1.2. クラスターの更新の仕組み
以下のセクションでは、OpenShift Container Platform (OCP) 更新プロセスの各主要点を詳しく説明しています。更新の仕組みの概要は、OpenShift 更新の概要 を参照してください。
1.2.1. Cluster Version Operator
Cluster Version Operator (CVO) は、OpenShift Container Platform の更新プロセスを調整および促進する主要コンポーネントです。インストールや標準的なクラスター操作を実行する間、CVO はマネージドクラスター Operator のマニフェストとクラスター内リソースを常に比較し、これらのリソースの実際の状態が求められる状態と一致するように、不一致を調整します。
1.2.1.1. ClusterVersion オブジェクト
Cluster Version Operator (CVO) が監視するリソースの 1 つに、ClusterVersion リソースがあります。
管理者と OpenShift コンポーネントは、ClusterVersion オブジェクトを通じて CVO と通信または対話できます。CVO に求められる状態は ClusterVersion オブジェクトを通じて宣言され、現在の CVO 状態はオブジェクトのステータスに反映されます。
ClusterVersion オブジェクトは直接変更しないでください。代わりに、oc CLI や Web コンソールなどのインターフェイスを使用して、更新ターゲットを宣言します。
CVO は、ClusterVersion リソースの spec プロパティーで宣言されたターゲットとする状態とクラスターを継続的に調整します。必要なリリースと実際のリリースが異なる場合、その調整によってクラスターが更新されます。
1.2.1.1.1. 可用性データの更新
ClusterVersion リソースには、クラスターが利用できる更新に関する情報も含まれています。これには、利用可能ではあるが、クラスターに適用される既知のリスクのため推奨されない更新も含まれます。これらの更新は条件付き更新として知られています。CVO が ClusterVersion リソース内の利用可能な更新に関する情報をどのように維持するかは、「更新の可用性評価」セクションを参照してください。
以下のコマンドを使用して、利用可能なすべての更新を確認できます。
$ oc adm upgrade --include-not-recommended注記追加の
--include-not-recommendedパラメーターには、クラスターに適用される既知の問題で利用可能な更新が含まれます。出力例
Cluster version is 4.13.40 Upstream is unset, so the cluster will use an appropriate default. Channel: stable-4.14 (available channels: candidate-4.13, candidate-4.14, eus-4.14, fast-4.13, fast-4.14, stable-4.13, stable-4.14) Recommended updates: VERSION IMAGE 4.14.27 quay.io/openshift-release-dev/ocp-release@sha256:4d30b359aa6600a89ed49ce6a9a5fdab54092bcb821a25480fdfbc47e66af9ec 4.14.26 quay.io/openshift-release-dev/ocp-release@sha256:4fe7d4ccf4d967a309f83118f1a380a656a733d7fcee1dbaf4d51752a6372890 4.14.25 quay.io/openshift-release-dev/ocp-release@sha256:a0ef946ef8ae75aef726af1d9bbaad278559ad8cab2c1ed1088928a0087990b6 4.14.24 quay.io/openshift-release-dev/ocp-release@sha256:0a34eac4b834e67f1bca94493c237e307be2c0eae7b8956d4d8ef1c0c462c7b0 4.14.23 quay.io/openshift-release-dev/ocp-release@sha256:f8465817382128ec7c0bc676174bad0fb43204c353e49c146ddd83a5b3d58d92 4.13.42 quay.io/openshift-release-dev/ocp-release@sha256:dcf5c3ad7384f8bee3c275da8f886b0bc9aea7611d166d695d0cf0fff40a0b55 4.13.41 quay.io/openshift-release-dev/ocp-release@sha256:dbb8aa0cf53dc5ac663514e259ad2768d8c82fd1fe7181a4cfb484e3ffdbd3ba Updates with known issues: Version: 4.14.22 Image: quay.io/openshift-release-dev/ocp-release@sha256:7093fa606debe63820671cc92a1384e14d0b70058d4b4719d666571e1fc62190 Reason: MultipleReasons Message: Exposure to AzureRegistryImageMigrationUserProvisioned is unknown due to an evaluation failure: client-side throttling: only 18.061µs has elapsed since the last match call completed for this cluster condition backend; this cached cluster condition request has been queued for later execution In Azure clusters with the user-provisioned registry storage, the in-cluster image registry component may struggle to complete the cluster update. https://issues.redhat.com/browse/IR-468 Incoming HTTP requests to services exposed by Routes may fail while routers reload their configuration, especially when made with Apache HTTPClient versions before 5.0. The problem is more likely to occur in clusters with higher number of Routes and corresponding endpoints. https://issues.redhat.com/browse/NE-1689 Version: 4.14.21 Image: quay.io/openshift-release-dev/ocp-release@sha256:6e3fba19a1453e61f8846c6b0ad3abf41436a3550092cbfd364ad4ce194582b7 Reason: MultipleReasons Message: Exposure to AzureRegistryImageMigrationUserProvisioned is unknown due to an evaluation failure: client-side throttling: only 33.991µs has elapsed since the last match call completed for this cluster condition backend; this cached cluster condition request has been queued for later execution In Azure clusters with the user-provisioned registry storage, the in-cluster image registry component may struggle to complete the cluster update. https://issues.redhat.com/browse/IR-468 Incoming HTTP requests to services exposed by Routes may fail while routers reload their configuration, especially when made with Apache HTTPClient versions before 5.0. The problem is more likely to occur in clusters with higher number of Routes and corresponding endpoints. https://issues.redhat.com/browse/NE-1689oc adm upgradeコマンドは、利用可能な更新に関する情報をClusterVersionリソースにクエリーし、人間が判読できる形式で表示します。CVO が作成した基礎となる可用性データを直接検査する方法の 1 つに、次のコマンドを使用して
ClusterVersionリソースをクエリーする方法があります。$ oc get clusterversion version -o json | jq '.status.availableUpdates'出力例
[ { "channels": [ "candidate-4.11", "candidate-4.12", "fast-4.11", "fast-4.12" ], "image": "quay.io/openshift-release-dev/ocp-release@sha256:400267c7f4e61c6bfa0a59571467e8bd85c9188e442cbd820cc8263809be3775", "url": "https://access.redhat.com/errata/RHBA-2023:3213", "version": "4.11.41" }, ... ]同様のコマンドを使用して条件付き更新を確認できます。
$ oc get clusterversion version -o json | jq '.status.conditionalUpdates'出力例
[ { "conditions": [ { "lastTransitionTime": "2023-05-30T16:28:59Z", "message": "The 4.11.36 release only resolves an installation issue https://issues.redhat.com//browse/OCPBUGS-11663 , which does not affect already running clusters. 4.11.36 does not include fixes delivered in recent 4.11.z releases and therefore upgrading from these versions would cause fixed bugs to reappear. Red Hat does not recommend upgrading clusters to 4.11.36 version for this reason. https://access.redhat.com/solutions/7007136", "reason": "PatchesOlderRelease", "status": "False", "type": "Recommended" } ], "release": { "channels": [...], "image": "quay.io/openshift-release-dev/ocp-release@sha256:8c04176b771a62abd801fcda3e952633566c8b5ff177b93592e8e8d2d1f8471d", "url": "https://access.redhat.com/errata/RHBA-2023:1733", "version": "4.11.36" }, "risks": [...] }, ... ]
1.2.1.2. 更新の可用性評価
Cluster Version Operator (CVO) は、OpenShift Update Service (OSUS) に対して、更新の可能性に関する最新データを定期的にクエリーします。このデータは、クラスターがサブスクライブしているチャネルに基づいています。次に、CVO は更新の推奨事項に関する情報を、ClusterVersion リソースの availableUpdates フィールドまたは conditionalUpdates フィールドに保存します。
CVO は、条件付き更新の更新リスクを定期的に確認します。これらのリスクは、OSUS によって提供されるデータを通じて伝えられます。このデータには、そのバージョンに更新されたクラスターに影響を与える可能性がある各バージョンの既知の問題に関する情報が含まれています。ほとんどのリスクは、特定のサイズのクラスターや特定のクラウドプラットフォームにデプロイされたクラスターなど、特定の特性を持つクラスターに限定されます。
CVO は、各条件付き更新の条件付きリスクに関する情報に対して、継続的にクラスターの特性を評価します。CVO は、クラスターが基準に一致することを検出すると、その情報を ClusterVersion リソースの conditionalUpdates フィールドに保存します。CVO は、クラスターが更新のリスクに一致しないこと、または更新に関連するリスクがないことを検出すると、ターゲットバージョンを ClusterVersion リソースの availableUpdates フィールドに保存します。
Web コンソールまたは OpenShift CLI (oc) のユーザーインターフェイスは、この情報をセクションの見出しで表示します。更新パスに関連付けられた既知の問題にはそれぞれ、リスクに関する詳細なリソースへのリンクが含まれているため、管理者は更新について十分な情報に基づいた決定を下すことができます。
1.2.2. リリースイメージ
リリースイメージは、特定の OpenShift Container Platform (OCP) バージョンのディストリビューションメカニズムです。これには、リリースメタデータ、リリースバージョンに一致する Cluster Version Operator (CVO) バイナリー、個々の OpenShift Cluster Operator のデプロイに必要なすべてのマニフェスト、この OpenShift バージョンを構成するすべてのコンテナーイメージへの SHA ダイジェストバージョン参照リストが含まれています。
次のコマンドを実行して、特定のリリースイメージの内容を検査できます。
$ oc adm release extract <release image>$ oc adm release extract quay.io/openshift-release-dev/ocp-release:4.12.6-x86_64
Extracted release payload from digest sha256:800d1e39d145664975a3bb7cbc6e674fbf78e3c45b5dde9ff2c5a11a8690c87b created at 2023-03-01T12:46:29Z$ ls0000_03_authorization-openshift_01_rolebindingrestriction.crd.yaml
0000_03_config-operator_01_proxy.crd.yaml
0000_03_marketplace-operator_01_operatorhub.crd.yaml
0000_03_marketplace-operator_02_operatorhub.cr.yaml
0000_03_quota-openshift_01_clusterresourcequota.crd.yaml
...
0000_90_service-ca-operator_02_prometheusrolebinding.yaml
0000_90_service-ca-operator_03_servicemonitor.yaml
0000_99_machine-api-operator_00_tombstones.yaml
image-references
release-metadata1.2.3. プロセスワークフローの更新
以下の手順は、OpenShift Container Platform (OCP) 更新プロセスの詳細なワークフローを示しています。
-
ターゲットバージョンは、
ClusterVersionリソースのspec.desiredUpdate.versionフィールドに保存され、Web コンソールまたは CLI から管理されます。 -
Cluster Version Operator (CVO) は、
ClusterVersionリソースのdesiredUpdateが現在のクラスターのバージョンとは異なることを検出します。OpenShift Update Service からのグラフデータを使用して、CVO は必要なクラスターバージョンをリリースイメージのプル仕様に解決します。 - CVO は、リリースイメージの整合性と信頼性を検証します。Red Hat は、イメージ SHA ダイジェストを一意で不変のリリースイメージ識別子として使用し、公開されたリリースイメージに関する暗号署名されたステートメントを事前定義された場所に公開します。CVO はビルトイン公開鍵のリストを使用して、チェックされたリリースイメージに一致するステートメントの存在と署名を検証します。
-
CVO は、
openshift-cluster-versionnamespace にversion-$version-$hashという名前のジョブを作成します。このジョブはリリースイメージを実行しているコンテナーを使用するため、クラスターはコンテナーランタイムを通じてイメージをダウンロードします。次に、ジョブはマニフェストとメタデータをリリースイメージから CVO がアクセス可能な共有ボリュームに展開します。 - CVO は、展開されたマニフェストとメタデータを検証します。
- CVO はいくつかの前提条件をチェックして、クラスター内で問題のある状態が検出されないことを確認します。特定の状態により、更新が続行できない場合があります。これらの状態は、CVO 自体によって決定されるか、Operator が更新に問題ありと判断するクラスターの詳細を検出する個々のクラスター Operator によって報告されます。
-
CVO は、承認されたリリースを
status.desiredに記録し、新しい更新に関するstatus.historyエントリーを作成します。 - CVO は、リリースイメージからマニフェストの調整を開始します。クラスター Operator は Runlevels と呼ばれる別のステージで更新され、CVO は次のレベルに進む前に Runlevel 内のすべての Operator が更新を完了するようにします。
- CVO 自体のマニフェストはプロセスの早い段階で適用されます。CVO デプロイメントが適用されると、現在の CVO Pod が停止し、新しいバージョンを使用する CVO Pod が開始されます。新しい CVO は、残りのマニフェストの調整を進めます。
-
更新は、コントロールプレーン全体が新しいバージョンに更新されるまで続行されます。個々のクラスター Operator は、クラスターのドメインで更新タスクを実行することがあり、その場合は実行中に、
Progressing=True状態を通して状態を報告します。 - Machine Config Operator (MCO) マニフェストはプロセスの最後に適用されます。その後、更新された MCO は、すべてのノードのシステム設定とオペレーティングシステムの更新を開始します。各ノードは、再びワークロードの受け入れを開始する前に、ドレイン、更新、および再起動される可能性があります。
クラスターは、コントロールプレーンの更新が完了した後、通常はすべてのノードが更新される前に更新済みであることを報告します。更新後、CVO はすべてのクラスターリソースを、リリースイメージで提供される状態と一致するように維持します。
1.2.4. 更新時のマニフェストの適用方法について
リリースイメージで提供される一部のマニフェストは、依存関係があるため、特定の順序で適用する必要があります。たとえば、CustomResourceDefinition リソースは、一致するカスタムリソースの前に作成する必要があります。さらに、クラスター内の断絶を最小限に抑えるために、個々のクラスター Operator は論理的な順序に従い更新される必要があります。Cluster Version Operator (CVO) は、Runlevels の概念を通じてこの論理的な順序を実装します。
これらの依存関係は、リリースイメージのマニフェストのファイル名でエンコードされます。
0000_<runlevel>_<component>_<manifest-name>.yaml以下に例を示します。
0000_03_config-operator_01_proxy.crd.yamlCVO は内部でマニフェストの依存関係グラフをビルドします。ここで CVO は次のルールに従います。
- 更新中、より低位の Runlevel のマニフェストは、高位の Runlevel のマニフェストよりも先に適用されます。
- 1 つの Runlevel 内で、異なるコンポーネントのマニフェストを並行して適用できます。
- 1 つの Runlevel 内で、単一のコンポーネントのマニフェストは辞書式の順序で適用されます。
次に、CVO は生成された依存関係グラフの順にマニフェストを適用します。
一部のリソースタイプでは、CVO はマニフェストの適用後にリソースを監視し、リソースが安定した状態に達して場合に限り正常に更新されたとみなします。この状態に達するまでに時間がかかる場合があります。これは特に ClusterOperator リソースに当てはまりますが、CVO はクラスター Operator が自身を更新するのを待ってから、その ClusterOperator ステータスを更新します。
CVO は、Runlevel のすべてのクラスター Operator が以下の状態になるまで待機してから、次の Runlevel に進みます。
-
クラスター Operator は
Available=Trueの状態です。 -
クラスター Operator は
Degraded=Falseの状態です。
- クラスター Operator は、ClusterOperator リソースで必要なバージョンになったことを宣言します。
一部のアクションは、完了するまでにかなりの時間がかかる場合があります。CVO は、後続の Runlevel で安全に続行できるように、アクションが完了するのを待ちます。新しいリリースのマニフェストを初めてリコンサイルする際には、合計で 60 - 120 分かかることが予想されます。更新期間に影響を与える要因の詳細は、OpenShift Container Platform の更新期間について を参照してください。
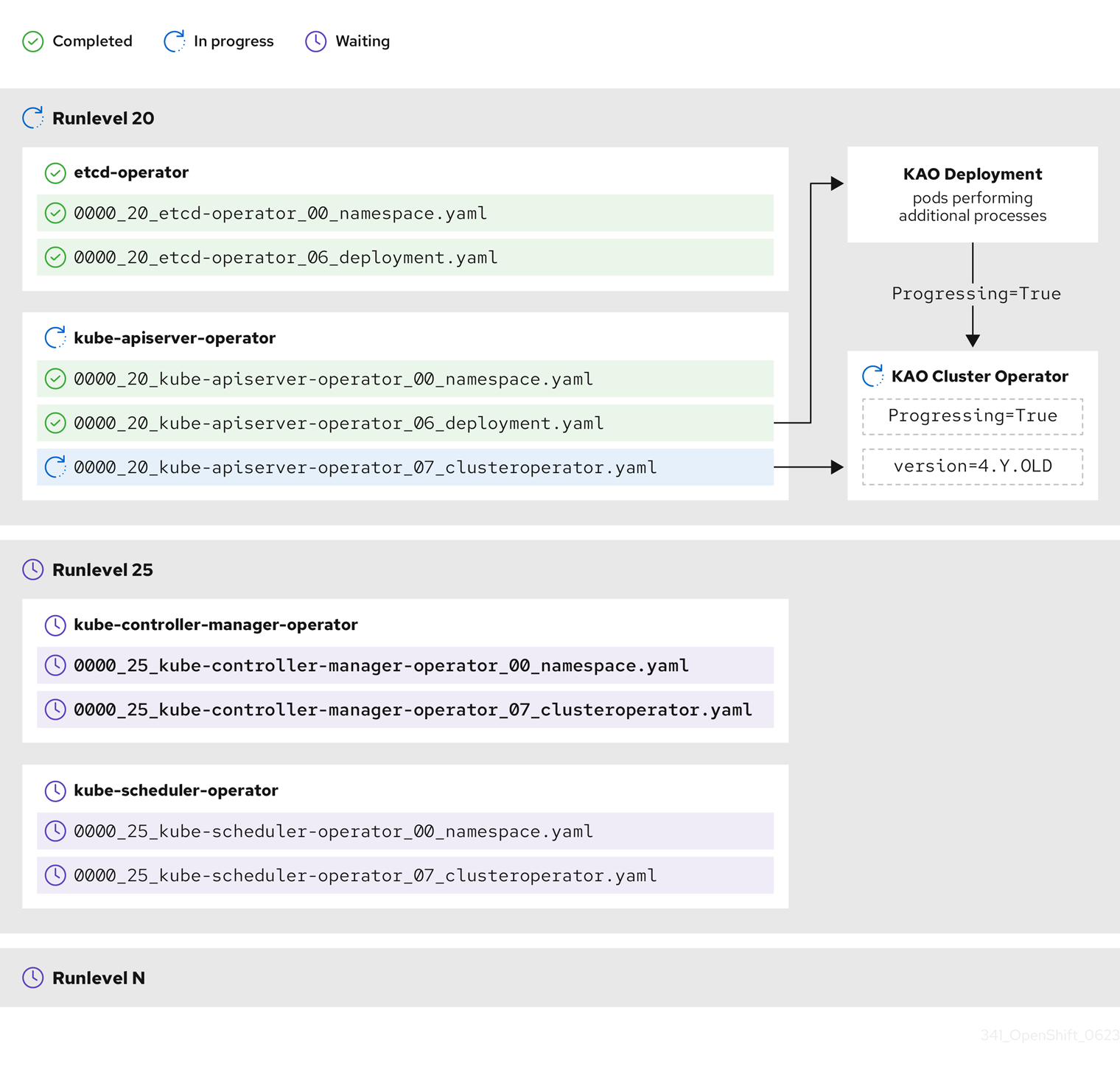
前のサンプル図では、CVO は Runlevel 20 ですべての作業が完了するまで待機しています。CVO はすべてのマニフェストを Runlevel の Operator に適用しましたが、kube-apiserver-operator ClusterOperator は一部のアクションを新しいバージョンがデプロイされた後に実行します。kube-apiserver-operator ClusterOperator は、Progressing=True という condition を設定し、かつ status.versions で新しいバージョンを調整済みとして宣言しないことによって、その進捗を伝えます。CVO は、ClusterOperator が許容可能なステータスを報告するまで待機し、その後、Runlevel 25 でマニフェストの調整を開始します。
1.2.5. Machine Config Operator によるノードの更新方法
Machine Config Operator (MCO) は、新しいマシン設定を各コントロールプレーンノードとコンピュートノードに適用します。マシン設定の更新時に、コントロールプレーンノードとコンピュートノードは、マシンプールが並行して更新される独自のマシン設定プールに編成されます。.spec.maxUnavailable パラメーター (デフォルト値は 1) は、マシン設定プール内の更新プロセスを同時に実行できるノードの数を決定します。
OpenShift Container Platform のすべてのマシン設定プールにおける maxUnavailable のデフォルト設定は 1 です。この値を変更せず、一度に 1 つのコントロールプレーンノードを更新することを推奨します。コントロールプレーンプールのこの値を 3 に変更しないでください。
マシン設定の更新プロセスが開始されると、MCO はプール内の現在利用できないノードの数を確認します。使用できないノードの数が .spec.maxUnavailable の値よりも少ない場合、MCO はプール内の使用可能なノードに対して次の一連のアクションを開始します。
ノードを遮断してドレインします。
注記ノードが遮断されている場合、ワークロードをそのノードにスケジュールすることはできません。
- ノードのシステム設定およびオペレーティングシステム (OS) を更新します。
- ノードを再起動します。
- ノードの遮断を解除します。
このプロセスが実行されているノードは、遮断が解除されてワークロードが再度スケジュールされるまで使用できません。MCO は、使用できないノードの数が .spec.maxUnavailable の値と等しくなるまでノードの更新を開始します。
ノードが更新を完了して使用可能になると、マシン設定プール内の使用不可ノードの数は再び .spec.maxUnavailable より少なくなります。更新する必要があるノードが残っている場合、MCO は .spec.maxUnavailable 制限に再度達するまで、ノード上で更新プロセスを開始します。このプロセスは、各コントロールプレーンノードとコンピュートノードが更新されるまで繰り返されます。
次のワークフロー例は、5 つのノードを持つマシン設定プールでこのプロセスがどのように発生するかを示しています。ここでの .spec.maxUnavailable は 3 で、最初はすべてのノードが使用可能です。
- MCO はノード 1、2、3 を遮断し、それらのドレインを開始します。
- ノード 2 は、ドレインを完了して再起動すると再び使用可能になります。MCO はノード 4 を遮断し、そのドレインを開始します。
- ノード 1 は、ドレインを完了して再起動すると再び使用可能になります。MCO はノード 5 を遮断し、そのドレインを開始します。
- ノード 3 は、ドレインを完了して再起動すると再び使用可能になります。
- ノード 5 は、ドレインを完了して再起動すると再び使用可能になります。
- ノード 4 は、ドレインを完了して再起動すると再び使用可能になります。
各ノードの更新プロセスは他のノードから独立しているため、上記の例におけるノードの一部は、MCO によって遮断された順序とは異なる順序で更新を終了します。
次のコマンドを実行して、マシン設定の更新ステータスを確認できます。
$ oc get mcp出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h
worker rendered-worker-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h