1.4. OpenShift Container Platform の更新期間について
OpenShift Container Platform の更新期間は、デプロイメントのトポロジーによって異なります。このページは、更新期間に影響を与える要因を理解し、ご使用の環境でクラスターの更新にかかる時間を見積もるのに役立ちます。
1.4.1. 更新期間に影響する要因
次の要因は、クラスターの更新期間に影響を与える可能性があります。
Machine Config Operator (MCO) による新しいマシン設定へのコンピュートノードの再起動
マシン設定プールの
MaxUnavailableの値警告OpenShift Container Platform のすべてのマシン設定プールにおける
maxUnavailableのデフォルト設定は1です。この値を変更せず、一度に 1 つのコントロールプレーンノードを更新することを推奨します。コントロールプレーンプールのこの値を3に変更しないでください。- Pod 中断バジェット (PDB) に設定されたレプリカの最小数またはパーセンテージ
- クラスター内のノード数
- クラスターノードの可用性
1.4.2. クラスターの更新フェーズ
OpenShift Container Platform では、クラスターの更新は 2 つのフェーズで行われます。
- Cluster Version Operator (CVO) ターゲット更新ペイロードのデプロイメント
- Machine Config Operator (MCO) ノードの更新
1.4.2.1. Cluster Version Operator ターゲット更新ペイロードのデプロイメント
Cluster Version Operator (CVO) は、ターゲットの更新リリースイメージを取得し、クラスターに適用します。Pod として実行されるすべてのコンポーネントはこのフェーズ中に更新されますが、ホストコンポーネントは Machine Config Operator (MCO) によって更新されます。このプロセスには 60 ~ 120 分かかる場合があります。
更新の CVO フェーズでは、ノードは再起動されません。
1.4.2.2. Machine Config Operator ノードの更新
Machine Config Operator (MCO) は、新しいマシン設定を各コントロールプレーンとコンピュートノードに適用します。このプロセス中に、MCO はクラスターの各ノードで次の一連のアクションを実行します。
- すべてのノードを遮断してドレインする
- オペレーティングシステム (OS) を更新する
- ノードを再起動します。
- すべてのノードのコードを解除し、ノードでワークロードをスケジュールします
ノードが遮断されている場合、ワークロードをそのノードにスケジュールすることはできません。
このプロセスが完了するまでの時間は、ノードやインフラストラクチャーの設定など、いくつかの要因によって異なります。このプロセスは、ノードごとに完了するまでに 5 分以上かかる場合があります。
MCO に加えて、次のパラメーターの影響を考慮する必要があります。
- コントロールプレーンノードの更新期間は予測可能であり、多くの場合、コンピュートノードよりも短くなります。これは、コントロールプレーンのワークロードが適切な更新と迅速なドレインに合わせて調整されているためです。
-
Machine Config Pool (MCP) で
maxUnavailableフィールドを1より大きい値に設定することで、コンピュートノードを並行して更新できます。MCO は、maxUnavailableで指定された数のノードを遮断し、それらを更新不可としてマークします。 -
MCP で
maxUnavailableを増やすと、プールがより迅速に更新されるのに役立ちます。ただし、maxUnavailableの設定が高すぎて、複数のノードが同時に遮断されている場合、レプリカを実行するスケジュール可能なノードが見つからないため、Pod 中断バジェット (PDB) で保護されたワークロードのドレインに失敗する可能性があります。MCP のmaxUnavailableを増やす場合は、PDB で保護されたワークロードを排出できるように、スケジュール可能なノードがまだ十分にあることを確認してください。 更新を開始する前に、すべてのノードが使用可能であることを確認する必要があります。ノードが利用できないと、
maxUnavailableおよび Pod 中断バジェットに影響するため、利用できないノードがあると、更新期間に大きな影響を与える可能性があります。ターミナルからノードのステータスを確認するには、次のコマンドを実行します。
$ oc get node出力例
NAME STATUS ROLES AGE VERSION ip-10-0-137-31.us-east-2.compute.internal Ready,SchedulingDisabled worker 12d v1.23.5+3afdacb ip-10-0-151-208.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-176-138.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-183-194.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacb ip-10-0-204-102.us-east-2.compute.internal Ready master 12d v1.23.5+3afdacb ip-10-0-207-224.us-east-2.compute.internal Ready worker 12d v1.23.5+3afdacbノードのステータスが
NotReadyまたはSchedulingDisabledの場合、ノードは使用できず、更新期間に影響します。Compute
Node を展開することで、Web コンソールの Administrator パースペクティブからノードのステータスを確認できます。
1.4.2.3. クラスター Operator の更新期間の例
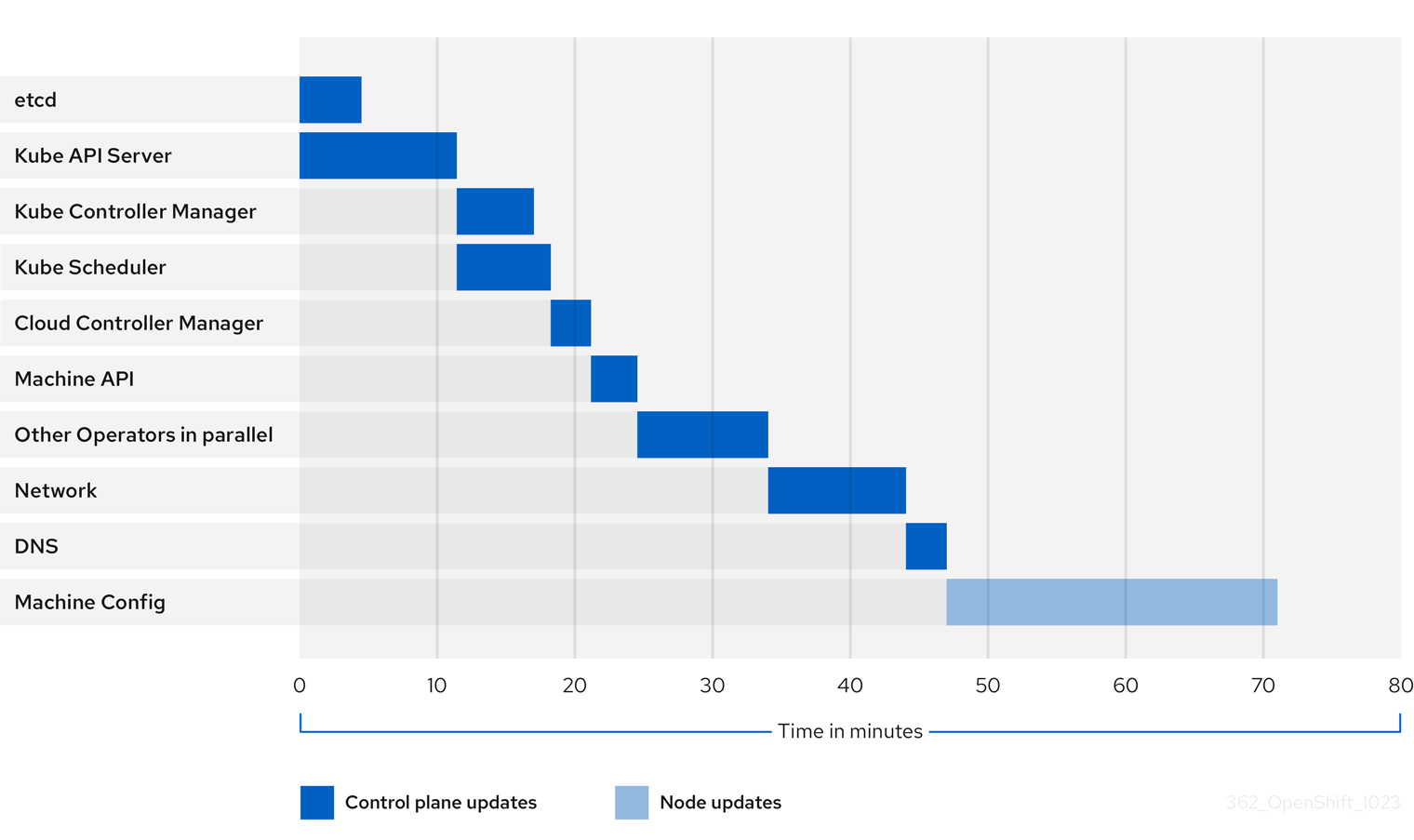
前の図は、クラスター Operator が新しいバージョンに更新するのにかかる時間の例を示しています。この例は、3 ノードの AWS OVN クラスターに基づいています。このクラスターには、正常なコンピュート MachineConfigPool があり、ドレインに時間がかかるワークロードがなく、4.13 から 4.14 に更新されます。
- クラスターとその Operator の具体的な更新期間は、ターゲットバージョン、ノードの量、ノードにスケジュールされたワークロードの種類など、クラスターのいくつかの特性に基づいて変化する可能性があります。
- Cluster Version Operator などの一部のオペレーターは、短時間で自身を更新します。これらの Operator は図から省略されているか、「並列のその他の Operator」というラベルが付いたより広範な Operator のグループに含まれています。
各クラスター Operator には、それ自体の更新にかかる時間に影響する特性があります。たとえば、この例の Kube API Server Operator の更新には 11 分以上かかりました。これは、kube-apiserver が正常な終了サポートを提供しているためです。つまり、実行中の既存のリクエストは正常に完了できます。これにより、kube-apiserver のシャットダウンに時間がかかる可能性があります。この Operator の場合は、更新中のクラスター機能の中断を防止および制限するために、更新速度が犠牲になります。
Operator の更新期間に影響を与えるもう 1 つの特性は、Operator が DaemonSet を利用するかどうかです。Network Operator と DNS Operator はフルクラスター DaemonSet を利用するため、バージョン変更のデプロイメントに時間がかかる場合があります。これが、これらの Operator の更新に時間がかかる理由の 1 つです。
一部の Operator の更新期間は、クラスター自体の特性に大きく依存します。たとえば、Machine Config Operator の更新では、クラスター内の各ノードにマシン設定の変更が適用されます。多くのノードを含むクラスターは、ノードが少ないクラスターと比較して、Machine Config Operator の更新にかかる時間が長くなります。
各クラスター Operator には、更新できるステージが割り当てられます。同じステージ内の Operator は同時に更新できますが、特定のステージの Operator は、前のステージがすべて完了するまで更新を開始できません。詳細は、「関連情報」セクションの「更新中にマニフェストが適用される方法について」を参照してください。
1.4.3. クラスター更新時間の概算
同様のクラスターの履歴更新期間は、将来のクラスター更新の最適な概算を提供します。ただし、履歴データが利用できない場合は、次の規則を使用してクラスターの更新時間を概算することができます。
Cluster update time = CVO target update payload deployment time + (# node update iterations x MCO node update time)
ノード更新反復は、並行して更新される 1 つ以上のノードで構成されます。コントロールプレーンノードは常に、コンピュートノードと並行して更新されます。さらに、maxUnavailable 値に基づいて、1 つ以上のコンピュートノードを並行して更新できます。
OpenShift Container Platform のすべてのマシン設定プールにおける maxUnavailable のデフォルト設定は 1 です。この値を変更せず、一度に 1 つのコントロールプレーンノードを更新することを推奨します。コントロールプレーンプールのこの値を 3 に変更しないでください。
例えば、更新時間を概算するには、3 つのコントロールプレーンノードと 6 つのコンピュートノードを持つ OpenShift Container Platform クラスターがあり、各ホストの再起動に約 5 分かかるとします。
特定のノードの再起動にかかる時間は、大幅に異なります。クラウドインスタンスでは、再起動に約 1 ~ 2 分かかる場合がありますが、物理的なベアメタルホストでは、再起動に 15 分以上かかる場合があります。
シナリオ 1:
コントロールプレーンとコンピュートノードの Machine Config Pool (MCP) の両方で maxUnavailable を 1 に設定すると、6 つのコンピュートノードすべてが反復ごとに次々と更新されます。
Cluster update time = 60 + (6 x 5) = 90 minutesシナリオ 2
コンピュートノード MCP の maxUnavailable を 2 に設定すると、2 つのコンピュートノードが反復ごとに並行して更新されます。したがって、すべてのノードを更新するには合計 3 回の反復が必要です。
Cluster update time = 60 + (3 x 5) = 75 minutes
maxUnavailable のデフォルト設定は、OpenShift Container Platform のすべての MCP で 1 です。コントロールプレーン MCP で maxUnavailable を変更しないことを推奨します。
1.4.4. Red Hat Enterprise Linux (RHEL) コンピュートノード
Red Hat Enterprise Linux (RHEL) コンピュートノードでは、ノードのバイナリーコンポーネントを更新するために openshift-ansible を追加で使用する必要があります。RHEL コンピュートノードの更新に費やされる実際の時間は、Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートノードと大きく変わらないはずです。