクスを公開する場合があります。詳細は、それぞれのドキュメントを参照してください。
1.2.3. ユーザー定義プロジェクトをモニターするためのコンポーネント
OpenShift Container Platform には、ユーザー定義プロジェクトでサービスおよび Pod をモニターできるモニタリングスタックのオプションの拡張機能が含まれています。この機能には、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus は、ユーザー定義のプロジェクト用にモニタリング機能が提供されるモニタリングシステムです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Thanos Ruler | Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。 |
| Alertmanager | Alertmanager サービスは、Prometheus および Thanos Ruler から送信されるアラートを処理します。Alertmanager はユーザー定義のアラートを外部通知システムに送信します。このサービスのデプロイは任意です。 |
上記の表のコンポーネントは、モニタリングがユーザー定義のプロジェクトに対して有効にされた後にデプロイされます。
OpenShift Container Platform が更新されると、これらのコンポーネントはすべてスタックによってモニタリングされ、自動的に更新されます。
1.2.4. ユーザー定義プロジェクトのターゲットのモニタリング
ユーザー定義プロジェクトの監視を有効にすると、次のものを監視できます。
- ユーザー定義プロジェクトのサービスエンドポイント経由で提供されるメトリクス。
- ユーザー定義プロジェクトで実行される Pod。
1.2.5. 高可用性クラスターのモニタリングスタックについて
マルチノードクラスターでは、データの損失やサービスの停止を防ぐために、次のコンポーネントがデフォルトで高可用性 (HA) モードで実行されます。
- Prometheus
- Alertmanager
- Thanos Ruler
- Thanos Querier
- Prometheus アダプター
- モニタリングプラグイン
コンポーネントは 2 つの Pod にレプリケートされ、それぞれが別のノードで実行されます。そのため、モニタリングスタックは 1 つの Pod の損失に耐えることができます。
- HA モードの Prometheus
- 両方のレプリカが独立して同じターゲットをスクレイピングし、同じルールを評価します。
- レプリカは相互に通信しません。したがって、Pod 間でデータが異なる場合があります。
- HA モードの Alertmanager
- 2 つのレプリカが通知とサイレンス状態を相互に同期します。これにより、各通知が少なくとも 1 回は送信されます。
- レプリカが通信に失敗した場合、または受信側に問題がある場合、通知は送信されますが、重複する可能性があります。
Prometheus、Alertmanager、Thanos Ruler はステートフルコンポーネントです。高可用性を実現するには、これらのコンポーネントを永続ストレージを使用して設定する必要があります。