4.14. トラブルシューティング
OpenShift CLI ツール または Velero CLI ツール を使用して、Velero カスタムリソース (CR) をデバッグできます。Velero CLI ツールは、より詳細なログおよび情報を提供します。
インストールの問題、CR のバックアップと復元の問題、および Restic の問題 を確認できます。
ログと CR 情報は、must-gather ツール を使用して収集できます。
Velero CLI ツールは、次の方法で入手できます。
- Velero CLI ツールをダウンロードする
- クラスター内の Velero デプロイメントで Velero バイナリーにアクセスする
4.14.1. Velero CLI ツールをダウンロードする
Velero のドキュメントページ の手順に従って、Velero CLI ツールをダウンロードしてインストールできます。
このページには、以下に関する手順が含まれています。
- Homebrew を使用した macOS
- GitHub
- Chocolatey を使用した Windows
前提条件
- DNS とコンテナーネットワークが有効になっている、v1.16 以降の Kubernetes クラスターにアクセスできる。
-
kubectlをローカルにインストールしている。
手順
- ブラウザーを開き、Velero Web サイト上の "Install the CLI" に移動します。
- macOS、GitHub、または Windows の適切な手順に従います。
- 使用している OADP および OpenShift Container Platform のバージョンに適切な Velero バージョンをダウンロードします。
4.14.1.1. OADP-Velero-OpenShift Container Platform バージョンの関係
| OADP のバージョン | Velero のバージョン | OpenShift Container Platform バージョン |
|---|---|---|
| 1.1.0 | 4.9 以降 | |
| 1.1.1 | 4.9 以降 | |
| 1.1.2 | 4.9 以降 | |
| 1.1.3 | 4.9 以降 | |
| 1.1.4 | 4.9 以降 | |
| 1.1.5 | 4.9 以降 | |
| 1.1.6 | 4.11 以降 | |
| 1.1.7 | 4.11 以降 | |
| 1.2.0 | 4.11 以降 | |
| 1.2.1 | 4.11 以降 | |
| 1.2.2 | 4.11 以降 | |
| 1.2.3 | 4.11 以降 | |
| 1.3.0 | 4.10-4.15 | |
| 1.3.1 | 4.10-4.15 | |
| 1.3.2 | 4.10-4.15 | |
| 1.4.0 | 4.14-4.18 | |
| 1.4.1 | 4.14-4.18 | |
| 1.4.2 | 4.14-4.18 |
4.14.2. クラスター内の Velero デプロイメントで Velero バイナリーにアクセスする
shell コマンドを使用して、クラスター内の Velero デプロイメントの Velero バイナリーにアクセスできます。
前提条件
-
DataProtectionApplicationカスタムリソースのステータスがReconcile completeである。
手順
次のコマンドを入力して、必要なエイリアスを設定します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.14.3. OpenShift CLI ツールを使用した Velero リソースのデバッグ
OpenShift CLI ツールを使用して Velero カスタムリソース (CR) と Velero Pod ログを確認することで、失敗したバックアップまたは復元をデバッグできます。
Velero CR
oc describe コマンドを使用して、Backup または Restore CR に関連する警告とエラーの要約を取得します。
$ oc describe <velero_cr> <cr_name>
Velero Pod ログ
oc logs コマンドを使用して、Velero Pod ログを取得します。
$ oc logs pod/<velero>
Velero Pod のデバッグログ
次の例に示すとおり、DataProtectionApplication リソースで Velero ログレベルを指定できます。
このオプションは、OADP 1.0.3 以降で使用できます。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
次の logLevel 値を使用できます。
-
trace -
debug -
info -
warning -
error -
致命的 -
panic
ほとんどのログには info logLevel 値を使用することが推奨されます。
4.14.4. Velero CLI ツールを使用した Velero リソースのデバッグ
Velero CLI ツールを使用して、Backup および Restore カスタムリソース (CR) をデバッグし、ログを取得できます。
Velero CLI ツールは、OpenShift CLI ツールよりも詳細な情報を提供します。
構文
oc exec コマンドを使用して、Velero CLI コマンドを実行します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> <command> <cr_name>
例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
ヘルプオプション
velero --help オプションを使用して、すべての Velero CLI コマンドをリスト表示します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ --help
describe コマンド
velero describe コマンドを使用して、Backup または Restore CR に関連する警告とエラーの要約を取得します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> describe <cr_name>
例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
次の種類の復元エラーと警告が、velero describe リクエストの出力に表示されます。
-
Velero: Velero 自体の操作に関連するメッセージのリスト (クラウドへの接続、バックアップファイルの読み取りなどに関連するメッセージなど) -
Cluster: クラスタースコープのリソースのバックアップまたは復元に関連するメッセージのリスト -
Namespaces: namespace に保存されているリソースのバックアップまたは復元に関連するメッセージのリスト
これらのカテゴリーのいずれかで 1 つ以上のエラーが発生すると、Restore 操作のステータスが PartiallyFailed になり、Completed ではなくなります。警告によって完了ステータスが変化することはありません。
-
リソース固有のエラー、つまり
ClusterおよびNamespacesエラーの場合、restore describe --details出力に、Velero が復元に成功したすべてのリソースのリストが含まれています。このようなエラーが発生したリソースは、そのリソースが実際にクラスター内に存在するかどうかを確認してください。 describeコマンドの出力にVeleroエラーがあっても、リソース固有のエラーがない場合は、ワークロードの復元で実際の問題が発生することなく復元が完了した可能性があります。ただし、復元後のアプリケーションを十分に検証してください。たとえば、出力に
PodVolumeRestoreまたはノードエージェント関連のエラーが含まれている場合は、PodVolumeRestoresとDataDownloadsのステータスを確認します。これらのいずれも失敗していないか、まだ実行中である場合は、ボリュームデータが完全に復元されている可能性があります。
logs コマンド
velero logs コマンドを使用して、Backup または Restore CR のログを取得します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> logs <cr_name>
例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf
4.14.5. メモリーまたは CPU の不足により Pod がクラッシュまたは再起動する
メモリーまたは CPU の不足により Velero または Restic Pod がクラッシュした場合、これらのリソースのいずれかに対して特定のリソースリクエストを設定できます。
関連情報
4.14.5.1. Velero Pod のリソースリクエストの設定
oadp_v1alpha1_dpa.yaml ファイルの configuration.velero.podConfig.resourceAllocations 仕様フィールドを使用して、Velero Pod に対する特定のリソース要求を設定できます。
手順
YAML ファイルで
CPUおよびmemoryリソースのリクエストを設定します。Velero ファイルの例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations: 1 requests: cpu: 200m memory: 256Mi- 1
- リストされている
resourceAllocationsは、平均使用量です。
4.14.5.2. Restic Pod のリソースリクエストの設定
configuration.restic.podConfig.resourceAllocations 仕様フィールドを使用して、Restic Pod の特定のリソース要求を設定できます。
手順
YAML ファイルで
CPUおよびmemoryリソースのリクエストを設定します。Restic ファイルの例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations: 1 requests: cpu: 1000m memory: 16Gi- 1
- リストされている
resourceAllocationsは、平均使用量です。
リソース要求フィールドの値は、Kubernetes リソース要件と同じ形式に従う必要があります。また、configuration.velero.podConfig.resourceAllocations または configuration.restic.podConfig.resourceAllocations を指定しない場合、Velero Pod または Restic Pod のデフォルトの resources 仕様は次のようになります。
requests: cpu: 500m memory: 128Mi
4.14.6. StorageClass が NFS の場合、PodVolumeRestore は完了しない
Restic または Kopia を使用して NFS を復元するときにボリュームが複数あると、復元操作は失敗します。PodVolumeRestore は、次のエラーで失敗するか、復元を試行し続けた後に最終的に失敗します。
エラーメッセージ
Velero: pod volume restore failed: data path restore failed: \ Failed to run kopia restore: Failed to copy snapshot data to the target: \ restore error: copy file: error creating file: \ open /host_pods/b4d...6/volumes/kubernetes.io~nfs/pvc-53...4e5/userdata/base/13493/2681: \ no such file or directory
原因
復元する 2 つのボリュームの NFS マウントパスは一意ではありません。その結果、velero ロックファイルは復元中に NFS サーバー上の同じファイルを使用するため、PodVolumeRestore が失敗します。
解決方法
この問題は、deploy/class.yaml ファイルで nfs-subdir-external-provisioner の StorageClass を定義しながら、ボリュームごとに一意の pathPattern を設定することで解決できます。次の nfs-subdir-external-provisioner StorageClass の例を使用します。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
pathPattern: "${.PVC.namespace}/${.PVC.annotations.nfs.io/storage-path}" 1
onDelete: delete- 1
- ラベル、アノテーション、名前、namespace などの
PVCメタデータを使用してディレクトリーパスを作成するためのテンプレートを指定します。メタデータを指定するには、${.PVC.<metadata>}を使用します。たとえば、フォルダーに<pvc-namespace>-<pvc-name>という名前を付けるには、pathPatternとして${.PVC.namespace}-${.PVC.name}使用します。
4.14.7. Velero と受付 Webhook に関する問題
Velero では、復元中に受付 Webhook の問題を解決する機能が制限されています。受付 Webhook を使用するワークロードがある場合は、追加の Velero プラグインを使用するか、ワークロードの復元方法を変更する必要がある場合があります。
通常、受付 Webhook を使用するワークロードでは、最初に特定の種類のリソースを作成する必要があります。通常、受付 Webhook は子リソースをブロックするため、これは特にワークロードに子リソースがある場合に当てはまります。
たとえば、service.serving.knative.dev などの最上位オブジェクトを作成または復元すると、通常、子リソースが自動的に作成されます。最初にこれを行う場合、Velero を使用してこれらのリソースを作成および復元する必要はありません。これにより、Velero が使用する可能性のある受付 Webhook によって子リソースがブロックされるという問題が回避されます。
4.14.7.1. 受付 Webhook を使用する Velero バックアップの回避策の復元
このセクションでは、受付 Webhook を使用するいくつかのタイプの Velero バックアップのリソースを復元するために必要な追加の手順を説明します。
4.14.7.1.1. Knative リソースの復元
Velero を使用して受付 Webhook を使用する Knative リソースをバックアップする際に問題が発生する場合があります。
受付 Webhook を使用する Knative リソースをバックアップおよび復元する場合は、常に最上位の Service リソースを最初に復元することで、このような問題を回避できます。
手順
最上位の
service.serving.knavtive.dev Serviceリソースを復元します。$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.14.7.1.2. IBM AppConnect リソースの復元
Velero を使用して受付 Webhook を持つ IBM® AppConnect リソースを復元するときに問題が発生した場合は、この手順のチェックを実行できます。
手順
クラスター内の
kind: MutatingWebhookConfigurationの受付プラグインの変更があるかチェックします。$ oc get mutatingwebhookconfigurations
-
各
kind: MutatingWebhookConfigurationの YAML ファイルを調べて、問題が発生しているオブジェクトの作成をブロックするルールがないことを確認します。詳細は、Kubernetes の公式ドキュメント を参照してください。 -
バックアップ時に使用される
type: Configuration.appconnect.ibm.com/v1beta1のspec.versionが、インストールされている Operator のサポート対象であることを確認してください。
4.14.7.2. OADP プラグインの既知の問題
次のセクションでは、OpenShift API for Data Protection (OADP) プラグインの既知の問題を説明します。
4.14.7.2.1. シークレットがないことで、イメージストリームのバックアップ中に Velero プラグインでパニックが発生する
バックアップとバックアップ保存場所 (BSL) が Data Protection Application (DPA) の範囲外で管理されている場合、OADP コントローラー (つまり DPA の調整) によって関連する oadp-<bsl_name>-<bsl_provider>-registry-secret が作成されません。
バックアップを実行すると、OpenShift Velero プラグインがイメージストリームバックアップでパニックになり、次のパニックエラーが表示されます。
024-02-27T10:46:50.028951744Z time="2024-02-27T10:46:50Z" level=error msg="Error backing up item" backup=openshift-adp/<backup name> error="error executing custom action (groupResource=imagestreams.image.openshift.io, namespace=<BSL Name>, name=postgres): rpc error: code = Aborted desc = plugin panicked: runtime error: index out of range with length 1, stack trace: goroutine 94…
4.14.7.2.1.1. パニックエラーを回避するための回避策
Velero プラグインのパニックエラーを回避するには、次の手順を実行します。
カスタム BSL に適切なラベルを付けます。
$ oc label backupstoragelocations.velero.io <bsl_name> app.kubernetes.io/component=bsl
BSL にラベルを付けた後、DPA の調整を待ちます。
注記DPA 自体に軽微な変更を加えることで、強制的に調整を行うことができます。
DPA の調整では、適切な
oadp-<bsl_name>-<bsl_provider>-registry-secretが作成されていること、正しいレジストリーデータがそこに設定されていることを確認します。$ oc -n openshift-adp get secret/oadp-<bsl_name>-<bsl_provider>-registry-secret -o json | jq -r '.data'
4.14.7.2.2. OpenShift ADP Controller のセグメンテーション違反
cloudstorage と restic の両方を有効にして DPA を設定すると、openshift-adp-controller-manager Pod がクラッシュし、Pod がクラッシュループのセグメンテーション違反で失敗するまで無期限に再起動します。
velero または cloudstorage は相互に排他的なフィールドであるため、どちらか一方だけ定義できます。
-
veleroとcloudstorageの両方が定義されている場合、openshift-adp-controller-managerは失敗します。 -
veleroとcloudstorageのいずれも定義されていない場合、openshift-adp-controller-managerは失敗します。
この問題の詳細は、OADP-1054 を参照してください。
4.14.7.2.2.1. OpenShift ADP Controller のセグメンテーション違反の回避策
DPA の設定時に、velero または cloudstorage のいずれかを定義する必要があります。DPA で両方の API を定義すると、openshift-adp-controller-manager Pod がクラッシュループのセグメンテーション違反で失敗します。
4.14.7.3. Velero プラグインがメッセージ "received EOF, stopping recv loop" を返す
Velero プラグインは、別のプロセスとして開始されます。Velero 操作が完了すると、成功したかどうかにかかわらず終了します。デバッグログの received EOF, stopping recv loop メッセージは、プラグイン操作が完了したことを示します。エラーが発生したわけではありません。
4.14.8. インストールの問題
Data Protection Application をインストールするときに、無効なディレクトリーまたは誤った認証情報を使用することによって問題が発生する可能性があります。
4.14.8.1. バックアップストレージに無効なディレクトリーが含まれています
Velero Pod ログにエラーメッセージ Backup storage contains invalid top-level directories が表示されます。
原因
オブジェクトストレージには、Velero ディレクトリーではないトップレベルのディレクトリーが含まれています。
解決方法
オブジェクトストレージが Velero 専用でない場合は、DataProtectionApplication マニフェストで spec.backupLocations.velero.objectStorage.prefix パラメーターを設定して、バケットの接頭辞を指定する必要があります。
4.14.8.2. 不正な AWS 認証情報
oadp-aws-registry Pod ログにエラーメッセージ InvalidAccessKeyId: The AWS Access Key Id you provided does not exist in our records. が表示されます。
Velero Pod ログには、エラーメッセージ NoCredentialProviders: no valid providers in chain が表示されます。
原因
Secret オブジェクトの作成に使用された credentials-velero ファイルの形式が正しくありません。
解決方法
次の例のように、credentials-velero ファイルが正しくフォーマットされていることを確認します。
サンプル credentials-velero ファイル
[default] 1 aws_access_key_id=AKIAIOSFODNN7EXAMPLE 2 aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
4.14.9. OADP Operator の問題
OpenShift API for Data Protection (OADP) Operator では、解決できない問題が原因で問題が発生する可能性があります。
4.14.9.1. OADP Operator がサイレントに失敗する
OADP Operator の S3 バケットは空である可能性がありますが、oc get po -n <OADP_Operator_namespace> コマンドを実行すると、Operator のステータスが Running であることがわかります。この場合、Operator は実行中であると誤報告するため、サイレントに失敗した と言われます。
原因
この問題は、クラウド認証情報で提供される権限が不十分な場合に発生します。
解決方法
Backup Storage Location (BSL) のリストを取得し、各 BSL のマニフェストで認証情報の問題を確認します。
手順
次のコマンドのいずれかを実行して、BSL のリストを取得します。
OpenShift CLI を使用する場合:
$ oc get backupstoragelocations.velero.io -A
Velero CLI を使用する場合:
$ velero backup-location get -n <OADP_Operator_namespace>
BSL のリストを使用し、次のコマンドを実行して各 BSL のマニフェストを表示し、各マニフェストにエラーがないか調べます。
$ oc get backupstoragelocations.velero.io -n <namespace> -o yaml
結果の例:
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""
4.14.10. OADP タイムアウト
タイムアウトを延長すると、複雑なプロセスやリソースを大量に消費するプロセスが途中で終了することなく正常に完了できます。この設定により、エラー、再試行、または失敗の可能性を減らすことができます。
過度に長いタイムアウトを設定しないように、論理的な方法でタイムアウト延長のバランスをとってください。過度に長いと、プロセス内の根本的な問題が隠れる可能性があります。プロセスのニーズとシステム全体のパフォーマンスを満たす適切なタイムアウト値を慎重に検討して、監視してください。
次に、さまざまな OADP タイムアウトと、これらのパラメーターをいつどのように実装するかの手順を示します。
4.14.10.1. Restic タイムアウト
spec.configuration.nodeAgent.timeout パラメーターは、Restic タイムアウトを定義します。デフォルト値は 1h です。
次に該当する場合は、nodeAgent セクションで Restic timeout パラメーターを使用してください。
- PV データの使用量の合計が 500GB を超える Restic バックアップの場合。
バックアップが次のエラーでタイムアウトになる場合:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
手順
DataProtectionApplicationカスタムリソース (CR) マニフェストのspec.configuration.nodeAgent.timeoutブロックの値を編集します。次に例を示します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: nodeAgent: enable: true uploaderType: restic timeout: 1h # ...
4.14.10.2. Velero リソースのタイムアウト
resourceTimeout は Velero カスタムリソース定義 (CRD) の可用性、volumeSnapshot の削除、リポジトリーの可用性など、タイムアウトが発生する前に複数の Velero リソースを待機する時間を定義します。デフォルトは 10m です。
次のシナリオでは resourceTimeout を使用します。
合計 PV データ使用量が 1TB を超えるバックアップの場合。このパラメーターは、バックアップを完了としてマークする前に、Velero が Container Storage Interface (CSI) スナップショットをクリーンアップまたは削除しようとするときのタイムアウト値として使用されます。
- このクリーンアップのサブタスクは VSC にパッチを適用しようとします。このタイムアウトはそのタスクに使用できます。
- Restic または Kopia のファイルシステムベースのバックアップのバックアップリポジトリーを作成または準備できるようにするため。
- カスタムリソース (CR) またはバックアップからリソースを復元する前に、クラスター内で Velero CRD が利用可能かどうかを確認します。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.resourceTimeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.14.10.3. Data Mover のタイムアウト
timeout は、VolumeSnapshotBackup および VolumeSnapshotRestore を完了するためにユーザーが指定したタイムアウトです。デフォルト値は 10m です。
次のシナリオでは、Data Mover timeout を使用します。
-
VolumeSnapshotBackups(VSB) およびVolumeSnapshotRestores(VSR) を作成する場合は、10 分後にタイムアウトします。 -
合計 PV データ使用量が 500GB を超える大規模環境向け。
1hのタイムアウトを設定します。 -
VolumeSnapshotMover(VSM) プラグインを使用します。 - OADP 1.1.x のみ。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.features.dataMover.timeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.14.10.4. CSI スナップショットのタイムアウト
CSISnapshotTimeout は、タイムアウトとしてエラーを返す前に、CSI VolumeSnapshot ステータスが ReadyToUse になるまで待機する作成時の時間を指定します。デフォルト値は 10m です。
以下のシナリオでは、CSISnapshotTimeout を使用します。
- CSI プラグイン。
- スナップショットの作成に 10 分以上かかる可能性がある非常に大規模なストレージボリュームの場合。ログにタイムアウトが見つかった場合は、このタイムアウトを調整します。
通常、CSISnapshotTimeout のデフォルト値は、デフォルト設定で大規模なストレージボリュームに対応できるため、調整する必要はありません。
手順
次の例のように、
BackupCR マニフェストのspec.csiSnapshotTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.14.10.5. Velero におけるアイテム操作のデフォルトタイムアウト
defaultItemOperationTimeout では、非同期の BackupItemActions および RestoreItemActions がタイムアウトになる前に完了するのを待機する時間を定義します。デフォルト値は 1h です。
以下のシナリオでは、defaultItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
- 特定のバックアップまたは復元が非同期アクションの完了を待機する時間を指定します。OADP 機能のコンテキストでは、この値は、Container Storage Interface (CSI) Data Mover 機能に関連する非同期アクションに使用されます。
-
defaultItemOperationTimeoutが、defaultItemOperationTimeoutを使用して Data Protection Application (DPA) に定義されている場合、バックアップおよび復元操作の両方に適用されます。itemOperationTimeoutでは、以下の "Item operation timeout - restore" セクションおよび "Item operation timeout - backup" セクションで説明されているように、バックアップのみを定義するか、これらの CR の復元のみを定義できます。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.defaultItemOperationTimeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.14.10.6. アイテム操作のタイムアウト - 復元
ItemOperationTimeout は RestoreItemAction 操作の待機に使用される時間を指定します。デフォルト値は 1h です。
以下のシナリオでは、復元 ItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
-
Data Mover の場合は、
BackupStorageLocationにアップロードおよびダウンロードします。タイムアウトに達しても復元アクションが完了しない場合、失敗としてマークされます。ストレージボリュームのサイズが大きいため、タイムアウトの問題が原因で Data Mover の操作が失敗する場合は、このタイムアウト設定を増やす必要がある場合があります。
手順
次の例のように、
RestoreCR マニフェストのRestore.spec.itemOperationTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.14.10.7. アイテム操作のタイムアウト - バックアップ
ItemOperationTimeout は、非同期 BackupItemAction 操作の待機時間を指定します。デフォルト値は 1h です。
次のシナリオでは、バックアップ ItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
-
Data Mover の場合は、
BackupStorageLocationにアップロードおよびダウンロードします。タイムアウトに達してもバックアップアクションが完了しない場合は、失敗としてマークされます。ストレージボリュームのサイズが大きいため、タイムアウトの問題が原因で Data Mover の操作が失敗する場合は、このタイムアウト設定を増やす必要がある場合があります。
手順
次の例のように、
BackupCR マニフェストのBackup.spec.itemOperationTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.14.11. CR の問題のバックアップおよび復元
Backup および Restore カスタムリソース (CR) でこれらの一般的な問題が発生する可能性があります。
4.14.11.1. バックアップ CR はボリュームを取得できません
Backup CR は、エラーメッセージ InvalidVolume.NotFound: The volume ‘vol-xxxx’ does not exist を表示します。
原因
永続ボリューム (PV) とスナップショットの場所は異なるリージョンにあります。
解決方法
-
DataProtectionApplicationマニフェストのspec.snapshotLocations.velero.config.regionキーの値を編集して、スナップショットの場所が PV と同じリージョンにあるようにします。 -
新しい
BackupCR を作成します。
4.14.11.2. バックアップ CR ステータスは進行中のままです
Backup CR のステータスは InProgress のフェーズのままであり、完了しません。
原因
バックアップが中断された場合は、再開することができません。
解決方法
BackupCR の詳細を取得します。$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>BackupCR を削除します。$ oc delete backups.velero.io <backup> -n openshift-adp
進行中の
BackupCR はファイルをオブジェクトストレージにアップロードしていないため、バックアップの場所をクリーンアップする必要はありません。-
新しい
BackupCR を作成します。 Velero バックアップの詳細を表示します。
$ velero backup describe <backup-name> --details
4.14.11.3. バックアップ CR ステータスが PartiallyFailed のままになる
Restic が使用されていない Backup CR のステータスは、PartiallyFailed フェーズのままで、完了しません。関連する PVC のスナップショットは作成されません。
原因
CSI スナップショットクラスに基づいてバックアップが作成されているが、ラベルがない場合、CSI スナップショットプラグインはスナップショットの作成に失敗します。その結果、Velero Pod は次のようなエラーをログに記録します。
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq
解決方法
BackupCR を削除します。$ oc delete backups.velero.io <backup> -n openshift-adp
-
必要に応じて、
BackupStorageLocationに保存されているデータをクリーンアップして、領域を解放します。 ラベル
velero.io/csi-volumesnapshot-class=trueをVolumeSnapshotClassオブジェクトに適用します。$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true
-
新しい
BackupCR を作成します。
4.14.12. Restic の問題
Restic を使用してアプリケーションのバックアップを作成すると、これらの問題が発生する可能性があります。
4.14.12.1. root_squash が有効になっている NFS データボリュームの Restic パーミッションエラー
Restic Pod ログには、エラーメッセージ controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied" が表示されます。
原因
NFS データボリュームで root_squash が有効になっている場合、Restic は nfsnobody にマッピングされ、バックアップを作成する権限がありません。
解決方法
この問題を解決するには、Restic の補足グループを作成し、そのグループ ID を DataProtectionApplication マニフェストに追加します。
-
NFS データボリューム上に
Resticの補足グループを作成します。 -
NFS ディレクトリーに
setgidビットを設定して、グループの所有権が継承されるようにします。 spec.configuration.nodeAgent.supplementalGroupsパラメーターとグループ ID をDataProtectionApplicationマニフェストに追加します。次に例を示します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication # ... spec: configuration: nodeAgent: enable: true uploaderType: restic supplementalGroups: - <group_id> 1 # ...- 1
- 補助グループ ID を指定します。
-
ResticPod が再起動し、変更が適用されるまで待機します。
4.14.12.2. バケットが空になった後に、Restic Backup CR を再作成することはできない
namespace の Restic Backup CR を作成し、オブジェクトストレージバケットを空にしてから、同じ namespace の Backup CR を再作成すると、再作成された Backup CR は失敗します。
velero Pod ログにエラーメッセージstderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location? が表示されます。
原因
オブジェクトストレージから Restic ディレクトリーが削除された場合、Velero は ResticRepository マニフェストから Restic リポジトリーを再作成または更新しません。詳細は、Velero issue 4421 を参照してください。
解決方法
次のコマンドを実行して、関連する Restic リポジトリーを namespace から削除します。
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>
次のエラーログでは、
mysql-persistentが問題のある Restic リポジトリーです。わかりやすくするために、リポジトリーの名前は斜体で表示されます。time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.14.12.3. PSA ポリシーの変更により、OCP 4.14 での Restic 復元が部分的に失敗する
OpenShift Container Platform 4.14 は、Restic 復元プロセス中に Pod の readiness を妨げる可能性がある Pod Security Admission (PSA) ポリシーを強制します。
Pod の作成時に SecurityContextConstraints (SCC) リソースが見つからず、Pod 上の PSA ポリシーが必要な標準を満たすように設定されていないと、Pod の許可は拒否されます。
この問題は、Velero のリソース復元順序が原因で発生します。
サンプルエラー
\"level=error\" in line#2273: time=\"2023-06-12T06:50:04Z\" level=error msg=\"error restoring mysql-869f9f44f6-tp5lv: pods\\\ "mysql-869f9f44f6-tp5lv\\\" is forbidden: violates PodSecurity\\\ "restricted:v1.24\\\": privil eged (container \\\"mysql\\\ " must not set securityContext.privileged=true), allowPrivilegeEscalation != false (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.capabilities.drop=[\\\"ALL\\\"]), seccompProfile (pod or containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.seccompProfile.type to \\\ "RuntimeDefault\\\" or \\\"Localhost\\\")\" logSource=\"/remote-source/velero/app/pkg/restore/restore.go:1388\" restore=openshift-adp/todolist-backup-0780518c-08ed-11ee-805c-0a580a80e92c\n velero container contains \"level=error\" in line#2447: time=\"2023-06-12T06:50:05Z\" level=error msg=\"Namespace todolist-mariadb, resource restore error: error restoring pods/todolist-mariadb/mysql-869f9f44f6-tp5lv: pods \\\ "mysql-869f9f44f6-tp5lv\\\" is forbidden: violates PodSecurity \\\"restricted:v1.24\\\": privileged (container \\\ "mysql\\\" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (containers \\\ "restic-wait\\\",\\\"mysql\\\" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.capabilities.drop=[\\\"ALL\\\"]), seccompProfile (pod or containers \\\ "restic-wait\\\", \\\"mysql\\\" must set securityContext.seccompProfile.type to \\\ "RuntimeDefault\\\" or \\\"Localhost\\\")\" logSource=\"/remote-source/velero/app/pkg/controller/restore_controller.go:510\" restore=openshift-adp/todolist-backup-0780518c-08ed-11ee-805c-0a580a80e92c\n]",
解決方法
DPA カスタムリソース (CR) で、Velero サーバーの
restore-resource-prioritiesフィールドを確認または設定して、securitycontextconstraintsがリソースのリストのpodsの前に順番にリストされていることを確認します。$ oc get dpa -o yaml
DPA CR の例
# ... configuration: restic: enable: true velero: args: restore-resource-priorities: 'securitycontextconstraints,customresourcedefinitions,namespaces,storageclasses,volumesnapshotclass.snapshot.storage.k8s.io,volumesnapshotcontents.snapshot.storage.k8s.io,volumesnapshots.snapshot.storage.k8s.io,datauploads.velero.io,persistentvolumes,persistentvolumeclaims,serviceaccounts,secrets,configmaps,limitranges,pods,replicasets.apps,clusterclasses.cluster.x-k8s.io,endpoints,services,-,clusterbootstraps.run.tanzu.vmware.com,clusters.cluster.x-k8s.io,clusterresourcesets.addons.cluster.x-k8s.io' 1 defaultPlugins: - gcp - openshift- 1
- 既存のリストアリソース優先順位リストがある場合は、その既存のリストを完全なリストと組み合わせてください。
- デプロイメントの警告が発生しないように、Fixing PodSecurity Admission warnings for deployments で説明されているように、アプリケーション Pod のセキュリティー標準が調整されていることを確認します。アプリケーションがセキュリティー標準に準拠していない場合は、SCC に関係なくエラーが発生する可能性があります。
この解決策は一時的なものであり、これに対処するために継続的な議論が進行中です。
4.14.13. must-gather ツールの使用
must-gather ツールを使用して、OADP カスタムリソースのログ、メトリック、および情報を収集できます。
must-gather データはすべてのカスタマーケースに割り当てられる必要があります。
次のデータ収集オプションを使用して、must-gather ツールを実行できます。
-
完全な
must-gatherデータ収集では、OADP Operator がインストールされているすべての namespace の Prometheus メトリクス、Pod ログ、および Velero CR 情報が収集されます。 -
重要な
must-gatherデータ収集では、Pod ログと Velero CR 情報を特定の期間 (たとえば、1 時間または 24 時間) 収集します。Prometheus メトリックと重複ログは含まれていません。 -
タイムアウト付きの
must-gatherデータ収集。失敗したBackupCR が多数ある場合は、データ収集に長い時間がかかる可能性があります。タイムアウト値を設定することでパフォーマンスを向上させることができます。 - Prometheus メトリックデータダンプは、Prometheus によって収集されたメトリックデータを含むアーカイブファイルをダウンロードします。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 -
OpenShift CLI (
oc) がインストールされている。 - OADP 1.3 および OADP 1.4 では、Red Hat Enterprise Linux (RHEL) 9.0 を使用する必要があります。
手順
-
must-gatherデータを保存するディレクトリーに移動します。 次のデータ収集オプションのいずれかに対して、
oc adm must-gatherコマンドを実行します。Prometheus メトリックを含む、完全な
must-gatherデータ収集:OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4
データは
must-gather/must-gather.tar.gzとして保存されます。このファイルを Red Hat カスタマーポータル で作成したサポートケースにアップロードすることができます。
Prometheus メトリックを使用しない、特定の期間の必須の
must-gatherデータ収集:OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 \ -- /usr/bin/gather_<time>_essential 1- 1
- 期間を時間単位で指定します。許可される値は、
1h、6h、24h、72h、またはallです。たとえば、gather_1h_essentialまたはgather_all_essentialです。
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 \ -- /usr/bin/gather_<time>_essential 1- 1
- 期間を時間単位で指定します。許可される値は、
1h、6h、24h、72h、またはallです。たとえば、gather_1h_essentialまたはgather_all_essentialです。
タイムアウト付きの
must-gatherデータ収集:OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 \ -- /usr/bin/gather_with_timeout <timeout> 1- 1
- タイムアウト値を秒単位で指定します。
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 \ -- /usr/bin/gather_with_timeout <timeout> 1- 1
- タイムアウト値を秒単位で指定します。
Prometheus メトリックデータダンプ:
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_metrics_dump
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_metrics_dump
この操作には長時間かかる場合があります。データは
must-gather/metrics/prom_data.tar.gzとして保存されます。
関連情報
4.14.13.1. 安全でない TLS 接続で must-gather を使用する
カスタム CA 証明書が使用されている場合、must-gather Pod は velero logs/describe の出力を取得できません。安全でない TLS 接続で must-gather ツールを使用するには、gather_without_tls フラグを must-gather コマンドに渡します。
手順
次のコマンドを使用して、値を
trueに設定したgather_without_tlsフラグをmust-gatherツールに渡します。OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_without_tls <true/false>
OADP 1.3 の場合は、次のコマンドを実行します。
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_without_tls <true/false>
デフォルトでは、フラグの値は
falseに設定されています。安全でない TLS 接続を許可するには、値をtrueに設定します。
4.14.13.2. must-gather ツールを使用する場合のオプションの組み合わせ
現時点では、たとえば安全でない TLS 接続を許可しながらタイムアウトしきい値を指定するなど、must-gather スクリプトを組み合わせることはできません。状況によっては、次の例のように must-gather コマンドラインで内部変数を設定することで、この制限を回避できます。
OADP 1.3 の場合:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
OADP 1.4 の場合:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
これらの例では、gather_with_timeout スクリプトを実行する前に skip_tls 変数を設定します。その結果、Gather_with_timeout と Gather_without_tls が組み合わされます。
この方法で指定できる他の変数は次のとおりです。
-
logs_since、デフォルト値は72h -
request_timeout、デフォルト値は0s
DataProtectionApplication カスタムリソース (CR) が s3Url および insecureSkipTLS: true で設定されている場合、CA 証明書がないため、CR は必要なログを収集しません。これらのログを収集するには、次のオプションを指定して must-gather コマンドを実行します。
OADP 1.3 の場合:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather_without_tls true
OADP 1.4 の場合:
$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.4 -- /usr/bin/gather_without_tls true
4.14.14. OADP モニタリング
OpenShift Container Platform は、ユーザーと管理者がクラスターを効果的に監視および管理できるだけでなく、クラスター上で実行されているユーザーアプリケーションやサービスのワークロードパフォーマンスを監視および分析できるようにする監視スタックを提供します (イベント発生時のアラートの受信など)。
4.14.14.1. OADP モニタリングの設定
OADP Operator は、OpenShift モニタリングスタックによって提供される OpenShift ユーザーワークロードモニタリングを利用して、Velero サービスエンドポイントからメトリックを取得します。モニタリングスタックを使用すると、ユーザー定義のアラートルールを作成したり、OpenShift メトリッククエリーフロントエンドを使用してメトリックをクエリーしたりできます。
ユーザーワークロードモニタリングを有効にすると、Grafana などの Prometheus 互換のサードパーティー UI を設定して使用し、Velero メトリックを視覚化することができます。
メトリックをモニタリングするには、ユーザー定義プロジェクトのモニタリングを有効にし、openshift-adp namespace に存在するすでに有効にな OADP サービスエンドポイントからそれらのメトリックを取得する ServiceMonitor リソースを作成する必要があります。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 - クラスター監視 config map が作成されました。
手順
openshift-monitoringnamespace でcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
dataセクションのconfig.yamlフィールドで、enableUserWorkloadオプションを追加または有効にします。apiVersion: v1 data: config.yaml: | enableUserWorkload: true 1 kind: ConfigMap metadata: # ...- 1
- このオプションを追加するか、
trueに設定します
しばらく待って、
openshift-user-workload-monitoringnamespace で次のコンポーネントが稼働しているかどうかを確認して、ユーザーワークロードモニタリングのセットアップを検証します。$ oc get pods -n openshift-user-workload-monitoring
出力例
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32s
openshift-user-workload-monitoringにuser-workload-monitoring-configConfigMap が存在することを確認します。存在する場合、この手順の残りの手順はスキップしてください。$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring
出力例
Error from server (NotFound): configmaps "user-workload-monitoring-config" not found
ユーザーワークロードモニタリングの
user-workload-monitoring-configConfigMapオブジェクトを作成し、2_configure_user_workload_monitoring.yamlファイル名に保存します。出力例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |
2_configure_user_workload_monitoring.yamlファイルを適用します。$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.14.14.2. OADP サービスモニターの作成
OADP は、DPA の設定時に作成される openshift-adp-velero-metrics-svc サービスを提供します。ユーザーのワークロード監視で使用されるサービスモニターは、定義されたサービスを指す必要があります。
次のコマンドを実行して、サービスの詳細を取得します。
手順
openshift-adp-velero-metrics-svcサービスが存在することを確認します。これには、ServiceMonitorオブジェクトのセレクターとして使用されるapp.kubernetes.io/name=veleroラベルが含まれている必要があります。$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h
既存のサービスラベルと一致する
ServiceMonitorYAML ファイルを作成し、そのファイルを3_create_oadp_service_monitor.yamlとして保存します。サービスモニターはopenshift-adp-velero-metrics-svcサービスが存在するopenshift-adpnamespace に作成されます。ServiceMonitorオブジェクトの例apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"3_create_oadp_service_monitor.yamlファイルを適用します。$ oc apply -f 3_create_oadp_service_monitor.yaml
出力例
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
検証
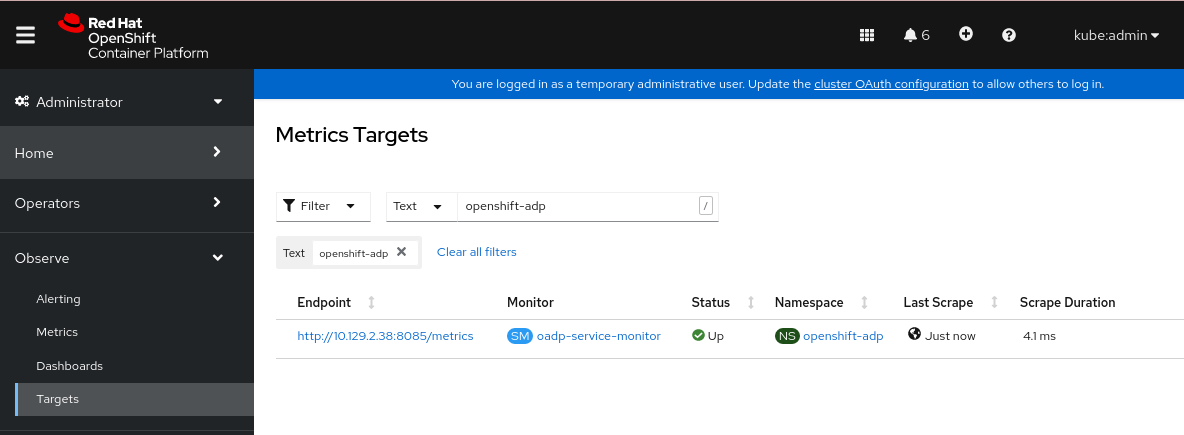
OpenShift Container Platform Web コンソールの Administrator パースペクティブを使用して、新しいサービスモニターが Up 状態であることを確認します。
-
Observe
Targets ページに移動します。 -
Filter が選択されていないこと、または User ソースが選択されていることを確認し、
Text検索フィールドにopenshift-adpと入力します。 サービスモニターの Status のステータスが Up であることを確認します。
図4.1 OADP メトリックのターゲット
-
Observe
4.14.14.3. アラートルールの作成
OpenShift Container Platform モニタリングスタックでは、アラートルールを使用して設定されたアラートを受信できます。OADP プロジェクトのアラートルールを作成するには、ユーザーワークロードの監視で収集されたメトリックの 1 つを使用します。
手順
サンプル
OADPBackupFailingアラートを含むPrometheusRuleYAML ファイルを作成し、4_create_oadp_alert_rule.yamlとして保存します。OADPBackupFailingアラートのサンプルapiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warningこのサンプルでは、アラートは次の条件で表示されます。
- 過去 2 時間に失敗した新しいバックアップの数が 0 より大きく増加しており、その状態が少なくとも 5 分間継続します。
-
最初の増加時間が 5 分未満の場合、アラートは
Pending状態になり、その後、Firing状態に変わります。
4_create_oadp_alert_rule.yamlファイルを適用して、openshift-adpnamespace にPrometheusRuleオブジェクトを作成します。$ oc apply -f 4_create_oadp_alert_rule.yaml
出力例
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
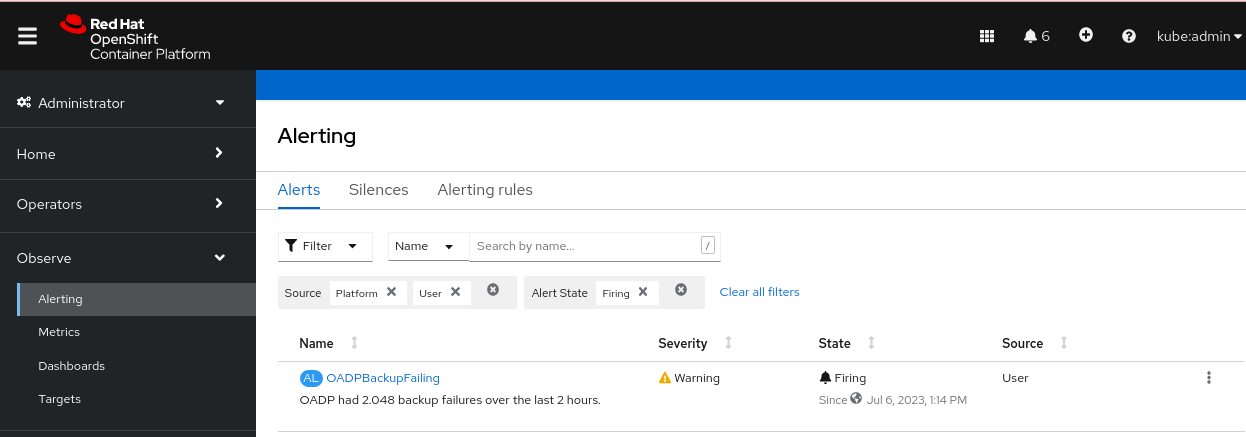
検証
アラートがトリガーされた後は、次の方法でアラートを表示できます。
- Developer パースペクティブで、Observe メニューを選択します。
Observe
Alerting メニューの下の Administrator パースペクティブで、Filter ボックスの User を選択します。それ以外の場合、デフォルトでは Platform アラートのみが表示されます。 図4.2 OADP バックアップ失敗アラート
関連情報
4.14.14.4. 利用可能なメトリックのリスト
これらは、OADP によって提供されるメトリックとその Type のリストです。
| メトリクス名 | 説明 | 型 |
|---|---|---|
|
| キャッシュから取得したバイト数 | カウンター |
|
| コンテンツがキャッシュから取得された回数 | カウンター |
|
| 不正なコンテンツがキャッシュから読み取られた回数 | カウンター |
|
| コンテンツがキャッシュ内で見つからずフェッチされた回数 | カウンター |
|
| 基盤となるストレージから取得したバイト数 | カウンター |
|
| 基盤となるストレージでコンテンツが見つからなかった回数 | カウンター |
|
| コンテンツをキャッシュに保存できなかった回数 | カウンター |
|
|
| カウンター |
|
|
| カウンター |
|
|
| カウンター |
|
|
| カウンター |
|
|
| カウンター |
|
|
| カウンター |
|
| 試行されたバックアップの合計数 | カウンター |
|
| 試行されたバックアップ削除の合計数 | カウンター |
|
| 失敗したバックアップ削除の合計数 | カウンター |
|
| 成功したバックアップ削除の合計数 | カウンター |
|
| バックアップの完了にかかる時間 (秒単位) | ヒストグラム |
|
| 失敗したバックアップの合計数 | カウンター |
|
| バックアップ中に発生したエラーの合計数 | ゲージ |
|
| バックアップされたアイテムの総数 | ゲージ |
|
| バックアップの最終ステータス。値 1 は成功、値 0 は成功です。 | ゲージ |
|
| 最後にバックアップが正常に実行された時刻、秒単位の Unix タイムスタンプ | ゲージ |
|
| 部分的に失敗したバックアップの合計数 | カウンター |
|
| 成功したバックアップの合計数 | カウンター |
|
| バックアップのサイズ (バイト単位) | ゲージ |
|
| 既存のバックアップの現在の数 | ゲージ |
|
| 検証に失敗したバックアップの合計数 | カウンター |
|
| 警告されたバックアップの総数 | カウンター |
|
| CSI が試行したボリュームスナップショットの合計数 | カウンター |
|
| CSI で失敗したボリュームスナップショットの総数 | カウンター |
|
| CSI が成功したボリュームスナップショットの総数 | カウンター |
|
| 試行された復元の合計数 | カウンター |
|
| 失敗したリストアの合計数 | カウンター |
|
| 部分的に失敗したリストアの合計数 | カウンター |
|
| 成功した復元の合計数 | カウンター |
|
| 現在の既存のリストアの数 | ゲージ |
|
| 検証に失敗したリストアの失敗の合計数 | カウンター |
|
| 試行されたボリュームスナップショットの総数 | カウンター |
|
| 失敗したボリュームスナップショットの総数 | カウンター |
|
| 成功したボリュームスナップショットの総数 | カウンター |
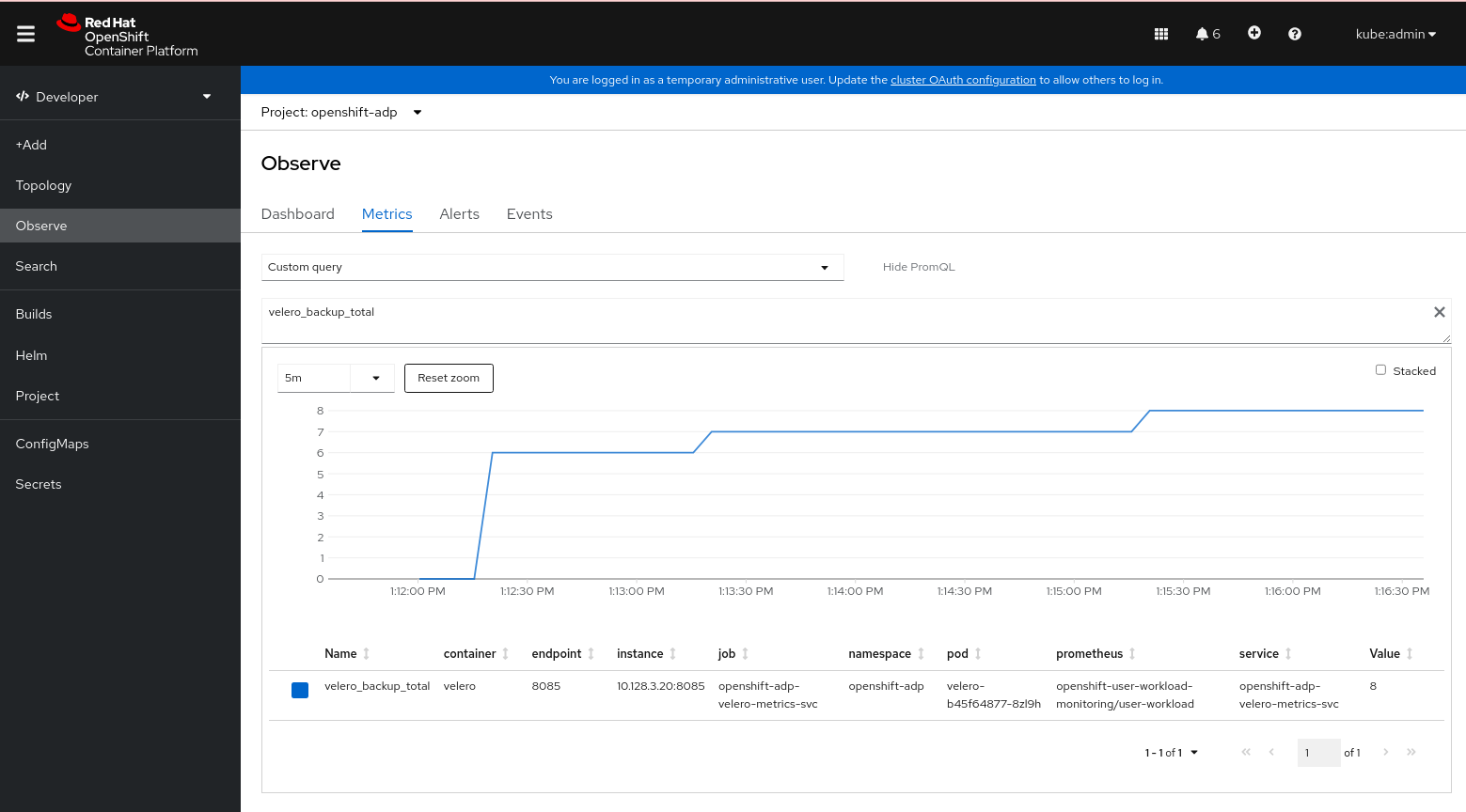
4.14.14.5. Observe UI を使用したメトリックの表示
OpenShift Container Platform Web コンソールのメトリックは、Administrator または Developer パースペクティブから表示できます。これらのパースペクティブには、openshift-adp プロジェクトへのアクセス権が必要です。
手順
Observe
Metrics ページに移動します。 Developer パースペクティブを使用している場合は、次の手順に従います。
- Custom query を選択するか、Show PromQL リンクをクリックします。
- クエリーを入力し、Enter をクリックします。
Administrator パースペクティブを使用している場合は、テキストフィールドに式を入力し、Run Queries を選択します。
図4.3 OADP メトリッククエリー