9.5. AWS でホストされたクラスターの障害復旧
ホステッドクラスターを Amazon Web Services (AWS) 内の同じリージョンに復元できます。たとえば、管理クラスターのアップグレードが失敗し、ホストされたクラスターが読み取り専用状態になっている場合は、障害復旧が必要になります。
Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
障害復旧プロセスには次の手順が含まれます。
- ソース管理クラスターでのホステッドクラスターのバックアップ
- 宛先管理クラスターでのホステッドクラスターの復元
- ホステッドクラスターのソース管理クラスターからの削除
プロセス中、ワークロードは引き続き実行されます。クラスター API は一定期間使用できない場合がありますが、ワーカーノードで実行されているサービスには影響しません。
API サーバー URL を維持するには、ソース管理クラスターと宛先管理クラスターの両方に --external-dns フラグが必要です。これにより、サーバー URL は https://api-sample-hosted.sample-hosted.aws.openshift.com で終わります。以下の例を参照してください。
例: 外部 DNS フラグ
--external-dns-provider=aws \
--external-dns-credentials=<path_to_aws_credentials_file> \
--external-dns-domain-filter=<basedomain>
API サーバー URL を維持するために --external-dns フラグを含めない場合、ホステッドクラスターを移行することはできません。
9.5.1. バックアップおよび復元プロセスの概要
バックアップと復元のプロセスは、以下のような仕組みとなっています。
管理クラスター 1 (ソース管理クラスターと見なすことができます) では、コントロールプレーンとワーカーが外部 DNS API を使用して対話します。外部 DNS API はアクセス可能で、管理クラスター間にロードバランサーが配置されています。

ホステッドクラスターのスナップショットを作成します。これには、etcd、コントロールプレーン、およびワーカーノードが含まれます。このプロセスの間、ワーカーノードは外部 DNS API にアクセスできなくても引き続きアクセスを試みます。また、ワークロードが実行され、コントロールプレーンがローカルマニフェストファイルに保存され、etcd が S3 バケットにバックアップされます。データプレーンはアクティブで、コントロールプレーンは一時停止しています。
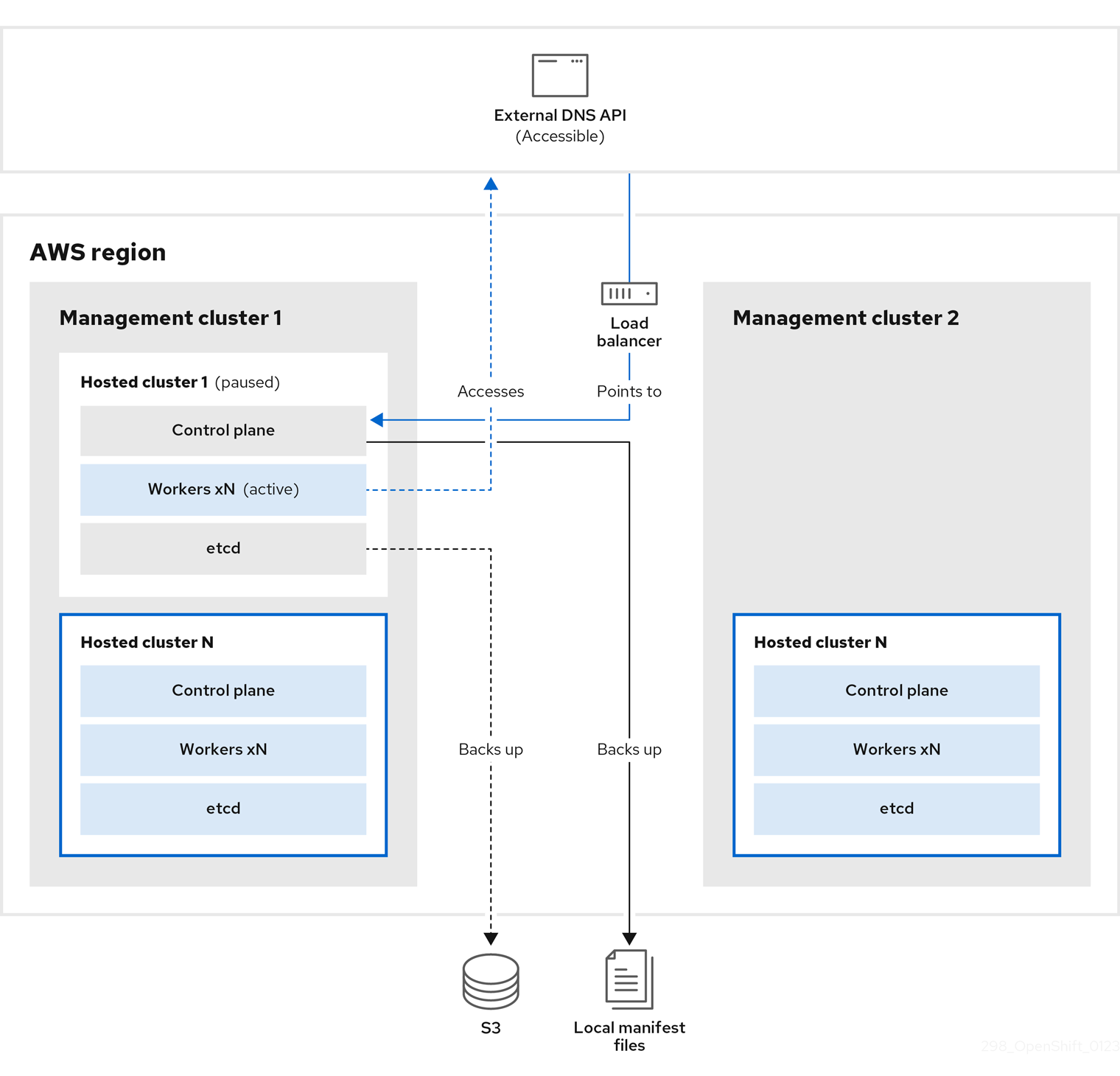
管理クラスター 2 (宛先管理クラスターと見なすことができます) では、S3 バケットから etcd を復元し、ローカルマニフェストファイルからコントロールプレーンを復元します。このプロセスの間、外部 DNS API は停止し、ホステッドクラスター API にアクセスできなくなり、API を使用するワーカーはマニフェストファイルを更新できなくなりますが、ワークロードは引き続き実行されます。

外部 DNS API に再びアクセスできるようになり、ワーカーノードはそれを使用して管理クラスター 2 に移動します。外部 DNS API は、コントロールプレーンを参照するロードバランサーにアクセスできます。

管理クラスター 2 では、コントロールプレーンとワーカーノードが外部 DNS API を使用して対話します。リソースは、etcd の S3 バックアップを除いて、管理クラスター 1 から削除されます。ホステッドクラスターを管理クラスター 1 で再度設定しようとしても、機能しません。

9.5.2. ホストされたクラスターのバックアップ
ターゲット管理クラスターでホストされたクラスターを復元するには、最初にすべての関連データをバックアップする必要があります。
手順
以下のコマンドを入力して、configmap ファイルを作成し、ソース管理クラスターを宣言します。
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}以下のコマンドを入力して、ホストされたクラスターとノードプールの調整をシャットダウンします。
$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator$ PAUSED_UNTIL="true" $ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge $ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator以下の bash スクリプトを実行して、etcd をバックアップし、データを S3 バケットにアップロードします。
ヒントこのスクリプトを関数でラップし、メイン関数から呼び出します。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd のバックアップの詳細は、「ホステッドクラスターでの etcd のバックアップと復元」を参照してください。
以下のコマンドを入力して、Kubernetes および OpenShift Container Platform オブジェクトをバックアップします。次のオブジェクトをバックアップする必要があります。
-
HostedCluster namespace の
HostedClusterおよびNodePoolオブジェクト -
HostedCluster namespace の
HostedClusterシークレット -
Hosted Control Plane namespace の
HostedControlPlane -
Hosted Control Plane namespace の
Cluster -
Hosted Control Plane namespace の
AWSCluster、AWSMachineTemplate、およびAWSMachine -
Hosted Control Plane namespace の
MachineDeployments、MachineSets、およびMachines Hosted Control Plane namespace の
ControlPlaneシークレット$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $ chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster $ echo "Backing Up HostedCluster Objects:" $ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml $ echo "--> HostedCluster" $ sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool $ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml $ echo "--> NodePool" $ sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace $ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace $ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane $ echo "--> HostedControlPlane:" $ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster $ echo "--> Cluster:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) $ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster $ echo "--> AWS Cluster:" $ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate $ echo "--> AWS Machine Template:" $ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines $ echo "--> AWS Machine:" $ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments $ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets $ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines $ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster namespace の
次のコマンドを入力して、
ControlPlaneルートをクリーンアップします。$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --allこのコマンドを入力すると、ExternalDNS Operator が Route53 エントリーを削除できるようになります。
次のスクリプトを実行して、Route53 エントリーがクリーンであることを確認します。
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
検証
すべての OpenShift Container Platform オブジェクトと S3 バケットをチェックし、すべてが想定どおりであることを確認します。
次のステップ
ホステッドクラスターを復元します。
9.5.3. ホステッドクラスターの復元
バックアップしたすべてのオブジェクトを収集し、宛先管理クラスターに復元します。
前提条件
ソース管理クラスターからデータをバックアップしている。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT2_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT2_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、新しい管理クラスターに、復元するクラスターの namespace が含まれていないことを確認します。
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup宛先管理クラスターでの namespace の削除
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true以下のコマンドを入力して、削除された namespace を再作成します。
namespace 作成コマンド
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}次のコマンドを入力して、HC namespace のシークレットを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*以下のコマンドを入力して、
HostedClusterコントロールプレーン namespace のオブジェクトを復元します。シークレットコマンドを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*クラスター復元コマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*ノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力して、HC コントロールプレーン namespace のオブジェクトを復元します。
AWS のコマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*マシンのコマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*次の bash スクリプトを実行して、etcd データとホステッドクラスターを復元します。
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fiノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力してノードプールを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
検証
ノードが完全に復元されたことを確認するには、次の関数を使用します。
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
次のステップ
クラスターをシャットダウンして削除します。
9.5.4. ホステッドクラスターのソース管理クラスターからの削除
ホステッドクラスターをバックアップして宛先管理クラスターに復元した後、ソース管理クラスターのホステッドクラスターをシャットダウンして削除します。
前提条件
データをバックアップし、ソース管理クラスターに復元している。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、
deploymentおよびstatefulsetオブジェクトをスケーリングします。重要spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値がDeleteに設定されている場合は、データの損失につながる可能性があるため、ステートフルセットをスケーリングしないでください。回避策として、
spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値をRetainに更新します。ステートフルセットをリコンサイルし、値をDeleteに戻してしまうようなコントローラーが存在しないことを確認してください。そのようなコントローラーがあると、データの損失が発生する可能性があります。$ export KUBECONFIG=${MGMT_KUBECONFIG}デプロイメントコマンドのスケールダウン
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15次のコマンドを入力して、
NodePoolオブジェクトを削除します。NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi次のコマンドを入力して、
machineおよびmachinesetオブジェクトを削除します。# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true次のコマンドを入力して、クラスターオブジェクトを削除します。
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all次のコマンドを入力して、AWS マシン (Kubernetes オブジェクト) を削除します。実際の AWS マシンの削除を心配する必要はありません。クラウドインスタンスへの影響はありません。
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done次のコマンドを入力して、
HostedControlPlaneおよびControlPlaneHC namespace オブジェクトを削除します。HCP および ControlPlane HC NS コマンドの削除
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true次のコマンドを入力して、
HostedClusterおよび HC namespace オブジェクトを削除します。HC および HC Namespace コマンドの削除
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
検証
すべてが機能することを確認するには、次のコマンドを入力します。
検証コマンド
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 内でのコマンド
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
次のステップ
ホステッドクラスター内の OVN Pod を削除して、新しい管理クラスターで実行される新しい OVN コントロールプレーンに接続できるようにします。
-
ホステッドクラスターの kubeconfig パスを使用して
KUBECONFIG環境変数を読み込みます。 以下のコマンドを入力します。
$ oc delete pod -n openshift-ovn-kubernetes --all