1.2. モニタリングスタックアーキテクチャー
OpenShift Container Platform モニタリングスタックは、Prometheus オープンソースプロジェクトおよびその幅広いエコシステムをベースとしています。ここでは、モニタリングスタックアーキテクチャーを説明します。これには、デフォルトのモニタリングコンポーネントおよびユーザー定義プロジェクトのモニタリング用のコンポーネントが含まれます。
1.2.1. モニタリングスタックについて
モニタリングスタックには、以下のコンポーネントが含まれます。
- デフォルトのプラットフォームモニタリングコンポーネント
プラットフォームモニタリングコンポーネントのセットは、OpenShift Container Platform のインストール時にデフォルトで
openshift-monitoringプロジェクトにインストールされます。これにより、Kubernetes サービスを含むコアクラスターコンポーネントのモニタリングが可能になります。デフォルトのモニタリングスタックは、クラスターのリモートのヘルスモニタリングも有効にします。これらのコンポーネントは、以下の図の Installed by default セクションに表示されます。
- ユーザー定義プロジェクトをモニターするためのコンポーネント
ユーザー定義プロジェクトのモニタリングを有効にすると、追加のモニタリングコンポーネントは
openshift-user-workload-monitoringプロジェクトにインストールされます。これにより、ユーザー定義プロジェクトのオプションのモニタリング機能が提供されます。これらのコンポーネントは、以下の図の User セクションに表示されます。
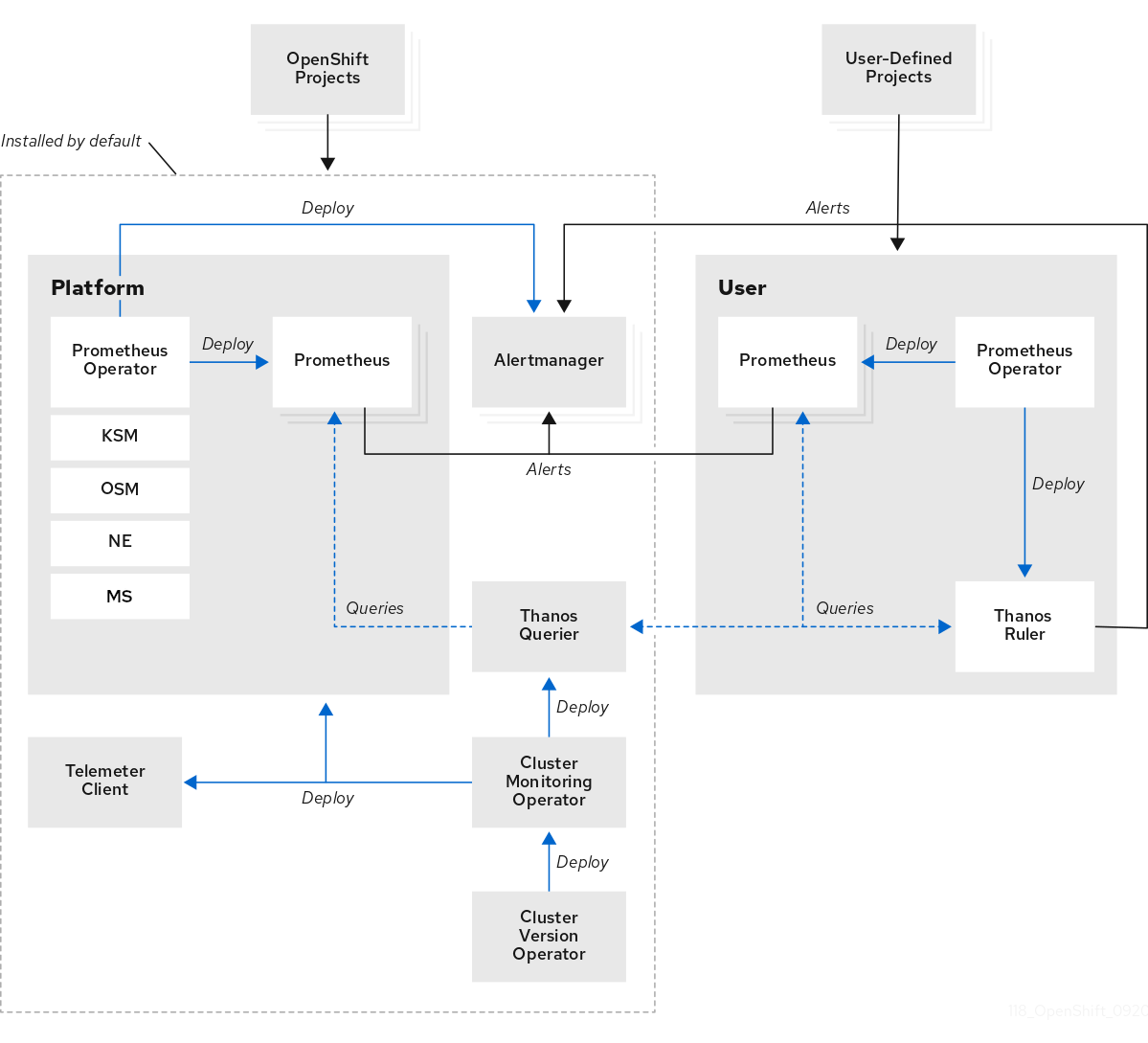
1.2.2. デフォルトのモニタリングコンポーネント
デフォルトで、OpenShift Container Platform 4.19 モニタリングスタックには以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Cluster Monitoring Operator | Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Prometheus および Alertmanager インスタンス、Thanos Querier、Telemeter Client、およびメトリクスターゲットをデプロイ、管理、および自動更新します。CMO は Cluster Version Operator (CVO) によってデプロイされます。 |
| Prometheus Operator |
|
| Prometheus | OpenShift Container Platform モニタリングスタックは、Prometheus モニタリングシステムをベースにしています。Prometheus は時系列データベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Metrics Server |
Metrics Server コンポーネント (上図の MS) はリソースメトリクスを収集し、他のツールや API で使用できるように |
| Alertmanager | Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。 |
| kube-state-metrics エージェント | kube-state-metrics エクスポーターエージェント (上記の図の KSM) は、Kubernetes オブジェクトを Prometheus が使用できるメトリクスに変換します。 |
| monitoring-plugin | monitoring-plugin 動的プラグインコンポーネントは、OpenShift Container Platform Web コンソールの Observe セクションにモニタリングページをデプロイします。Cluster Monitoring Operator config map 設定を使用すると、Web コンソールページの monitoring-plugin リソースを管理できます。 |
| openshift-state-metrics エージェント | openshift-state-metrics エクスポーター (上記の図の OSM) は、OpenShift Container Platform 固有のリソースのメトリクスを追加して、kube-state-metrics を拡張します。 |
| node-exporter エージェント | ノードエクスポーターエージェント (上記の図の NE) は、クラスター内のすべてのノードに関するメトリクスを収集します。node-exporter エージェントはすべてのノードにデプロイされます。 |
| Thanos Querier | Thanos Querier は、単一のマルチテナントインターフェイスで、OpenShift Container Platform のコアメトリクスおよびユーザー定義プロジェクトのメトリクスを集約し、オプションでこれらの重複を排除します。 |
| Telemeter クライアント | Telemeter Client は、プラットフォームの Prometheus インスタンスから Red Hat にデータのサブセクションを送信し、クラスターのリモートヘルスモニタリングを有効にします。 |
モニタリングスタックは、スタック内のすべてのコンポーネントを監視します。このコンポーネントは、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.2.1. デフォルトのモニタリングターゲット
スタック自体のコンポーネントに加えて、デフォルトのモニタリングスタックは追加のプラットフォームコンポーネントを監視します。
以下は、モニタリングターゲットの例です。
- CoreDNS
- etcd
- HAProxy
- イメージレジストリー
- Kubelets
- Kubernetes API サーバー
- Kubernetes コントローラーマネージャー
- Kubernetes スケジューラー
- OpenShift API サーバー
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
- ターゲットの正確なリストは、クラスターの機能とインストールされているコンポーネントによって異なる場合があります。
- 各 OpenShift Container Platform コンポーネントはそれぞれのモニタリング設定を行います。OpenShift Container Platform コンポーネントのモニタリングに関する問題は、Jira 問題 で一般的なモニタリングコンポーネントについてではなく、特定のコンポーネントに対してバグを報告してください。
他の OpenShift Container Platform フレームワークのコンポーネントもメトリクスを公開する場合があります。詳細は、それぞれのドキュメントを参照してください。
1.2.3. ユーザー定義プロジェクトをモニターするためのコンポーネント
OpenShift Container Platform には、ユーザー定義プロジェクトでサービスおよび Pod を監視する際に役立つモニタリングスタックのオプションの機能拡張が含まれています。この機能には、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus は、ユーザー定義プロジェクトのモニタリングを提供するモニタリングシステムです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Thanos Ruler | Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。 |
| Alertmanager | Alertmanager サービスは、Prometheus および Thanos Ruler から送信されるアラートを処理します。Alertmanager はユーザー定義のアラートを外部通知システムに送信します。このサービスのデプロイは任意です。 |
上記の表のコンポーネントは、ユーザー定義プロジェクトのモニタリングを有効にした後にデプロイされます。
モニタリングスタックは、ユーザー定義プロジェクトのすべてのコンポーネントを監視します。このコンポーネントは、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.3.1. ユーザー定義プロジェクトのターゲットのモニタリング
ユーザー定義プロジェクトのモニタリングを有効にすると、以下を監視できます。
- ユーザー定義プロジェクトのサービスエンドポイント経由で提供されるメトリクス。
- ユーザー定義プロジェクトで実行される Pod。
1.2.4. 高可用性クラスターでのモニタリングスタック
マルチノードクラスターでは、データの損失やサービスの停止を防ぐために、次のコンポーネントがデフォルトで高可用性 (HA) モードで実行されます。
- Prometheus
- Alertmanager
- Thanos Ruler
- Thanos Querier
- Metrics Server
- モニタリングプラグイン
コンポーネントは 2 つの Pod にレプリケートされ、それぞれが別のノードで実行されます。そのため、モニタリングスタックは 1 つの Pod の損失に耐えることができます。
- HA モードの Prometheus
- 両方のレプリカが独立して同じターゲットをスクレイピングし、同じルールを評価します。
- レプリカは相互に通信しません。したがって、Pod 間でデータが異なる場合があります。
- HA モードの Alertmanager
- 2 つのレプリカが通知とサイレンス状態を相互に同期します。これにより、各通知が少なくとも 1 回は送信されます。
- レプリカが通信に失敗した場合、または受信側に問題がある場合、通知は送信されますが、重複する可能性があります。
Prometheus、Alertmanager、Thanos Ruler はステートフルコンポーネントです。高可用性を実現するには、これらのコンポーネントを永続ストレージを使用して設定する必要があります。
1.2.5. モニタリングスタックにおける TLS セキュリティーとローテーション
通信をセキュアに保つために、OpenShift Container Platform モニタリングスタックで TLS プロファイルと証明書のローテーションがどのように機能するか説明します。
- 監視コンポーネントの TLS セキュリティープロファイル
-
モニタリングスタックのすべてのコンポーネントは、クラスター管理者が一元的に設定する TLS セキュリティープロファイル設定を使用します。モニタリングスタックコンポーネントは、グローバル OpenShift Container Platform
apiservers.config.openshift.io/clusterリソースのtlsSecurityProfileフィールドにすでに存在する TLS セキュリティープロファイル設定を使用します。 - TLS 証明書のローテーションと自動再起動
Cluster Monitoring Operator は、モニタリングコンポーネントの内部 TLS 証明書のライフサイクルを管理します。これらの証明書は、モニタリングコンポーネント間の内部通信を保護します。
証明書のローテーション中に、CMO はシークレットと config map を更新し、影響を受ける Pod の自動再起動をトリガーします。これは想定された動作であり、Pod は自動的に回復します。
次の例は、証明書のローテーション中に発生するイベントを示しています。
$ oc get events -n openshift-monitoring LAST SEEN TYPE REASON OBJECT MESSAGE 2h39m Normal SecretUpdated deployment/cluster-monitoring-operator Updated Secret/grpc-tls -n openshift-monitoring because it changed 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/prometheus-user-workload-grpc-tls -n openshift-user-workload-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/thanos-querier-grpc-tls -n openshift-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/thanos-ruler-grpc-tls -n openshift-user-workload-monitoring because it was missing 2h39m Normal SecretCreated deployment/cluster-monitoring-operator Created Secret/prometheus-k8s-grpc-tls -n openshift-monitoring because it was missing 2h38m Warning FailedMount pod/prometheus-k8s-0 MountVolume.SetUp failed for volume "secret-grpc-tls" : secret "prometheus-k8s-grpc-tls" not found 2h39m Normal Created pod/prometheus-k8s-0 Created container kube-rbac-proxy-thanos 2h39m Normal Started pod/prometheus-k8s-0 Started container kube-rbac-proxy-thanos 2h39m Normal SuccessfulDelete statefulset/prometheus-k8s delete Pod prometheus-k8s-0 in StatefulSet prometheus-k8s successful 2h39m Normal SuccessfulCreate statefulset/prometheus-k8s create Pod prometheus-k8s-0 in StatefulSet prometheus-k8s successful
1.2.6. OpenShift Container Platform モニタリングの一般用語集
この用語集では、OpenShift Container Platform アーキテクチャーで使用される一般的な用語を定義します。
- Alertmanager
- Alertmanager は、Prometheus から受信したアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
- アラートルール
- アラートルールには、クラスター内の特定の状態を示す一連の条件が含まれます。アラートは、これらの条件が true の場合にトリガーされます。アラートルールには、アラートのルーティング方法を定義する重大度を割り当てることができます。
- Cluster Monitoring Operator
- Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Thanos Querier、Telemeter Client、メトリクスターゲットなどの Prometheus インスタンスをデプロイおよび管理して、それらが最新であることを確認します。CMO は Cluster Version Operator (CVO) によってデプロイされます。
- Cluster Version Operator
- Cluster Version Operator (CVO) は Cluster Operator のライフサイクルを管理し、その多くはデフォルトで OpenShift Container Platform にインストールされます。
- config map
-
config map は、設定データを Pod に注入する方法を提供します。タイプ
ConfigMapのボリューム内の config map に格納されたデータを参照できます。Pod で実行しているアプリケーションは、このデータを使用できます。 - コンテナー
- コンテナーは、ソフトウェアとそのすべての依存関係を含む軽量で実行可能なイメージです。コンテナーは、オペレーティングシステムを仮想化します。そのため、コンテナーはデータセンターからパブリッククラウド、プライベートクラウド、開発者のラップトップなどまで、場所を問わずコンテナーを実行できます。
- カスタムリソース (CR)
- CR は Kubernetes API のエクステンションです。カスタムリソースを作成できます。
- etcd
- etcd は OpenShift Container Platform のキーと値のストアであり、すべてのリソースオブジェクトの状態を保存します。
- Fluentd
Fluentd は、各 OpenShift Container Platform ノードに常駐するログコレクターです。アプリケーション、インフラストラクチャー、および監査ログを収集し、それらをさまざまな出力に転送します。
注記Fluentd は非推奨となっており、今後のリリースで削除される予定です。Red Hat は、現在のリリースのライフサイクル中にこの機能のバグ修正とサポートを提供しますが、この機能は拡張されなくなりました。Fluentd の代わりに、Vector を使用できます。
- Kubelets
- ノード上で実行され、コンテナーマニフェストを読み取ります。定義されたコンテナーが開始され、実行されていることを確認します。
- Kubernetes API サーバー
- Kubernetes API サーバーは、API オブジェクトのデータを検証して設定します。
- Kubernetes コントローラーマネージャー
- Kubernetes コントローラーマネージャーは、クラスターの状態を管理します。
- Kubernetes スケジューラー
- Kubernetes スケジューラーは Pod をノードに割り当てます。
- ラベル
- ラベルは、Pod などのオブジェクトのサブセットを整理および選択するために使用できるキーと値のペアです。
- Metrics Server
-
Metrics Server モニタリングコンポーネントはリソースメトリクスを収集し、他のツールや API で使用できるように
metrics.k8s.ioMetrics API サービスで公開します。これにより、コアプラットフォームの Prometheus スタックによるこの機能の処理が不要になります。 - node
- OpenShift Container Platform クラスター内のコンピュートマシン。ノードは、仮想マシン (VM) または物理マシンのいずれかです。
- Operator
- OpenShift Container Platform クラスターで Kubernetes アプリケーションをパッケージ化、デプロイ、および管理するための推奨される方法。Operator は、人間による操作に関する知識を取り入れて、簡単にパッケージ化してお客様と共有できるソフトウェアにエンコードします。
- Operator Lifecycle Manager (OLM)
- OLM は、Kubernetes ネイティブアプリケーションのライフサイクルをインストール、更新、および管理するのに役立ちます。OLM は、Operator を効果的かつ自動化されたスケーラブルな方法で管理するために設計されたオープンソースのツールキットです。
- 永続ストレージ
- デバイスがシャットダウンされた後でもデータを保存します。Kubernetes は永続ボリュームを使用して、アプリケーションデータを保存します。
- 永続ボリューム要求 (PVC)
- PVC を使用して、PersistentVolume を Pod にマウントできます。クラウド環境の詳細を知らなくてもストレージにアクセスできます。
- Pod
- Pod は、Kubernetes における最小の論理単位です。Pod は、ワーカーノードで実行される 1 つ以上のコンテナーで構成されます。
- Prometheus
- Prometheus は、OpenShift Container Platform モニタリングスタックのベースとなるモニタリングシステムです。Prometheus は時系列データベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Prometheus Operator
-
openshift-monitoringプロジェクトの Prometheus Operator は、プラットフォーム Prometheus インスタンスおよび Alertmanager インスタンスを作成、設定、および管理します。また、Kubernetes ラベルのクエリーに基づいてモニタリングターゲットの設定を自動生成します。 - サイレンス
- サイレンスをアラートに適用し、アラートの条件が true の場合に通知が送信されることを防ぐことができます。初期通知後はアラートをミュートにして、根本的な問題の解決に取り組むことができます。
- ストレージ
- OpenShift Container Platform は、オンプレミスおよびクラウドプロバイダーの両方で、多くのタイプのストレージをサポートします。OpenShift Container Platform クラスターで、永続データおよび非永続データ用のコンテナーストレージを管理できます。
- Thanos Ruler
- Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。
- Vector
- Vector は、各 OpenShift Container Platform ノードにデプロイするログコレクターです。各ノードからログデータを収集し、データを変換して、設定された出力に転送します。
- Web コンソール
- OpenShift Container Platform を管理するためのユーザーインターフェイス (UI)。