8.5. トラブルシューティング
8.5.1. インストーラーワークフローのトラブルシューティング
インストール環境のトラブルシューティングを行う前に、ベアメタルへのインストーラーでプロビジョニングされるインストールの全体的なフローを理解することは重要です。以下の図は、環境におけるステップごとのトラブルシューティングフローを示しています。
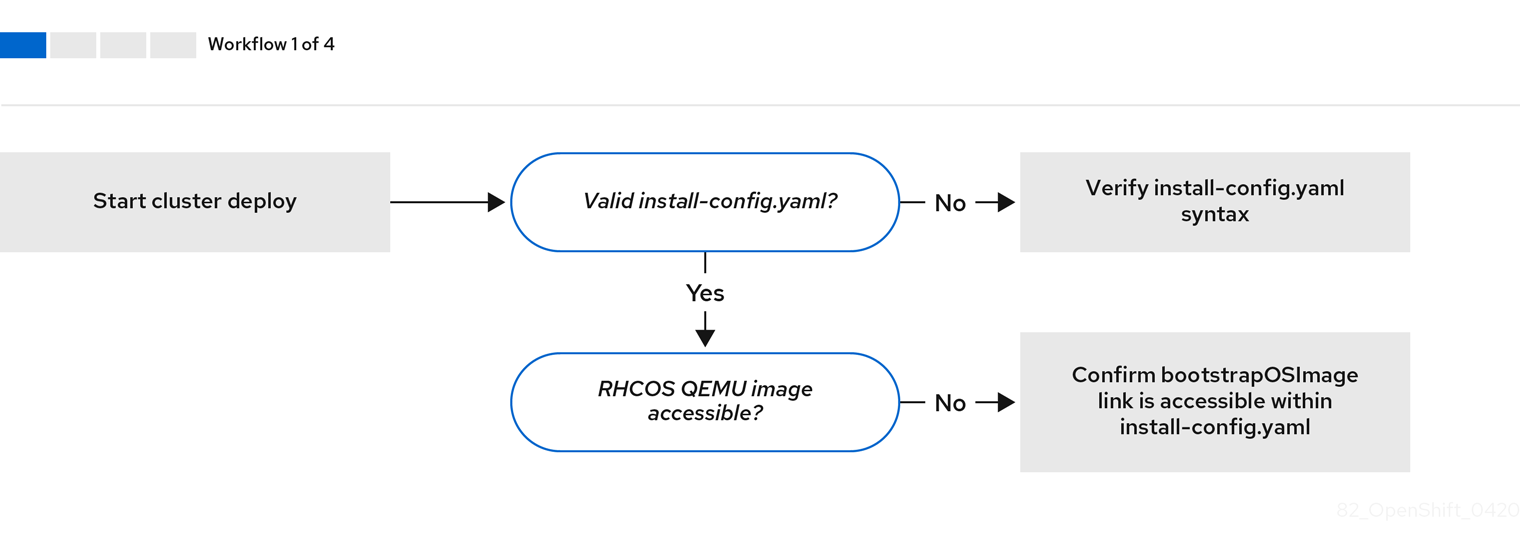
ワークフロー 1/4 は、install-config.yaml ファイルにエラーがある場合や Red Hat Enterprise Linux CoreOS (RHCOS) イメージにアクセスできない場合のトラブルシューティングのワークフローを説明しています。トラブルシューティングについての提案は、Troubleshooting install-config.yaml を参照してください。
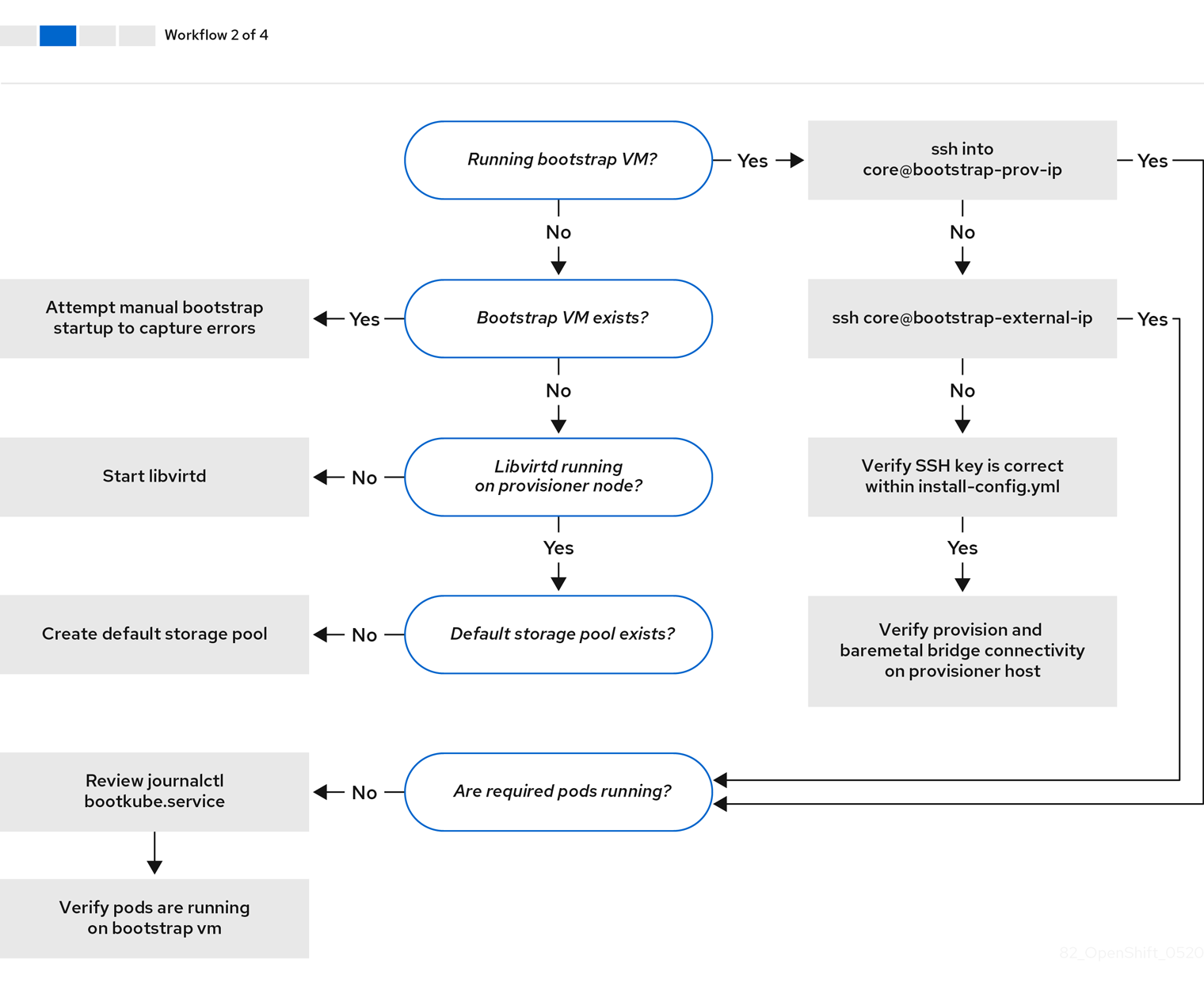
ワークフロー 2/4 は、ブートストラップ仮想マシンの問題、クラスターノードを起動できないブートストラップ仮想マシン、および ログの検査 についてのトラブルシューティングのワークフローを説明しています。provisioning ネットワークなしに OpenShift Container Platform クラスターをインストールする場合は、このワークフローは適用されません。
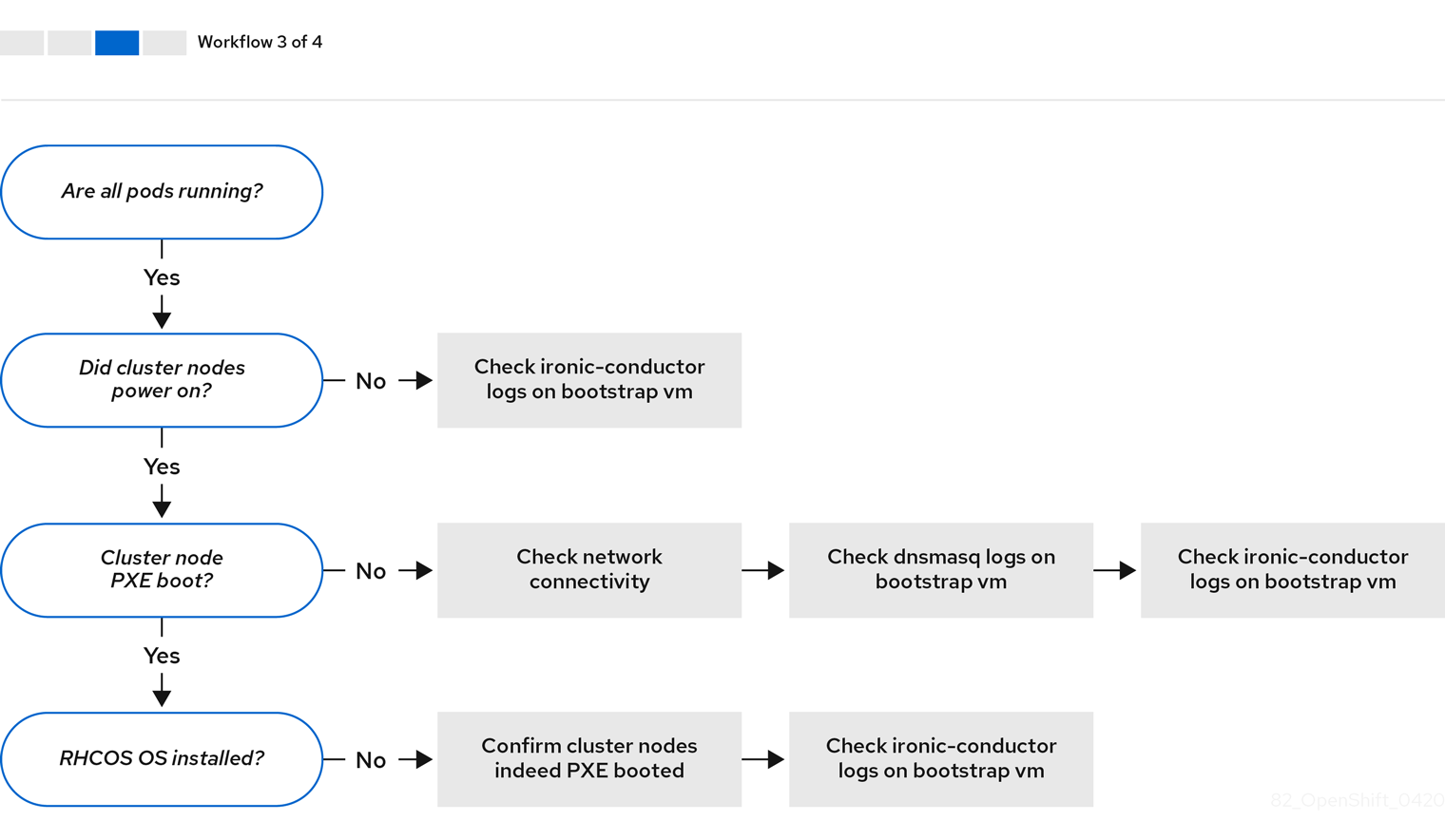
ワークフロー 3/4 は、PXE ブートしないクラスターノード のトラブルシューティングのワークフローを説明しています。RedFish 仮想メディアを使用してインストールする場合、各ノードは、インストーラーがノードをデプロイするために必要な最小ファームウェア要件を満たしている必要があります。詳細は、前提条件セクションの仮想メディアを使用したインストールのファームウェア要件を参照してください。
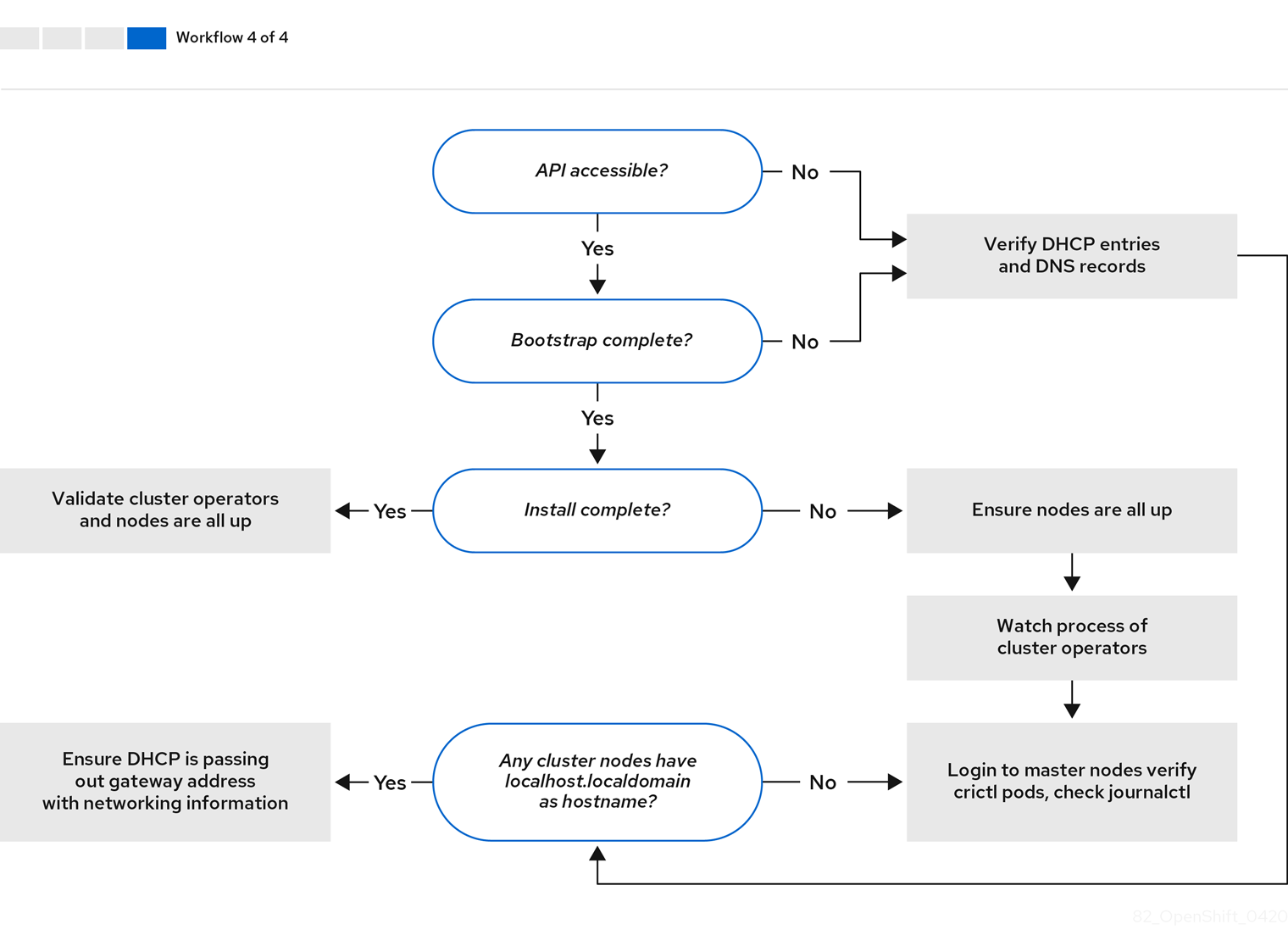
ワークフロー 4/4 は、アクセスできない API から 検証済みのインストール までのトラブルシューティングのワークフローを説明します。
8.5.2. install-config.yaml のトラブルシューティング
install-config.yaml 設定ファイルは、OpenShift Container Platform クラスターの一部であるすべてのノードを表します。このファイルには、apiVersion、baseDomain、imageContentSources、および仮想 IP アドレスのみで設定されるがこれらに制限されない必要なオプションが含まれます。OpenShift Container Platform クラスターのデプロイメントの初期段階でエラーが発生した場合、エラーは install-config.yaml 設定ファイルにある可能性があります。
手順
- YAML-tips のガイドラインを使用します。
- syntax-check を使用して YAML 構文が正しいことを確認します。
Red Hat Enterprise Linux CoreOS (RHCOS) QEMU イメージが適切に定義され、
install-config.yamlで提供される URL 経由でアクセスできることを確認します。以下に例を示します。$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.x86_64.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7出力が
200の場合、ブートストラップ仮想マシンイメージを保存する Web サーバーからの有効な応答があります。
8.5.3. ブートストラップ仮想マシンの問題
OpenShift Container Platform インストーラーは、OpenShift Container Platform クラスターノードのプロビジョニングを処理するブートストラップノードの仮想マシンを起動します。
手順
インストーラーをトリガー後の約 10 分から 15 分後に、
virshコマンドを使用してブートストラップ仮想マシンが機能していることを確認します。$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running注記ブートストラップ仮想マシンの名前は常にクラスター名で始まり、その後にランダムな文字セットが続き、bootstrap という単語で終わります。
ブートストラップ仮想マシンが 10 - 15 分後に実行されていない場合は、実行されない理由についてトラブルシューティングします。発生する可能性のある問題には以下が含まれます。
libvirtdがシステムで実行されていることを確認します。$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtdブートストラップ仮想マシンが動作している場合は、これにログインします。
virsh consoleコマンドを使用して、ブートストラップ仮想マシンの IP アドレスを見つけます。$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:重要provisioningネットワークなしで OpenShift Container Platform クラスターをデプロイする場合、172.22.0.2などのプライベート IP アドレスではなく、パブリック IP アドレスを使用する必要があります。IP アドレスを取得したら、
sshコマンドを使用してブートストラップ仮想マシンにログインします。注記直前の手順のコンソール出力では、
ens3で提供される IPv6 IP アドレスまたはens4で提供される IPv4 IP を使用できます。$ ssh core@172.22.0.2
ブートストラップ仮想マシンへのログインに成功しない場合は、以下いずれかのシナリオが発生した可能性があります。
-
172.22.0.0/24ネットワークにアクセスできない。プロビジョナーホスト、とくにprovisioningネットワークブリッジに関連するネットワークの接続を確認します。provisioningネットワークを使用していない場合は、この問題はありません。 -
パブリックネットワーク経由でブートストラップ仮想マシンにアクセスできない。
baremetalネットワークで SSH を試行する際に、provisionerホストの、とくにbaremetalネットワークブリッジについて接続を確認します。 -
Permission denied (publickey,password,keyboard-interactive)が出される。ブートストラップ仮想マシンへのアクセスを試行すると、Permission deniedエラーが発生する可能性があります。仮想マシンへのログインを試行するユーザーの SSH キーがinstall-config.yamlファイル内で設定されていることを確認します。
8.5.3.1. ブートストラップ仮想マシンがクラスターノードを起動できない
デプロイメント時に、ブートストラップ仮想マシンがクラスターノードの起動に失敗する可能性があり、これにより、仮想マシンがノードに RHCOS イメージをプロビジョニングできなくなります。このシナリオは、以下の原因で発生する可能性があります。
-
install-config.yamlファイルに関連する問題。 - ベアメタルネットワーク経由のアウトオブバンド (out-of-band) ネットワークアクセスに関する問題
この問題を確認するには、ironic に関連する 3 つのコンテナーを使用できます。
-
ironic-api -
ironic-conductor -
ironic-inspector
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2コンテナーログを確認するには、以下を実行します。
[core@localhost ~]$ sudo podman logs -f <container-name><container-name>を、ironic-api、ironic-conductor、またはironic-inspectorのいずれかに置き換えます。コントロールプレーンノードが PXE 経由で起動しない問題が発生した場合には、ironic-conductorPod を確認してください。ironic-conductorPod には、IPMI 経由でノードへのログインを試みるため、クラスターノードのブートの試行についての最も詳細な情報が含まれます。
考えられる理由
クラスターノードは、デプロイメントの開始時に ON 状態にある可能性があります。
解決策
IPMI でのインストールを開始する前に、OpenShift Container Platform クラスターノードの電源をオフにします。
$ ipmitool -I lanplus -U root -P <password> -H <out-of-band-ip> power off8.5.3.2. ログの検査
RHCOS イメージのダウンロードまたはアクセスに問題が発生した場合には、最初に install-config.yaml 設定ファイルで URL が正しいことを確認します。
RHCOS イメージをホストする内部 Web サーバーの例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.x86_64.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.x86_64.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
ipa-downloader および coreos-downloader コンテナーは、install-config.yaml 設定ファイルで指定されている Web サーバーまたは外部の quay.io レジストリーからリソースをダウンロードします。以下の 2 つのコンテナーが稼働していることを確認し、必要に応じてログを検査します。
-
ipa-downloader -
coreos-downloader
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2ブートストラップ仮想マシン内の
ipa-downloaderおよびcoreos-downloaderコンテナーのステータスを確認します。[core@localhost ~]$ sudo podman logs -f ipa-downloader[core@localhost ~]$ sudo podman logs -f coreos-downloaderブートストラップ仮想マシンがイメージへの URL にアクセスできない場合、
curlコマンドを使用して、仮想マシンがイメージにアクセスできることを確認します。すべてのコンテナーがデプロイメントフェーズで起動されているかどうかを示す
bootkubeログを検査するには、以下を実行します。[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.servicednsmasq、mariadb、httpd、およびironicを含むすべての Pod が実行中であることを確認します。[core@localhost ~]$ sudo podman psPod に問題がある場合には、問題のあるコンテナーのログを確認します。
ironic-apiのログを確認するには、以下を実行します。[core@localhost ~]$ sudo podman logs <ironic-api>
8.5.4. クラスターノードが PXE ブートしない
OpenShift Container Platform クラスターノードが PXE ブートしない場合、PXE ブートしないクラスターノードで以下のチェックを実行します。この手順は、provisioning ネットワークなしで OpenShift Container Platform クラスターをインストールする場合には適用されません。
手順
-
provisioningネットワークへのネットワークの接続を確認します。 -
PXE が
provisioningネットワークの NIC で有効にされており、PXE がその他のすべての NIC について無効にされていることを確認します。 install-config.yaml設定ファイルに、適切なハードウェアプロファイルとprovisioningネットワークに接続された NIC のブート MAC アドレスが含まれることを確認します。以下に例を示します。コントロールプレーンノードの設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: default #control plane node settingsワーカーノード設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC hardwareProfile: unknown #worker node settings
8.5.5. API にアクセスできない
クラスターが実行されており、クライアントが API にアクセスできない場合、ドメイン名の解決の問題により API へのアクセスが妨げられる可能性があります。
手順
Hostname Resolution: クラスターノードに
localhost.localdomainだけでなく、完全修飾ドメイン名があることを確認します。以下に例を示します。$ hostnameホスト名が設定されていない場合、正しいホスト名を設定します。以下に例を示します。
$ hostnamectl set-hostname <hostname>正しくない名前の解決: 各ノードに
digおよびnslookupを使用して DNS サーバーに正しい名前の解決があることを確認します。以下に例を示します。$ dig api.<cluster-name>.example.com; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el8 <<>> api.<cluster-name>.example.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37551 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 2 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: 866929d2f8e8563582af23f05ec44203d313e50948d43f60 (good) ;; QUESTION SECTION: ;api.<cluster-name>.example.com. IN A ;; ANSWER SECTION: api.<cluster-name>.example.com. 10800 IN A 10.19.13.86 ;; AUTHORITY SECTION: <cluster-name>.example.com. 10800 IN NS <cluster-name>.example.com. ;; ADDITIONAL SECTION: <cluster-name>.example.com. 10800 IN A 10.19.14.247 ;; Query time: 0 msec ;; SERVER: 10.19.14.247#53(10.19.14.247) ;; WHEN: Tue May 19 20:30:59 UTC 2020 ;; MSG SIZE rcvd: 140前述の例の出力は、
api.<cluster-name>.example.comVIP の適切な IP アドレスが10.19.13.86であることを示しています。この IP アドレスはbaremetal上にある必要があります。
8.5.6. 以前のインストールのクリーンアップ
以前のデプロイメントに失敗した場合、OpenShift Container Platform のデプロイを再試行する前に、失敗した試行からアーティファクトを削除します。
手順
OpenShift Container Platform クラスターをインストールする前に、すべてのベアメタルノードの電源をオフにします。
$ ipmitool -I lanplus -U <user> -P <password> -H <management-server-ip> power off以前に試行したデプロイメントにより古いブートストラップリソースが残っている場合は、これらをすべて削除します。
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done以下を
clusterconfigsディレクトリーから削除し、Terraform が失敗することを防ぎます。$ rm -rf ~/clusterconfigs/auth ~/clusterconfigs/terraform* ~/clusterconfigs/tls ~/clusterconfigs/metadata.json
8.5.7. レジストリーの作成に関する問題
非接続レジストリーの作成時に、レジストリーのミラーリングを試行する際に User Not Authorized エラーが発生する場合があります。このエラーは、新規の認証を既存の pull-secret.txt ファイルに追加できない場合に生じる可能性があります。
手順
認証が正常に行われていることを確認します。
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO注記インストールイメージのミラーリングに使用される変数の出力例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'RELEASE_IMAGEおよびVERSIONの値は、OpenShift インストールの環境のセットアップセクションの OpenShift Installer の取得 の手順で設定されています。レジストリーのミラーリング後に、非接続環境でこれにアクセスできることを確認します。
$ curl -k -u <user>:<password> https://registry.example.com:<registry-port>/v2/_catalog {"repositories":["<Repo-Name>"]}
8.5.8. その他の問題点
8.5.8.1. runtime network not ready エラーへの対応
クラスターのデプロイメント後に、以下のエラーが発生する可能性があります。
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator は、インストーラーによって作成される特別なオブジェクトに対応してネットワークコンポーネントをデプロイします。これは、コントロールプレーン (マスター) ノードが起動した後、ブートストラップコントロールプレーンが停止する前にインストールプロセスの初期段階で実行されます。これは、コントロールプレーン (マスター) ノードの起動の長い遅延や apiserver 通信の問題などの、より判別しづらいインストーラーの問題を示すことができます。
手順
openshift-network-operatornamespace の Pod を検査します。$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149mprovisionerノードで、ネットワーク設定が存在することを判別します。$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OpenShiftSDN存在しない場合には、インストーラーはこれを作成していません。インストーラーがこれを作成しなかった理由を判別するには、以下のコマンドを実行します。
$ openshift-install create manifestsnetwork-operatorが実行されていることを確認します。$ kubectl -n openshift-network-operator get podsログを取得します。
$ kubectl -n openshift-network-operator logs -l "name=network-operator"3 つ以上のコントロールプレーン (マスター) ノードを持つ高可用性クラスターの場合、Operator はリーダーの選択を実行し、他の Operator はすべてスリープ状態になります。詳細は、Troubleshooting を参照してください。
8.5.8.2. クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない
クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない場合は、以下の点を確認してください。
- 予約された IPv6 アドレスが DHCP 範囲外にあることを確認します。
DHCP サーバーの IP アドレス予約では、予約で正しい DUID (DHCP 固有識別子) が指定されていることを確認します。以下に例を示します。
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- Route Announcement が機能していることを確認します。
- DHCP サーバーが、IP アドレス範囲を提供する必要なインターフェイスでリッスンしていることを確認します。
8.5.8.3. クラスターノードが DHCP 経由で正しいホスト名を取得しない
IPv6 のデプロイメント時に、クラスターノードは DHCP でホスト名を取得する必要があります。NetworkManager はホスト名をすぐに割り当てない場合があります。コントロールプレーン (マスター) ノードは、以下のようなエラーを報告する可能性があります。
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
このエラーは、最初に DHCP サーバーからホスト名を受信せずにクラスターノードが起動する可能性があることを示しています。これにより、kubelet が localhost.localdomain ホスト名で起動します。エラーに対処するには、ノードによるホスト名の更新を強制します。
手順
hostnameを取得します。[core@master-X ~]$ hostnameホスト名が
localhostの場合は、以下の手順に進みます。注記Xは、コントロールプレーンノード (別名マスターノード) 番号になります。クラスターノードによる DHCP リースの更新を強制します。
[core@master-X ~]$ sudo nmcli con up "<bare-metal-nic>"<bare-metal-nic>を、baremetalネットワークに対応する有線接続に置き換えます。hostnameを再度確認します。[core@master-X ~]$ hostnameホスト名が
localhost.localdomainの場合は、NetworkManagerを再起動します。[core@master-X ~]$ sudo systemctl restart NetworkManager-
ホスト名がまだ
localhost.localdomainの場合は、数分待機してから再度確認します。ホスト名がlocalhost.localdomainのままの場合は、直前の手順を繰り返します。 nodeip-configurationサービスを再起動します。[core@master-X ~]$ sudo systemctl restart nodeip-configuration.serviceこのサービスは、正しいホスト名の参照で
kubeletサービスを再設定します。kubelet が直前の手順で変更された後にユニットファイル定義を再読み込みします。
[core@master-X ~]$ sudo systemctl daemon-reloadkubeletサービスを再起動します。[core@master-X ~]$ sudo systemctl restart kubelet.servicekubeletが正しいホスト名で起動されていることを確認します。[core@master-X ~]$ sudo journalctl -fu kubelet.service
再起動時など、クラスターの稼働後にクラスターノードが正しいホスト名を取得しない場合、クラスターの csr は保留中になります。csr は承認 しません。承認すると、他の問題が生じる可能性があります。
csr の対応
クラスターで CSR を取得します。
$ oc get csr保留中の
csrにSubject Name: localhost.localdomainが含まれているかどうかを確認します。$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -textSubject Name: localhost.localdomainが含まれるcsrを削除します。$ oc delete csr <wrong_csr>
8.5.8.4. ルートがエンドポイントに到達しない
インストールプロセス時に、VRRP (Virtual Router Redundancy Protocol) の競合が発生する可能性があります。この競合は、特定のクラスター名を使用してクラスターデプロイメントの一部であった、以前に使用された OpenShift Container Platform ノードが依然として実行中であるものの、同じクラスター名を使用した現在の OpenShift Container Platform クラスターデプロイメントの一部ではない場合に発生する可能性があります。たとえば、クラスターはクラスター名 openshift を使用してデプロイされ、3 つのコントロールプレーン (マスター) ノードと 3 つのワーカーノードをデプロイします。後に、別のインストールで同じクラスター名 openshift が使用されますが、この再デプロイメントは 3 つのコントロールプレーン (マスター) ノードのみをインストールし、以前のデプロイメントの 3 つのワーカーノードを ON 状態のままにします。これにより、VRID (Virtual Router Identifier) の競合が発生し、VRRP が競合する可能性があります。
ルートを取得します。
$ oc get route oauth-openshiftサービスエンドポイントを確認します。
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59mコントロールプレーン (マスター) ノードからサービスへのアクセスを試行します。
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403provisionerノードからのauthentication-operatorエラーを特定します。$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
解決策
- すべてのデプロイメントのクラスター名が一意であり、競合が発生しないことを確認します。
- 同じクラスター名を使用するクラスターデプロイメントの一部ではない不正なノードをすべてオフにします。そうしないと、OpenShift Container Platform クラスターの認証 Pod が正常に起動されなくなる可能性があります。
8.5.8.5. 初回起動時の Ignition の失敗
初回起動時に、Ignition 設定が失敗する可能性があります。
手順
Ignition 設定が失敗したノードに接続します。
Failed Units: 1 machine-config-daemon-firstboot.servicemachine-config-daemon-firstbootサービスを再起動します。[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
8.5.8.6. NTP が同期しない
OpenShift Container Platform クラスターのデプロイメントは、クラスターノード間の NTP の同期クロックによって異なります。同期クロックがない場合、時間の差が 2 秒を超えるとクロックのドリフトによりデプロイメントが失敗する可能性があります。
手順
クラスターノードの
AGEの差異の有無を確認します。以下に例を示します。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.16.2 master-1.cloud.example.com Ready master 135m v1.16.2 master-2.cloud.example.com Ready master 145m v1.16.2 worker-2.cloud.example.com Ready worker 100m v1.16.2クロックのドリフトによる一貫性のないタイミングの遅延について確認します。以下に例を示します。
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out-of-band-ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
既存のクラスターでのクロックドリフトへの対応
chrony.confファイルを作成し、これをbase64文字列としてエンコードします。以下に例を示します。$ cat << EOF | base 64 server <NTP-server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony EOF- 1
<NTP-server>を NTP サーバーの IP アドレスに置き換えます。出力をコピーします。
[text-in-base-64]MachineConfigオブジェクトを作成します。base64文字列を直前の手順の出力で生成される[text-in-base-64]文字列に置き換えます。以下の例では、ファイルをコントロールプレーン (マスター) ノードに追加します。ワーカーノードのファイルを変更するか、またはワーカーロールの追加のマシン設定を作成できます。$ cat << EOF > ./99_masters-chrony-configuration.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: creationTimestamp: null labels: machineconfiguration.openshift.io/role: master name: 99-master-etc-chrony-conf spec: config: ignition: config: {} security: tls: {} timeouts: {} version: 3.1.0 networkd: {} passwd: {} storage: files: - contents: source: data:text/plain;charset=utf-8;base64,[text-in-base-64]1 group: name: root mode: 420 overwrite: true path: /etc/chrony.conf user: name: root osImageURL: ""- 1
[text-in-base-64]を base64 文字列に置き換えます。
設定ファイルのバックアップコピーを作成します。以下に例を示します。
$ cp 99_masters-chrony-configuration.yaml 99_masters-chrony-configuration.yaml.backup設定ファイルを適用します。
$ oc apply -f ./masters-chrony-configuration.yamlSystem clock synchronizedの値が yes であることを確認します。$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: noデプロイメントの前にクロック同期を設定するには、マニフェストファイルを生成し、このファイルを
openshiftディレクトリーに追加します。以下に例を示します。$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yamlクラスターの作成を継続します。
8.5.9. インストールの確認
インストール後に、インストーラーがノードおよび Pod を正常にデプロイしていることを確認します。
手順
OpenShift Container Platform クラスターノードが適切にインストールされると、以下の
Ready状態がSTATUS列に表示されます。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.16.2 master-1.example.com Ready master,worker 4h v1.16.2 master-2.example.com Ready master,worker 4h v1.16.2インストーラーによりすべての Pod が正常にデプロイされたことを確認します。以下のコマンドは、実行中の Pod、または出力の一部として完了した Pod を削除します。
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete