3.2. 通信事業者向け RAN DU リファレンス設計仕様
3.2.1. 通信事業者向け RAN DU 4.16 参照デザインの概要
Telco RAN 分散ユニット (DU) 4.16 リファレンスデザインは、コモディティーハードウェア上で実行している OpenShift Container Platform 4.16 クラスターを設定して、通信事業者向け RAN DU ワークロードをホストします。通信事業者向け RAN DU プロファイルを実行するクラスターで信頼性が高く再現性のあるパフォーマンスを得るために、推奨され、テストされ、サポートされている設定をキャプチャーします。
3.2.1.1. デプロイメントアーキテクチャーの概要
集中管理された RHACM ハブクラスターから、管理対象クラスターに通信事業者向け RAN DU 4.16 参照設定を展開します。リファレンスデザイン仕様 (RDS) には、管理対象クラスターとハブクラスターコンポーネントの設定が含まれます。
図3.1 通信事業者向け RAN DU デプロイメントアーキテクチャーの概要

3.2.2. 通信事業者向け RAN DU 使用モデルの概要
次の情報を使用して、ハブクラスターと管理対象シングルノード OpenShift クラスターの通信事業者向け RAN DU ワークロード、クラスターリソース、およびハードウェア仕様を計画します。
3.2.2.1. 通信事業者 RAN DU アプリケーションワークロード
DU ワーカーノードには、最大のパフォーマンスが得られるようにファームウェアが調整された、第 3 世代 Xeon (Ice Lake) 2.20 GHz 以上の CPU が必要です。
5G RAN DU ユーザーアプリケーションとワークロードは、次のベストプラクティスとアプリケーション制限に準拠する必要があります。
- CNF ベストプラクティスガイド の最新バージョンに準拠したクラウドネイティブネットワーク機能 (CNF) を開発します。
- 高性能ネットワークには SR-IOV を使用します。
exec プローブは控えめに使用し、他の適切なオプションが利用できない場合にのみ使用してください。
-
CNF が CPU ピンニングを使用する場合は、exec プローブを使用しないでください。
httpGetやtcpSocketなどの他のプローブ実装を使用します。 - exec プローブを使用する必要がある場合は、exec プローブの頻度と量を制限します。exec プローブの最大数は 10 未満に維持し、頻度は 10 秒以上にする必要があります。
-
CNF が CPU ピンニングを使用する場合は、exec プローブを使用しないでください。
- 絶対に実行可能な代替手段がない限り、exec プローブの使用は避けてください。
起動プローブは、定常状態の動作中に最小限のリソースしか必要としません。exec プローブの制限は、主に liveness および readiness プローブに適用されます。
3.2.2.2. 通信事業者向け RAN DU の代表的な参照アプリケーションワークロード特性
代表的な参照アプリケーションワークロードには、次の特性があります。
- 管理および制御機能を含む vRAN アプリケーション用に最大 15 個の Pod と 30 個のコンテナーを備えています。
-
Pod ごとに最大 2 つの
ConfigMapと 4 つのSecretCR を使用します。 - 10 秒以上の頻度で最大 10 個の exec プローブを使用します。
kube-apiserverの増分アプリケーション負荷は、クラスタープラットフォーム使用量の 10% 未満です。注記プラットフォームメトリクスから CPU 負荷を抽出できます。以下に例を示します。
query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])- アプリケーションログはプラットフォームログコレクターにより収集されません
- プライマリー CNI 上の総トラフィックは 1 MBps 未満です
3.2.2.3. 通信事業者向け RAN DU ワーカーノードクラスターリソース使用率
システム内で実行している Pod の最大数 (アプリケーションワークロードと OpenShift Container Platform Pod を含む) は 120 です。
- リソース利用
OpenShift Container Platform のリソース使用率は、次のようなアプリケーションのワークロード特性を含む多くの要因によって異なります。
- Pod 数
- プローブの種類と頻度
- カーネルネットワークを使用したプライマリー CNI またはセカンダリー CNI 上のメッセージングレート
- API アクセス率
- ロギングレート
- ストレージ IOPS
クラスターリソース要件は、次の条件で適用されます。
- クラスターは、説明した代表的なアプリケーションワークロードを実行しています。
- クラスターは、「通信事業者向け RAN DU ワーカーノードクラスターリソース使用率」で説明されている制約に従って管理されます。
- RAN DU 使用モデル設定でオプションとして記載されているコンポーネントは適用されません。
通信事業者向け RAN DU 参照デザインの範囲外の設定は、リソース使用率への影響と KPI 目標達成能力を判断するために、追加の分析を行う必要があります。要件に応じて、クラスターに関連情報を割り当てることが求められる場合があります。
3.2.2.4. ハブクラスター管理特性
推奨されるクラスター管理ソリューションは、Red Hat Advanced Cluster Management (RHACM) です。ハブクラスターで次の制限を設定します。
- 準拠した評価間隔が少なくとも 10 分である最大 5 つの RHACM ポリシーを設定します。
- ポリシーでは最大 10 個のマネージドクラスターテンプレートを使用します。可能な場合は、ハブ側のテンプレートを使用します。
policy-controllerおよびobservability-controllerアドオンを除くすべての RHACM アドオンを無効にします。Observabilityをデフォルト設定に設定します。重要オプションのコンポーネントを設定したり、追加機能を有効にしたりすると、追加のリソースが使用され、システム全体のパフォーマンスが低下する可能性があります。
詳細は、参照設計のデプロイメントコンポーネント を参照してください。
| メトリクス | Limit | 注記 |
|---|---|---|
| CPU の使用率 | 4000 mc 未満 - 2 コア (4 ハイパースレッド) | プラットフォーム CPU は、各予約済みコアの両方のハイパースレッドを含む予約済みコアに固定されます。このシステムは、定期的なシステムタスクとスパイクに対応できるように、定常状態で 3 つの CPU (3000mc) を使用するように設計されています。 |
| 使用されているメモリー | 16G 未満 |
3.2.2.5. 通信事業者向け RAN DU RDS コンポーネント
以下のセクションでは、通信事業者向け RAN DU ワークロードを実行するためにクラスターを設定およびデプロイするのに使用するさまざまな OpenShift Container Platform コンポーネントと設定を説明します。
図3.2 通信事業者向け RAN DU 参照設計コンポーネント
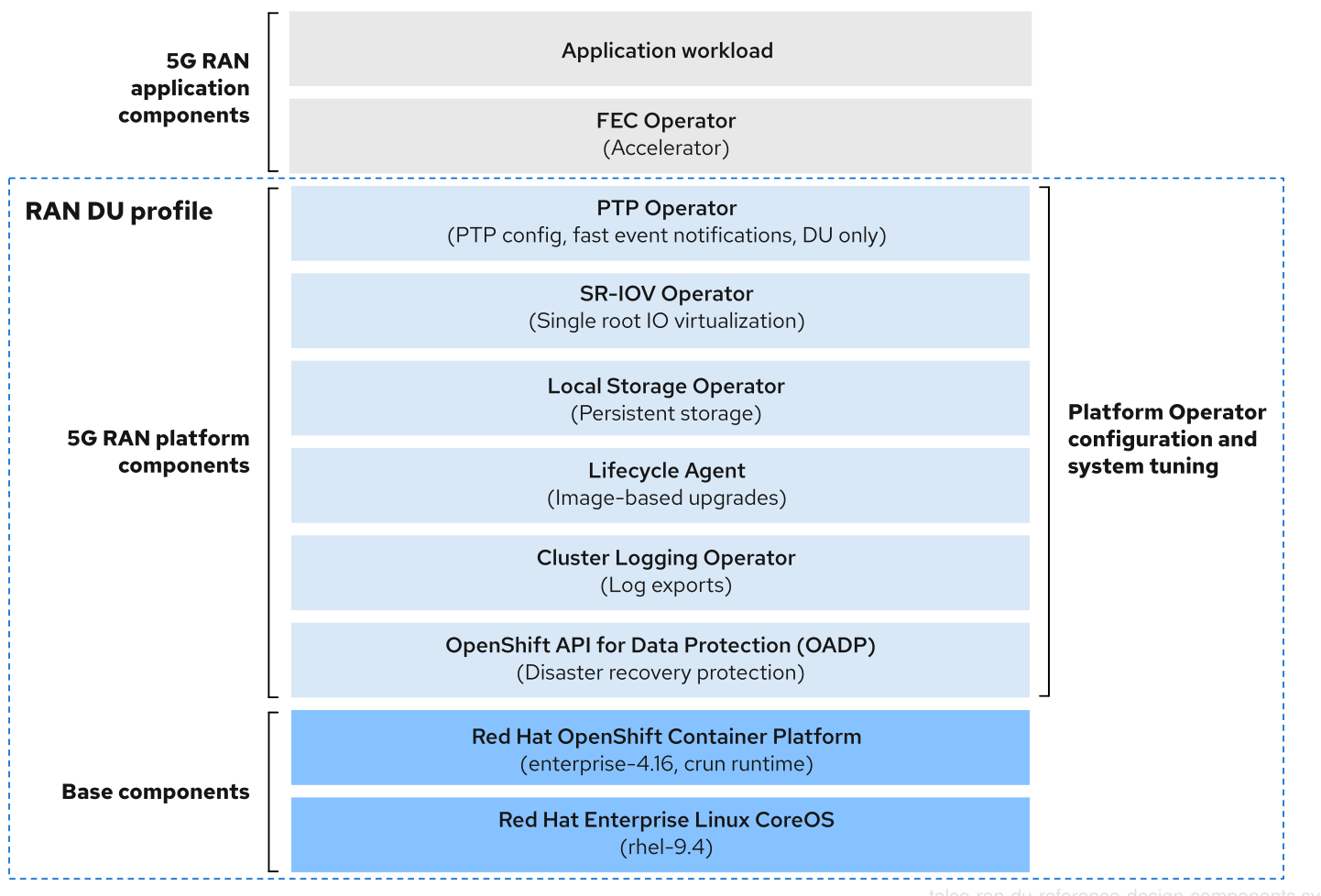
通信事業者向け RAN DU プロファイルに含まれていないコンポーネントが、ワークロードアプリケーションに割り当てられた CPU リソースに影響を与えないことを確認します。
ツリー外のドライバーはサポートされていません。
3.2.3. 通信事業者向け RAN DU 4.16 参照デザインコンポーネント
以下のセクションでは、RAN DU ワークロードを実行するためにクラスターを設定およびデプロイするのに使用するさまざまな OpenShift Container Platform コンポーネントと設定を説明します。
3.2.3.1. ホストファームウェアのチューニング
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
システムレベルのパフォーマンスを設定します。推奨設定は、低遅延と高パフォーマンスを実現するホストファームウェアの設定 を参照してください。
Ironic 検査が有効になっていると、ファームウェア設定値はハブクラスター上のクラスターごとの
BareMetalHostCR から入手できます。クラスターのインストールに使用するSiteConfigCR のspec.clusters.nodesフィールドのラベルを使用して、Ironic 検査を有効にします。以下に例を示します。nodes: - hostName: "example-node1.example.com" ironicInspect: "enabled"注記通信事業者向け RAN DU 参照
SiteConfigでは、ironicInspectフィールドはデフォルトで有効になりません。- 制限と要件
- ハイパースレッディングを有効にする必要がある
- エンジニアリングに関する考慮事項
パフォーマンスを最大限に高めるためにすべての設定を調整する
注記必要に応じて、パフォーマンスを犠牲にして電力を節約するためにファームウェアの選択を調整できます。
3.2.3.2. Node Tuning Operator
- このリリースの新機能
-
このリリースでは、Node Tuning Operator は、予約済みおよび分離されたコア CPU の
PerformanceProfileで CPU 周波数の設定をサポートします。これは、特定の周波数を定義するために使用できるオプションの機能です。この機能を使用して、Intel ハードウェアのintel_pstateCPUFreqドライバーを有効にし、特定の周波数を設定します。FlexRAN のようなアプリケーションの周波数については、Intel の推奨事項に従う必要があります。このようなアプリケーションでは、デフォルトの CPU 周波数をデフォルトの実行周波数よりも低い値に設定する必要があります。 -
以前は、RAN DU プロファイルの場合、
PerformanceProfileでrealTimeワークロードヒントをtrueに設定すると、常にintel_pstateが無効になりました。このリリースでは、Node Tuning Operator はTuneDを使用して基盤となる Intel ハードウェアを検出し、プロセッサーの世代に基づいてintel_pstateカーネルパラメーターを適切に設定します。 - このリリースでは、パフォーマンスプロファイルを持つ OpenShift Container Platform デプロイメントでは、基盤となるリソース管理レイヤーとして cgroups v2 がデフォルトで使用されるようになりました。この変更に対応していないワークロードを実行する場合でも、古い cgroups v1 メカニズムに戻すことができます。
-
このリリースでは、Node Tuning Operator は、予約済みおよび分離されたコア CPU の
- 説明
パフォーマンスプロファイルを作成して、クラスターのパフォーマンスを調整します。パフォーマンスプロファイルで設定する設定には次のものが含まれます。
- リアルタイムカーネルまたは非リアルタイムカーネルを選択します。
-
予約済みまたは分離された
cpusetにコアを割り当てます。管理ワークロードパーティションに割り当てられた OpenShift Container Platform プロセスは、予約セットに固定されます。 - kubelet 機能 (CPU マネージャー、トポロジーマネージャー、メモリーマネージャー) を有効にします。
- Huge Page の設定
- 追加のカーネル引数を設定します。
- コアごとの電力調整と最大 CPU 周波数を設定します。
- 予約済みおよび分離されたコア周波数チューニング。
- 制限と要件
Node Tuning Operator は、
PerformanceProfileCR を使用してクラスターを設定します。RAN DU プロファイルPerformanceProfileCR で次の設定を設定する必要があります。- 予約済みおよび分離されたコアを選択し、最大のパフォーマンスが得られるようにファームウェアが調整された Intel 第 3 世代 Xeon (Ice Lake) 2.20 GHz CPU 以上に少なくとも 4 つのハイパースレッド (2 つのコアに相当) を割り当てるようにします。
-
予約済みの
cpusetを設定して、含まれる各コアの両方のハイパースレッドシブリングを含めます。予約されていないコアは、ワークロードのスケジュールに割り当て可能な CPU として使用できます。ハイパースレッドシブリングが予約済みコアと分離コアに分割されていないことを確認します。 - 予約済みおよび分離された CPU として設定した内容に基づいて、すべてのコアのすべてのスレッドを含めるように予約済みおよび分離された CPU を設定します。
- 各 NUMA ノードのコア 0 を予約済み CPU セットに含めるように設定します。
- huge page のサイズを 1G に設定します。
管理パーティションにワークロードをさらに追加しないでください。OpenShift 管理プラットフォームの一部である Pod のみを管理パーティションにアノテーション付けする必要があります。
- エンジニアリングに関する考慮事項
パフォーマンス要件を満たすには、RT カーネルを使用する必要があります。
注記必要に応じて、非 RT カーネルを使用できます。
- 設定する huge page の数は、アプリケーションのワークロード要件によって異なります。このパラメーターの変動は予想され、許容されます。
- 選択されたハードウェアとシステムで使用されている追加コンポーネントに基づいて、予約済みおよび分離された CPU セットの設定に変化が生じることが予想されます。変動は指定された制限を満たす必要があります。
- IRQ アフィニティーをサポートしていないハードウェアは、分離された CPU に影響します。CPU 全体の QoS が保証された Pod が割り当てられた CPU を最大限に活用できるようにするには、サーバー内のすべてのハードウェアが IRQ アフィニティーをサポートする必要があります。詳細は、IRQ アフィニティー設定のサポートについて を参照してください。
cgroup v1 は非推奨の機能です。非推奨の機能は依然として OpenShift Container Platform に含まれており、引き続きサポートされますが、この製品の今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧は、OpenShift Container Platform リリースノートの 非推奨および削除された機能 セクションを参照してください。
3.2.3.3. PTP Operator
- このリリースの新機能
- デュアル Intel E810 Westport Channel NIC のグランドマスタークロック (T-GM) として linuxptp サービスを設定する機能が、一般に利用可能になりました。
-
linuxptpサービスptp4lおよびphc2sysを、デュアル PTP 境界クロック (T-BC) の高可用性 (HA) システムクロックとして設定できます。
- 説明
クラスターノードでの PTP のサポートと設定の詳細は、PTP タイミング を参照してください。DU ノードは次のモードで実行できます。
- グランドマスタークロックまたは境界クロック (T-BC) に同期された通常のクロック (OC) として
- シングルまたはデュアルカード E810 Westport Channel NIC をサポートする、GPS から同期されるグランドマスタークロックとして
- E810 Westport Channel NIC をサポートするデュアル境界クロック (NIC ごとに 1 つ)
- 異なる NIC 上に複数の時間ソースがある場合に、システムクロックの高可用性を実現します。
- オプション: 無線ユニット (RU) の境界クロックとして
グランドマスタークロックのイベントとメトリクスは、4.14 通信事業者向け RAN DU RDS で追加されたテクニカルプレビュー機能です。詳細は、PTP ハードウェア高速イベント通知フレームワークの使用 を参照してください。
DU アプリケーションが実行しているノードで発生する PTP イベントにアプリケーションをサブスクライブできます。
- 制限と要件
- デュアル NIC および HA の場合、境界クロックは 2 つに制限されます。
- T-GM の WPC カード設定は 2 枚までに制限される
- エンジニアリングに関する考慮事項
- 通常のクロック、境界クロック、グランドマスタークロック、または PTP-HA の設定が提供されます。
-
PTP 高速イベント通知は
ConfigMapCR を使用して PTP イベントサブスクリプションを保存します。 - GPS タイミングを備えた PTP グランドマスタークロックには、Intel E810-XXV-4T Westport Channel NIC を使用します (最小ファームウェアバージョン 4.40)。
3.2.3.4. SR-IOV Operator
- このリリースの新機能
-
このリリースでは、SR-IOV Network Operator を使用して QinQ (802.1ad および 802.1q) タグ付けを設定できます。QinQ タグ付けは、内部 VLAN タグと外部 VLAN タグの両方の使用を可能にすることで、効率的なトラフィック管理を実現します。外部 VLAN タグ付けはハードウェアアクセラレーションされており、ネットワークパフォーマンスが向上します。この更新は SR-IOV Network Operator 自体を超えて拡張されます。
nmstateを使用して外部 VLAN タグを設定することで、外部のマネージド VF 上で QinQ を設定できるようになりました。QinQ のサポートは NIC によって異なります。特定の NIC モデルの既知の制限事項の包括的なリストについては、関連情報 セクションの SR-IOV 対応ワークロードに対する QinQ サポートの設定 を参照してください。 - このリリースでは、ネットワークポリシーの更新中にノードを並行してドレインするように SR-IOV Network Operator を設定できるため、セットアッププロセスが大幅に高速化されます。これは、特に以前は完了までに数時間、場合によっては数日かかっていた大規模なクラスターのデプロイメントにおいて、大幅な時間の節約につながります。
-
このリリースでは、SR-IOV Network Operator を使用して QinQ (802.1ad および 802.1q) タグ付けを設定できます。QinQ タグ付けは、内部 VLAN タグと外部 VLAN タグの両方の使用を可能にすることで、効率的なトラフィック管理を実現します。外部 VLAN タグ付けはハードウェアアクセラレーションされており、ネットワークパフォーマンスが向上します。この更新は SR-IOV Network Operator 自体を超えて拡張されます。
- 説明
-
SR-IOV Operator は、SR-IOV CNI およびデバイスプラグインをプロビジョニングおよび設定します。
netdevice(カーネル VF) とvfio(DPDK) デバイスの両方がサポートされています。 - 制限と要件
- OpenShift Container Platform 対応デバイスを使用する
- BIOS での SR-IOV および IOMMU の有効化: SR-IOV Network Operator は、カーネルコマンドラインで IOMMU を自動的に有効にします。
- SR-IOV VF は PF からリンク状態の更新を受信しません。リンクダウン検出が必要な場合は、プロトコルレベルでこれを設定する必要があります。
-
マルチネットワークポリシーは、
netdeviceドライバータイプにのみ適用できます。マルチネットワークポリシーにはiptablesツールが必要ですが、このツールではvfioドライバータイプを管理できません。
- エンジニアリングに関する考慮事項
-
vfioドライバータイプの SR-IOV インターフェイスは通常、高スループットまたは低レイテンシーを必要とするアプリケーションで追加のセカンダリーネットワークを有効にするために使用されます。 -
SriovNetworkおよびSriovNetworkNodePolicyカスタムリソース (CR) の設定と数は、顧客によって異なることが予想されます。 -
IOMMU カーネルのコマンドライン設定は、インストール時に
MachineConfigCR で適用されます。これにより、SriovOperatorCR がノードを追加するときにノードの再起動が発生しなくなります。 - 並列でノードをドレインするための SR-IOV サポートは、シングルノードの OpenShift クラスターには適用されません。
-
デプロイメントから
SriovOperatorConfigCR を除外すると、CR は自動的に作成されません。 - ワークロードを特定のノードにピン留めまたは制限するシナリオでは、SR-IOV 並列ノードドレイン機能によって Pod の再スケジュールは行われません。このようなシナリオでは、SR-IOV Operator は並列ノードドレイン機能を無効にします。
-
3.2.3.5. ロギング
- このリリースの新機能
- Cluster Logging Operator 6.0 はこのリリースの新機能です。既存の実装を更新して、新しいバージョンの API に適応させます。ポリシーを使用して、古い Operator アーティファクトを削除する必要があります。詳細は、関連情報 を参照してください。
- 説明
- ロギングを使用して、リモート分析のためにファーエッジのノードからログを収集します。推奨されるログコレクターは Vector です。
- エンジニアリングに関する考慮事項
- たとえば、インフラストラクチャー以外のログや、アプリケーションワークロードからの監査ログを処理するには、ロギングレートの増加に応じて CPU とネットワーク帯域幅の追加が必要になります。
OpenShift Container Platform 4.14 以降では、Vector が参照ログコレクターになります。
注記RAN 使用モデルでの fluentd の使用は非推奨です。
3.2.3.6. SRIOV-FEC Operator
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
- SRIOV-FEC Operator は、FEC アクセラレーターハードウェアをサポートするオプションのサードパーティー認定 Operator です。
- 制限と要件
FEC Operator v2.7.0 以降:
-
SecureBootがサポートされている -
PFのvfioドライバーでは、Pod に挿入されるvfio-tokenを使用する必要があります。Pod 内のアプリケーションは、EAL パラメーター--vfio-vf-tokenを使用してVFトークンを DPDK に渡すことができます。
-
- エンジニアリングに関する考慮事項
-
SRIOV-FEC Operator は、
isolatedCPU セットの CPU コアを使用します。 - たとえば、検証ポリシーを拡張することによって、アプリケーションデプロイメントの事前チェックの一部として FEC の準備を検証できます。
-
SRIOV-FEC Operator は、
3.2.3.7. Local Storage Operator
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
-
Local Storage Operator を使用して、アプリケーションで
PVCリソースとして使用できる永続ボリュームを作成できます。作成するPVリソースの数とタイプは、要件によって異なります。 - エンジニアリングに関する考慮事項
-
PVを作成する前に、PVCR のバッキングストレージを作成します。これは、パーティション、ローカルボリューム、LVM ボリューム、または完全なディスクにすることができます。 ディスクとパーティションの正しい割り当てを確認するには、各デバイスへのアクセスに使用されるハードウェアパス別に
LocalVolumeCR 内のデバイスリストを参照してください。論理名 (例:/dev/sda) は、ノードの再起動後も一貫性が保たれるとは限りません。詳細は、デバイス識別子に関する RHEL 9 のドキュメント を参照してください。
-
3.2.3.8. LVMS Operator
- このリリースの新機能
- このリリースではリファレンスデザインの更新はありません。
LVMS Operator はオプションのコンポーネントです。
LVMS Operator をストレージソリューションとして使用すると、Local Storage Operator が置き換えられ、必要な CPU がプラットフォームのオーバーヘッドとして管理パーティションに割り当てられます。参照設定には、これらのストレージソリューションのいずれか 1 つを含める必要がありますが、両方を含めることはできません。
- 説明
LVMS Operator は、ブロックおよびファイルストレージの動的なプロビジョニングを提供します。LVMS Operator は、アプリケーションが
PVCリソースとして使用できるローカルデバイスから論理ボリュームを作成します。ボリューム拡張やスナップショットも可能です。次の設定例では、インストールディスクを除くノード上の使用可能なすべてのディスクを活用する
vg1ボリュームグループを作成します。StorageLVMCluster.yaml
apiVersion: lvm.topolvm.io/v1alpha1 kind: LVMCluster metadata: name: storage-lvmcluster namespace: openshift-storage annotations: ran.openshift.io/ztp-deploy-wave: "10" spec: storage: deviceClasses: - name: vg1 thinPoolConfig: name: thin-pool-1 sizePercent: 90 overprovisionRatio: 10- 制限と要件
- シングルノードの OpenShift クラスターでは、永続ストレージは LVMS またはローカルストレージのいずれかによって提供される必要があり、両方によって提供される必要はありません。
- エンジニアリングに関する考慮事項
- ストレージ要件を満たす十分なディスクまたはパーティションが利用可能であることを確認します。
3.2.3.9. ワークロードパーティショニング
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
ワークロードパーティショニングは、DU プロファイルの一部である OpenShift プラットフォームと Day 2 Operator Pod を予約済み
cpusetに固定し、予約済み CPU をノードアカウンティングから削除します。これにより、予約されていないすべての CPU コアがユーザーのワークロードに使用できるようになります。OpenShift Container Platform 4.14 では、ワークロードパーティショニングを有効にして設定する方法が変更されました。
- 4.14 以降
インストールパラメーターを設定してパーティションを設定します。
cpuPartitioningMode: AllNodes-
PerformanceProfileCR で予約された CPU セットを使用して管理パーティションコアを設定する
- 4.13 以前
-
インストール時に追加の
MachineConfigurationCR を適用してパーティションを設定する
-
インストール時に追加の
- 制限と要件
-
Pod を管理パーティションに適用できるようにするには、
NamespaceとPodCR にアノテーションを付ける必要がある - CPU 制限のある Pod をパーティションに割り当てることはできません。これは、ミューテーションによって Pod の QoS が変わる可能性があるためです。
- 管理パーティションに割り当てることができる CPU の最小数の詳細は、ノードチューニング Operator を参照してください。
-
Pod を管理パーティションに適用できるようにするには、
- エンジニアリングに関する考慮事項
- ワークロードパーティショニングでは、すべての管理 Pod を予約済みコアにピン固定します。オペレーティングシステム、管理 Pod、およびワークロードの開始、ノードの再起動、またはその他のシステムイベントの発生時に発生する CPU 使用率の予想される急増を考慮して、予約セットに十分な数のコアを割り当てる必要があります。
3.2.3.10. クラスターのチューニング
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
- インストール前に有効または無効にするオプションのコンポーネントの完全なリストについては、クラスター機能 セクションを参照してください。
- 制限と要件
- インストーラーによるプロビジョニングのインストール方法では、クラスター機能は使用できません。
すべてのプラットフォームチューニング設定を適用する必要があります。次の表に、必要なプラットフォームチューニング設定を示します。
Expand 表3.2 クラスター機能の設定 機能 説明 オプションのクラスター機能を削除する
シングルノードの OpenShift クラスターでのみオプションのクラスター Operator を無効にすることで、OpenShift Container Platform のフットプリントを削減します。
- Marketplace および Node Tuning Operator を除くすべてのオプションの Operator を削除します。
クラスター監視を設定する
次の手順を実行して、フットプリントを削減するようにモニタリングスタックを設定します。
-
ローカルの
alertmanagerコンポーネントおよびtelemeterコンポーネントを無効にします。 -
RHACM の可観測性を使用する際、アラートをハブクラスターに転送するには、適切な
additionalAlertManagerConfigsCR で CR を拡張する必要があります。 Prometheusの保持期間を 24 時間に短縮します。注記RHACM ハブクラスターは、マネージドクラスターメトリクスを集約します。
ネットワーク診断を無効にする
シングルノード OpenShift のネットワーク診断は必要ないため無効にします。
単一の OperatorHub カタログソースを設定する
RAN DU デプロイメントに必要な Operator のみを含む単一のカタログソースを使用するようにクラスターを設定します。各カタログソースにより、クラスター上の CPU 使用率が増加します。単一の
CatalogSourceを使用すると、プラットフォームの CPU 予算内に収まります。
- エンジニアリングに関する考慮事項
- このリリースでは、OpenShift Container Platform デプロイメントはデフォルトで Control Groups バージョン 2 (cgroup v2) を使用します。その結果、クラスター内のパフォーマンスプロファイルは、基盤となるリソース管理レイヤーに cgroups v2 を使用します。クラスター上で実行しているワークロードに cgroups v1 が必要な場合は、cgroups v1 を使用するようにノードを設定できます。この設定は、初期クラスターデプロイメントの一部として行うことができます。
3.2.3.11. マシン設定
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 制限と要件
CRI-O ワイプ無効化
MachineConfigは、定義されたメンテナンスウィンドウ内のスケジュールされたメンテナンス時以外は、ディスク上のイメージが静的であると想定します。イメージが静的であることを保証するには、Pod のimagePullPolicyフィールドをAlwaysに設定しないでください。Expand 表3.3 マシン設定オプション 機能 説明 コンテナーランタイム
すべてのノードロールのコンテナーランタイムを
crunに設定します。kubelet の設定とコンテナーマウントの非表示
kubelet ハウスキーピングとエビクションモニタリングの頻度を減らして、CPU 使用量を削減します。システムマウントスキャンのリソース使用量を削減するために、kubelet と CRI-O に表示されるコンテナーマウント namespace を作成します。
SCTP
オプション設定 (デフォルトで有効): SCTP を有効にします。SCTP は RAN アプリケーションで必要ですが、RHCOS ではデフォルトで無効になっています。
kdump
オプション設定 (デフォルトで有効): カーネルパニックが発生したときに kdump がデバッグ情報をキャプチャーできるようにします。
CRI-O ワイプ無効化
不正なシャットダウン後の CRI-O イメージキャッシュの自動消去を無効にします。
SR-IOV 関連のカーネル引数
カーネルコマンドラインに SR-IOV 関連の追加引数を含めます。
RCU 通常の systemd サービス
システムが完全に起動した後に
rcu_normalを設定します。ワンショット時間同期
コントロールプレーンまたはワーカーノードに対して、1 回限りのシステム時間同期ジョブを実行します。
3.2.3.12. Lifecycle Agent
- このリリースの新機能
- Lifecycle Agent を使用して、シングルノードの OpenShift クラスターのイメージベースのアップグレードを有効にします。
- 説明
- Lifecycle Agent は、シングルノードの OpenShift クラスターにローカルのライフサイクル管理サービスを提供します。
- 制限と要件
- Lifecycle Agent は、マルチノードクラスターまたは追加のワーカーを持つシングルノードの OpenShift クラスターには適用されません。
- 永続ボリュームが必要です。
3.2.3.13. 参照設計のデプロイメントコンポーネント
次のセクションでは、Red Hat Advanced Cluster Management (RHACM) を使用してハブクラスターを設定するために使用するさまざまな OpenShift Container Platform コンポーネントと設定を説明します。
3.2.3.13.1. Red Hat Advanced Cluster Management (RHACM)
- このリリースの新機能
-
PolicyGeneratorリソースと Red Hat Advanced Cluster Management (RHACM) を使用して、GitOps ZTP でマネージドクラスターのポリシーをデプロイできるようになりました。これはテクノロジープレビューの機能です。
-
- 説明
RHACM は、デプロイされたクラスターに対して、Multi Cluster Engine (MCE) のインストールと継続的なライフサイクル管理機能を提供します。
PolicyCR を使用して設定とアップグレードを宣言的に指定し、Topology Aware Lifecycle Manager が管理する RHACM ポリシーコントローラーを使用してクラスターにポリシーを適用します。- GitOps Zero Touch Provisioning (ZTP) は、RHACM の MCE 機能を使用します
- 設定、アップグレード、クラスターステータスは RHACM ポリシーコントローラーで管理されます。
インストール中に、RHACM は
SiteConfigカスタムリソース (CR) で設定されたとおりに個々のノードにラベルを適用できます。- 制限と要件
-
単一のハブクラスターは、各クラスターに 5 つの
PolicyCR がバインドされた、最大 3500 個のデプロイされたシングルノード OpenShift クラスターをサポートします。
-
単一のハブクラスターは、各クラスターに 5 つの
- エンジニアリングに関する考慮事項
- RHACM ポリシーハブ側テンプレートを使用して、クラスター設定をより適切にスケーリングします。グループおよびクラスターごとの値がテンプレートに置き換えられる単一のグループポリシーまたは少数の一般的なグループポリシーを使用することで、ポリシーの数を大幅に削減できます。
-
クラスター固有の設定: マネージドクラスターには通常、個々のクラスターに固有の設定値がいくつかあります。これらの設定は、クラスター名に基づいて
ConfigMapCR から取得された値を使用して、RHACM ポリシーハブ側テンプレートを使用して管理する必要があります。 - マネージドクラスターの CPU リソースを節約するには、クラスターの GitOps ZTP インストール後に、静的設定を適用するポリシーをマネージドクラスターからアンバインドする必要があります。
3.2.3.13.2. Topology Aware Lifecycle Manager (TALM)
- このリリースの新機能
- このリリースではリファレンス設計の更新はありません。
- 説明
- 管理された更新
TALM は、ハブクラスター上でのみ実行し、変更 (クラスターおよび Operator のアップグレード、設定などを含む) がネットワークに展開される方法を管理するための Operator です。TALM は次のことを行います。
-
PolicyCR を使用して、ユーザーが設定可能なバッチでクラスターのフリートに更新を段階的に適用します。 -
クラスターごとに
ztp-doneラベルまたはその他のユーザー設定可能なラベルを追加します。
-
- シングルノード OpenShift クラスターの事前キャッシュ
TALM は、アップグレードを開始する前に、OpenShift Container Platform、OLM Operator、および追加のユーザーイメージをシングルノードの OpenShift クラスターに事前キャッシュするオプションをサポートします。
オプションの事前キャッシュ設定を指定するために、
PreCachingConfigカスタムリソースを使用できます。以下に例を示します。apiVersion: ran.openshift.io/v1alpha1 kind: PreCachingConfig metadata: name: example-config namespace: example-ns spec: additionalImages: - quay.io/foobar/application1@sha256:3d5800990dee7cd4727d3fe238a97e2d2976d3808fc925ada29c559a47e2e - quay.io/foobar/application2@sha256:3d5800123dee7cd4727d3fe238a97e2d2976d3808fc925ada29c559a47adf - quay.io/foobar/applicationN@sha256:4fe1334adfafadsf987123adfffdaf1243340adfafdedga0991234afdadfs spaceRequired: 45 GiB1 overrides: preCacheImage: quay.io/test_images/pre-cache:latest platformImage: quay.io/openshift-release-dev/ocp-release@sha256:3d5800990dee7cd4727d3fe238a97e2d2976d3808fc925ada29c559a47e2e operatorsIndexes: - registry.example.com:5000/custom-redhat-operators:1.0.0 operatorsPackagesAndChannels: - local-storage-operator: stable - ptp-operator: stable - sriov-network-operator: stable excludePrecachePatterns:2 - aws - vsphere
- 制限と要件
- TALM は 400 のバッチでの同時クラスターデプロイメントをサポートします
- 事前キャッシュおよびバックアップ機能は、シングルノードの OpenShift クラスターのみを対象としています。
- エンジニアリングに関する考慮事項
-
PreCachingConfigCR はオプションであり、プラットフォーム関連 (OpenShift および OLM Operator) イメージを事前キャッシュするだけの場合は作成する必要はありません。ClusterGroupUpgradeCR で参照する前に、PreCachingConfigCR を適用する必要があります。
-
3.2.3.13.3. GitOps および GitOps ZTP プラグイン
- このリリースの新機能
- このリリースではリファレンス設計の更新はありません。
- 説明
GitOps および GitOps ZTP プラグインは、クラスターのデプロイメントと設定を管理するための GitOps ベースのインフラストラクチャーを提供します。クラスターの定義と設定は、Git で宣言的な状態として維持されます。ZTP プラグインは、
SiteConfigCR からインストール CR を生成することと、PolicyGenTemplateCR に基づいてポリシーに設定 CR を自動的にラップすることをサポートします。ベースライン参照設定 CR を使用して、マネージドクラスターに OpenShift Container Platform の複数のバージョンをデプロイおよび管理できます。ベースライン CR と並行してカスタム CR を使用することもできます。
- 制限
-
ArgoCD アプリケーションごとに 300 個の
SiteConfigCR。複数のアプリケーションを使用することで、単一のハブクラスターでサポートされるクラスターの最大数を実現できます。 -
Git の
/source-crsフォルダー内のコンテンツは、GitOps ZTP プラグインコンテナーで提供されるコンテンツを上書きします。検索パスでは Git が優先されます。 kustomization.yamlファイルと同じディレクトリーに/source-crsフォルダーを追加します。このフォルダーには、ジェネレーターとしてPolicyGenTemplateが含まれています。注記このコンテキストでは、
/source-crsディレクトリーの代替の場所はサポートされていません。
-
ArgoCD アプリケーションごとに 300 個の
- エンジニアリングに関する考慮事項
-
コンテンツを更新するときに混乱や意図しないファイルの上書きを避けるため、
/source-crsフォルダー内のユーザー指定の CR と Git 内の追加マニフェストには、一意で区別できる名前を使用します。 -
SiteConfigCR では、複数の追加マニフェストパスが許可されます。複数のディレクトリーパスで同じ名前のファイルが見つかった場合は、最後に見つかったファイルが優先されます。これにより、バージョン固有の Day 0 マニフェスト (追加マニフェスト) の完全なセットを Git に配置し、SiteConfigCR から参照できるようになります。この機能を使用すると、複数の OpenShift Container Platform バージョンをマネージドクラスターに同時にデプロイできます。 -
SiteConfigCR のextraManifestPathフィールドは、OpenShift Container Platform 4.15 以降では非推奨です。代わりに新しいextraManifests.searchPathsフィールドを使用してください。
-
コンテンツを更新するときに混乱や意図しないファイルの上書きを避けるため、
3.2.3.13.4. Agent-based Installer
- このリリースの変更点
- このリリースではリファレンス設計の更新はありません。
- 説明
Agent-based Installer (ABI) は、集中型インフラストラクチャーなしでインストール機能を提供します。インストールプログラムは、サーバーにマウントする ISO イメージを作成します。サーバーが起動すると、OpenShift Container Platform と提供された追加のマニフェストがインストールされます。
注記ABI を使用して、ハブクラスターなしで OpenShift Container Platform クラスターをインストールすることもできます。このように ABI を使用する場合でも、イメージレジストリーは必要です。
Agent-based Installer (ABI) はオプションのコンポーネントです。
- 制限と要件
- インストール時に、追加のマニフェストの限定されたセットを提供できます。
-
RAN DU ユースケースに必要な
MachineConfigurationCR を含める必要があります。
- エンジニアリングに関する考慮事項
- ABI は、ベースラインの OpenShift Container Platform インストールを提供します。
- インストール後に、Day 2 Operator と残りの RAN DU ユースケース設定をインストールします。
3.2.4. 通信事業者向け RAN 分散ユニット (DU) 参照設定 CR
次のカスタムリソース (CR) を使用して、通信事業者向け RAN DU プロファイルを使用して OpenShift Container Platform クラスターを設定およびデプロイします。一部の CR は、要件に応じてオプションになります。変更できる CR フィールドは、CR 内で YAML コメントによってアノテーションが付けられます。
ztp-site-generate コンテナーイメージから RAN DU CR の完全なセットを抽出できます。詳細は、GitOps ZTP サイト設定リポジトリーの準備 を参照してください。
3.2.4.1. Day 2 Operator 参照 CR
| コンポーネント | 参照 CR | 任意 | このリリースの新機能 |
|---|---|---|---|
| クラスターロギング | いいえ | いいえ | |
| クラスターロギング | いいえ | いいえ | |
| クラスターロギング | いいえ | いいえ | |
| クラスターロギング | いいえ | いいえ | |
| クラスターロギング | いいえ | いいえ | |
| Lifecycle Agent | はい | はい | |
| Lifecycle Agent | はい | はい | |
| Lifecycle Agent | はい | はい | |
| Lifecycle Agent | はい | はい | |
| Local Storage Operator | はい | いいえ | |
| Local Storage Operator | はい | いいえ | |
| Local Storage Operator | はい | いいえ | |
| Local Storage Operator | はい | いいえ | |
| Local Storage Operator | はい | いいえ | |
| LVM Storage | いいえ | はい | |
| LVM Storage | いいえ | はい | |
| LVM Storage | いいえ | はい | |
| LVM Storage | いいえ | はい | |
| LVM Storage | いいえ | はい | |
| Node Tuning Operator | いいえ | いいえ | |
| Node Tuning Operator | いいえ | いいえ | |
| PTP 高速イベント通知 | はい | はい | |
| PTP 高速イベント通知 | はい | はい | |
| PTP 高速イベント通知 | はい | はい | |
| PTP 高速イベント通知 | はい | はい | |
| PTP 高速イベント通知 | はい | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | はい | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| PTP Operator | いいえ | いいえ | |
| SR-IOV FEC Operator | はい | いいえ | |
| SR-IOV FEC Operator | はい | いいえ | |
| SR-IOV FEC Operator | はい | いいえ | |
| SR-IOV FEC Operator | はい | いいえ | |
| SR-IOV Operator | いいえ | いいえ | |
| SR-IOV Operator | いいえ | いいえ | |
| SR-IOV Operator | いいえ | いいえ | |
| SR-IOV Operator | いいえ | はい | |
| SR-IOV Operator | いいえ | いいえ | |
| SR-IOV Operator | いいえ | いいえ | |
| SR-IOV Operator | いいえ | いいえ |
3.2.4.2. クラスターチューニング参照 CR
| コンポーネント | 参照 CR | 任意 | このリリースの新機能 |
|---|---|---|---|
| クラスター機能 | いいえ | いいえ | |
| ネットワーク診断を無効にする | いいえ | いいえ | |
| モニタリング設定 | いいえ | いいえ | |
| OperatorHub | いいえ | いいえ | |
| OperatorHub | いいえ | いいえ | |
| OperatorHub | いいえ | いいえ | |
| OperatorHub | いいえ | いいえ | |
| OperatorHub | はい | いいえ |
3.2.4.3. マシン設定のリファレンス CR
| コンポーネント | 参照 CR | 任意 | このリリースの新機能 |
|---|---|---|---|
| コンテナーランタイム (crun) | いいえ | いいえ | |
| コンテナーランタイム (crun) | いいえ | いいえ | |
| CRI-O ワイプを無効にする | いいえ | いいえ | |
| CRI-O ワイプを無効にする | いいえ | いいえ | |
| kdump の有効化 | いいえ | いいえ | |
| kdump の有効化 | いいえ | いいえ | |
| Kubelet の設定とコンテナーマウントの非表示 | いいえ | いいえ | |
| Kubelet の設定とコンテナーマウントの非表示 | いいえ | いいえ | |
| ワンショット時間同期 | いいえ | いいえ | |
| ワンショット時間同期 | いいえ | いいえ | |
| SCTP | いいえ | いいえ | |
| SCTP | いいえ | いいえ | |
| RCU を通常に設定 | いいえ | いいえ | |
| RCU を通常に設定 | いいえ | いいえ | |
| SR-IOV 関連のカーネル引数 | いいえ | はい | |
| SR-IOV 関連のカーネル引数 | いいえ | いいえ |
3.2.4.4. YAML リファレンス
以下は、通信事業者向け RAN DU 4.16 参照設定を構成するすべてのカスタムリソース (CR) の完全な参照です。
3.2.4.4.1. Day 2 Operator 参照 YAML
ClusterLogForwarder.yaml
apiVersion: "logging.openshift.io/v1"
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
annotations: {}
spec:
# outputs: $outputs
# pipelines: $pipelines
#apiVersion: "logging.openshift.io/v1"
#kind: ClusterLogForwarder
#metadata:
# name: instance
# namespace: openshift-logging
#spec:
# outputs:
# - type: "kafka"
# name: kafka-open
# url: tcp://10.46.55.190:9092/test
# pipelines:
# - inputRefs:
# - audit
# - infrastructure
# labels:
# label1: test1
# label2: test2
# label3: test3
# label4: test4
# name: all-to-default
# outputRefs:
# - kafka-openClusterLogging.yaml
apiVersion: logging.openshift.io/v1
kind: ClusterLogging
metadata:
name: instance
namespace: openshift-logging
annotations: {}
spec:
managementState: "Managed"
collection:
type: "vector"ClusterLogNS.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: openshift-logging
annotations:
workload.openshift.io/allowed: managementClusterLogOperGroup.yaml
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-logging
namespace: openshift-logging
annotations: {}
spec:
targetNamespaces:
- openshift-loggingClusterLogSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: cluster-logging
namespace: openshift-logging
annotations: {}
spec:
channel: "stable"
name: cluster-logging
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownImageBasedUpgrade.yaml
apiVersion: lca.openshift.io/v1
kind: ImageBasedUpgrade
metadata:
name: upgrade
spec:
stage: Idle
# When setting `stage: Prep`, remember to add the seed image reference object below.
# seedImageRef:
# image: $image
# version: $versionLcaSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: lifecycle-agent
namespace: openshift-lifecycle-agent
annotations: {}
spec:
channel: "stable"
name: lifecycle-agent
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownLcaSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-lifecycle-agent
annotations:
workload.openshift.io/allowed: management
labels:
kubernetes.io/metadata.name: openshift-lifecycle-agentLcaSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: lifecycle-agent
namespace: openshift-lifecycle-agent
annotations: {}
spec:
targetNamespaces:
- openshift-lifecycle-agentStorageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations: {}
name: example-storage-class
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: DeleteStorageLV.yaml
apiVersion: "local.storage.openshift.io/v1"
kind: "LocalVolume"
metadata:
name: "local-disks"
namespace: "openshift-local-storage"
annotations: {}
spec:
logLevel: Normal
managementState: Managed
storageClassDevices:
# The list of storage classes and associated devicePaths need to be specified like this example:
- storageClassName: "example-storage-class"
volumeMode: Filesystem
fsType: xfs
# The below must be adjusted to the hardware.
# For stability and reliability, it's recommended to use persistent
# naming conventions for devicePaths, such as /dev/disk/by-path.
devicePaths:
- /dev/disk/by-path/pci-0000:05:00.0-nvme-1
#---
## How to verify
## 1. Create a PVC
# apiVersion: v1
# kind: PersistentVolumeClaim
# metadata:
# name: local-pvc-name
# spec:
# accessModes:
# - ReadWriteOnce
# volumeMode: Filesystem
# resources:
# requests:
# storage: 100Gi
# storageClassName: example-storage-class
#---
## 2. Create a pod that mounts it
# apiVersion: v1
# kind: Pod
# metadata:
# labels:
# run: busybox
# name: busybox
# spec:
# containers:
# - image: quay.io/quay/busybox:latest
# name: busybox
# resources: {}
# command: ["/bin/sh", "-c", "sleep infinity"]
# volumeMounts:
# - name: local-pvc
# mountPath: /data
# volumes:
# - name: local-pvc
# persistentVolumeClaim:
# claimName: local-pvc-name
# dnsPolicy: ClusterFirst
# restartPolicy: Always
## 3. Run the pod on the cluster and verify the size and access of the `/data` mountStorageNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-local-storage
annotations:
workload.openshift.io/allowed: managementStorageOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openshift-local-storage
namespace: openshift-local-storage
annotations: {}
spec:
targetNamespaces:
- openshift-local-storageStorageSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: local-storage-operator
namespace: openshift-local-storage
annotations: {}
spec:
channel: "stable"
name: local-storage-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownLVMOperatorStatus.yaml
# This CR verifies the installation/upgrade of the Sriov Network Operator
apiVersion: operators.coreos.com/v1
kind: Operator
metadata:
name: lvms-operator.openshift-storage
annotations: {}
status:
components:
refs:
- kind: Subscription
namespace: openshift-storage
conditions:
- type: CatalogSourcesUnhealthy
status: "False"
- kind: InstallPlan
namespace: openshift-storage
conditions:
- type: Installed
status: "True"
- kind: ClusterServiceVersion
namespace: openshift-storage
conditions:
- type: Succeeded
status: "True"
reason: InstallSucceededStorageLVMCluster.yaml
apiVersion: lvm.topolvm.io/v1alpha1
kind: LVMCluster
metadata:
name: lvmcluster
namespace: openshift-storage
annotations: {}
spec: {}
#example: creating a vg1 volume group leveraging all available disks on the node
# except the installation disk.
# storage:
# deviceClasses:
# - name: vg1
# thinPoolConfig:
# name: thin-pool-1
# sizePercent: 90
# overprovisionRatio: 10StorageLVMSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: lvms-operator
namespace: openshift-storage
annotations: {}
spec:
channel: "stable"
name: lvms-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownStorageLVMSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-storage
labels:
workload.openshift.io/allowed: "management"
openshift.io/cluster-monitoring: "true"
annotations: {}StorageLVMSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: lvms-operator-operatorgroup
namespace: openshift-storage
annotations: {}
spec:
targetNamespaces:
- openshift-storagePerformanceProfile.yaml
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: falseTunedPerformancePatch.yaml
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: performance-patch
namespace: openshift-cluster-node-tuning-operator
annotations: {}
spec:
profile:
- name: performance-patch
# Please note:
# - The 'include' line must match the associated PerformanceProfile name, following below pattern
# include=openshift-node-performance-${PerformanceProfile.metadata.name}
# - When using the standard (non-realtime) kernel, remove the kernel.timer_migration override from
# the [sysctl] section and remove the entire section if it is empty.
data: |
[main]
summary=Configuration changes profile inherited from performance created tuned
include=openshift-node-performance-openshift-node-performance-profile
[scheduler]
group.ice-ptp=0:f:10:*:ice-ptp.*
group.ice-gnss=0:f:10:*:ice-gnss.*
group.ice-dplls=0:f:10:*:ice-dplls.*
[service]
service.stalld=start,enable
service.chronyd=stop,disable
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "$mcp"
priority: 19
profile: performance-patchPtpConfigBoundaryForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
# The interface name is hardware-specific
[$iface_slave]
masterOnly 0
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 248
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 135
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "boundary"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigForHAForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary-ha
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary-ha"
ptp4lOpts: " "
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
haProfiles: "$profile1,$profile2"
recommend:
- profile: "boundary-ha"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigMasterForEvent.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigSlaveForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: du-ptp-slave
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "slave"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 -s --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "slave"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpOperatorConfigForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpOperatorConfig
metadata:
name: default
namespace: openshift-ptp
annotations: {}
spec:
daemonNodeSelector:
node-role.kubernetes.io/$mcp: ""
ptpEventConfig:
enableEventPublisher: true
transportHost: "http://ptp-event-publisher-service-NODE_NAME.openshift-ptp.svc.cluster.local:9043"PtpConfigBoundary.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary"
ptp4lOpts: "-2"
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
# The interface name is hardware-specific
[$iface_slave]
masterOnly 0
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 248
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 135
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "boundary"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigDualCardGmWpc.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
# In this example two cards $iface_nic1 and $iface_nic2 are connected via
# SMA1 ports by a cable and $iface_nic2 receives 1PPS signals from $iface_nic1
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: -r -u 0 -m -w -N 8 -R 16 -s $iface_nic1 -n 24
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
plugins:
e810:
enableDefaultConfig: false
settings:
LocalMaxHoldoverOffSet: 1500
LocalHoldoverTimeout: 14400
MaxInSpecOffset: 1500
pins: $e810_pins
# "$iface_nic1":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "2 1"
# "$iface_nic2":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "1 1"
ublxCmds:
- args: #ubxtool -P 29.20 -z CFG-HW-ANT_CFG_VOLTCTRL,1
- "-P"
- "29.20"
- "-z"
- "CFG-HW-ANT_CFG_VOLTCTRL,1"
reportOutput: false
- args: #ubxtool -P 29.20 -e GPS
- "-P"
- "29.20"
- "-e"
- "GPS"
reportOutput: false
- args: #ubxtool -P 29.20 -d Galileo
- "-P"
- "29.20"
- "-d"
- "Galileo"
reportOutput: false
- args: #ubxtool -P 29.20 -d GLONASS
- "-P"
- "29.20"
- "-d"
- "GLONASS"
reportOutput: false
- args: #ubxtool -P 29.20 -d BeiDou
- "-P"
- "29.20"
- "-d"
- "BeiDou"
reportOutput: false
- args: #ubxtool -P 29.20 -d SBAS
- "-P"
- "29.20"
- "-d"
- "SBAS"
reportOutput: false
- args: #ubxtool -P 29.20 -t -w 5 -v 1 -e SURVEYIN,600,50000
- "-P"
- "29.20"
- "-t"
- "-w"
- "5"
- "-v"
- "1"
- "-e"
- "SURVEYIN,600,50000"
reportOutput: true
- args: #ubxtool -P 29.20 -p MON-HW
- "-P"
- "29.20"
- "-p"
- "MON-HW"
reportOutput: true
- args: #ubxtool -P 29.20 -p CFG-MSG,1,38,300
- "-P"
- "29.20"
- "-p"
- "CFG-MSG,1,38,300"
reportOutput: true
ts2phcOpts: " "
ts2phcConf: |
[nmea]
ts2phc.master 1
[global]
use_syslog 0
verbose 1
logging_level 7
ts2phc.pulsewidth 100000000
#cat /dev/GNSS to find available serial port
#example value of gnss_serialport is /dev/ttyGNSS_1700_0
ts2phc.nmea_serialport $gnss_serialport
leapfile /usr/share/zoneinfo/leap-seconds.list
[$iface_nic1]
ts2phc.extts_polarity rising
ts2phc.extts_correction 0
[$iface_nic2]
ts2phc.master 0
ts2phc.extts_polarity rising
#this is a measured value in nanoseconds to compensate for SMA cable delay
ts2phc.extts_correction -10
ptp4lConf: |
[$iface_nic1]
masterOnly 1
[$iface_nic1_1]
masterOnly 1
[$iface_nic1_2]
masterOnly 1
[$iface_nic1_3]
masterOnly 1
[$iface_nic2]
masterOnly 1
[$iface_nic2_1]
masterOnly 1
[$iface_nic2_2]
masterOnly 1
[$iface_nic2_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 6
clockAccuracy 0x27
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval 0
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval -4
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 1
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0x20
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigThreeCardGmWpc.yaml
# In this example, the three cards are connected via SMA cables:
# - $iface_nic1 has the GNSS signal input
# - $iface_nic2 SMA1 is connected to $iface_nic1 SMA1
# - $iface_nic3 SMA1 is connected to $iface_nic1 SMA2
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations:
{}
spec:
profile:
- name: grandmaster
ptp4lOpts: -2 --summary_interval -4
phc2sysOpts: -r -u 0 -m -N 8 -R 16 -s $iface_nic1 -n 24
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
plugins:
e810:
enableDefaultConfig: false
settings:
LocalHoldoverTimeout: 14400
LocalMaxHoldoverOffSet: 1500
MaxInSpecOffset: 1500
pins:
# Syntax guide:
# - The 1st number in each pair must be one of:
# 0 - Disabled
# 1 - RX
# 2 - TX
# - The 2nd number in each pair must match the channel number
$iface_nic1:
SMA1: 2 1
SMA2: 2 2
U.FL1: 0 1
U.FL2: 0 2
$iface_nic2:
SMA1: 1 1
SMA2: 0 2
U.FL1: 0 1
U.FL2: 0 2
$iface_nic3:
SMA1: 1 1
SMA2: 0 2
U.FL1: 0 1
U.FL2: 0 2
ublxCmds:
- args: #ubxtool -P 29.20 -z CFG-HW-ANT_CFG_VOLTCTRL,1
- "-P"
- "29.20"
- "-z"
- "CFG-HW-ANT_CFG_VOLTCTRL,1"
reportOutput: false
- args: #ubxtool -P 29.20 -e GPS
- "-P"
- "29.20"
- "-e"
- "GPS"
reportOutput: false
- args: #ubxtool -P 29.20 -d Galileo
- "-P"
- "29.20"
- "-d"
- "Galileo"
reportOutput: false
- args: #ubxtool -P 29.20 -d GLONASS
- "-P"
- "29.20"
- "-d"
- "GLONASS"
reportOutput: false
- args: #ubxtool -P 29.20 -d BeiDou
- "-P"
- "29.20"
- "-d"
- "BeiDou"
reportOutput: false
- args: #ubxtool -P 29.20 -d SBAS
- "-P"
- "29.20"
- "-d"
- "SBAS"
reportOutput: false
- args: #ubxtool -P 29.20 -t -w 5 -v 1 -e SURVEYIN,600,50000
- "-P"
- "29.20"
- "-t"
- "-w"
- "5"
- "-v"
- "1"
- "-e"
- "SURVEYIN,600,50000"
reportOutput: true
- args: #ubxtool -P 29.20 -p MON-HW
- "-P"
- "29.20"
- "-p"
- "MON-HW"
reportOutput: true
- args: #ubxtool -P 29.20 -p CFG-MSG,1,38,248
- "-P"
- "29.20"
- "-p"
- "CFG-MSG,1,38,248"
reportOutput: true
ts2phcOpts: " "
ts2phcConf: |
[nmea]
ts2phc.master 1
[global]
use_syslog 0
verbose 1
logging_level 7
ts2phc.pulsewidth 100000000
#example value of nmea_serialport is /dev/gnss0
ts2phc.nmea_serialport (?<gnss_serialport>[/\w\s/]+)
leapfile /usr/share/zoneinfo/leap-seconds.list
[$iface_nic1]
ts2phc.extts_polarity rising
ts2phc.extts_correction 0
[$iface_nic2]
ts2phc.master 0
ts2phc.extts_polarity rising
#this is a measured value in nanoseconds to compensate for SMA cable delay
ts2phc.extts_correction -10
[$iface_nic3]
ts2phc.master 0
ts2phc.extts_polarity rising
#this is a measured value in nanoseconds to compensate for SMA cable delay
ts2phc.extts_correction -10
ptp4lConf: |
[$iface_nic1]
masterOnly 1
[$iface_nic1_1]
masterOnly 1
[$iface_nic1_2]
masterOnly 1
[$iface_nic1_3]
masterOnly 1
[$iface_nic2]
masterOnly 1
[$iface_nic2_1]
masterOnly 1
[$iface_nic2_2]
masterOnly 1
[$iface_nic2_3]
masterOnly 1
[$iface_nic3]
masterOnly 1
[$iface_nic3_1]
masterOnly 1
[$iface_nic3_2]
masterOnly 1
[$iface_nic3_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 6
clockAccuracy 0x27
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval 0
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval -4
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 1
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0x20
ptpClockThreshold:
holdOverTimeout: 5
maxOffsetThreshold: 100
minOffsetThreshold: -100
recommend:
- profile: grandmaster
priority: 4
match:
- nodeLabel: node-role.kubernetes.io/$mcpPtpConfigForHA.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary-ha
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary-ha"
ptp4lOpts: ""
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
haProfiles: "$profile1,$profile2"
recommend:
- profile: "boundary-ha"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigGmWpc.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: -r -u 0 -m -w -N 8 -R 16 -s $iface_master -n 24
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
plugins:
e810:
enableDefaultConfig: false
settings:
LocalMaxHoldoverOffSet: 1500
LocalHoldoverTimeout: 14400
MaxInSpecOffset: 1500
pins: $e810_pins
# "$iface_master":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "0 1"
ublxCmds:
- args: #ubxtool -P 29.20 -z CFG-HW-ANT_CFG_VOLTCTRL,1
- "-P"
- "29.20"
- "-z"
- "CFG-HW-ANT_CFG_VOLTCTRL,1"
reportOutput: false
- args: #ubxtool -P 29.20 -e GPS
- "-P"
- "29.20"
- "-e"
- "GPS"
reportOutput: false
- args: #ubxtool -P 29.20 -d Galileo
- "-P"
- "29.20"
- "-d"
- "Galileo"
reportOutput: false
- args: #ubxtool -P 29.20 -d GLONASS
- "-P"
- "29.20"
- "-d"
- "GLONASS"
reportOutput: false
- args: #ubxtool -P 29.20 -d BeiDou
- "-P"
- "29.20"
- "-d"
- "BeiDou"
reportOutput: false
- args: #ubxtool -P 29.20 -d SBAS
- "-P"
- "29.20"
- "-d"
- "SBAS"
reportOutput: false
- args: #ubxtool -P 29.20 -t -w 5 -v 1 -e SURVEYIN,600,50000
- "-P"
- "29.20"
- "-t"
- "-w"
- "5"
- "-v"
- "1"
- "-e"
- "SURVEYIN,600,50000"
reportOutput: true
- args: #ubxtool -P 29.20 -p MON-HW
- "-P"
- "29.20"
- "-p"
- "MON-HW"
reportOutput: true
- args: #ubxtool -P 29.20 -p CFG-MSG,1,38,300
- "-P"
- "29.20"
- "-p"
- "CFG-MSG,1,38,300"
reportOutput: true
ts2phcOpts: " "
ts2phcConf: |
[nmea]
ts2phc.master 1
[global]
use_syslog 0
verbose 1
logging_level 7
ts2phc.pulsewidth 100000000
#cat /dev/GNSS to find available serial port
#example value of gnss_serialport is /dev/ttyGNSS_1700_0
ts2phc.nmea_serialport $gnss_serialport
leapfile /usr/share/zoneinfo/leap-seconds.list
[$iface_master]
ts2phc.extts_polarity rising
ts2phc.extts_correction 0
ptp4lConf: |
[$iface_master]
masterOnly 1
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 6
clockAccuracy 0x27
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval 0
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval -4
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0x20
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigSlave.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: ordinary
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "ordinary"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 -s"
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "ordinary"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpOperatorConfig.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpOperatorConfig
metadata:
name: default
namespace: openshift-ptp
annotations: {}
spec:
daemonNodeSelector:
node-role.kubernetes.io/$mcp: ""PtpSubscription.yaml
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: ptp-operator-subscription
namespace: openshift-ptp
annotations: {}
spec:
channel: "stable"
name: ptp-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownPtpSubscriptionNS.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: openshift-ptp
annotations:
workload.openshift.io/allowed: management
labels:
openshift.io/cluster-monitoring: "true"PtpSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: ptp-operators
namespace: openshift-ptp
annotations: {}
spec:
targetNamespaces:
- openshift-ptpAcceleratorsNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: vran-acceleration-operators
annotations: {}AcceleratorsOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: vran-operators
namespace: vran-acceleration-operators
annotations: {}
spec:
targetNamespaces:
- vran-acceleration-operatorsAcceleratorsSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: sriov-fec-subscription
namespace: vran-acceleration-operators
annotations: {}
spec:
channel: stable
name: sriov-fec
source: certified-operators
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownSriovFecClusterConfig.yaml
apiVersion: sriovfec.intel.com/v2
kind: SriovFecClusterConfig
metadata:
name: config
namespace: vran-acceleration-operators
annotations: {}
spec:
drainSkip: $drainSkip # true if SNO, false by default
priority: 1
nodeSelector:
node-role.kubernetes.io/master: ""
acceleratorSelector:
pciAddress: $pciAddress
physicalFunction:
pfDriver: "vfio-pci"
vfDriver: "vfio-pci"
vfAmount: 16
bbDevConfig: $bbDevConfig
#Recommended configuration for Intel ACC100 (Mount Bryce) FPGA here: https://github.com/smart-edge-open/openshift-operator/blob/main/spec/openshift-sriov-fec-operator.md#sample-cr-for-wireless-fec-acc100
#Recommended configuration for Intel N3000 FPGA here: https://github.com/smart-edge-open/openshift-operator/blob/main/spec/openshift-sriov-fec-operator.md#sample-cr-for-wireless-fec-n3000SriovNetwork.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: ""
namespace: openshift-sriov-network-operator
annotations: {}
spec:
# resourceName: ""
networkNamespace: openshift-sriov-network-operator
# vlan: ""
# spoofChk: ""
# ipam: ""
# linkState: ""
# maxTxRate: ""
# minTxRate: ""
# vlanQoS: ""
# trust: ""
# capabilities: ""SriovNetworkNodePolicy.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: $name
namespace: openshift-sriov-network-operator
annotations: {}
spec:
# The attributes for Mellanox/Intel based NICs as below.
# deviceType: netdevice/vfio-pci
# isRdma: true/false
deviceType: $deviceType
isRdma: $isRdma
nicSelector:
# The exact physical function name must match the hardware used
pfNames: [$pfNames]
nodeSelector:
node-role.kubernetes.io/$mcp: ""
numVfs: $numVfs
priority: $priority
resourceName: $resourceNameSriovOperatorConfig.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovOperatorConfig
metadata:
name: default
namespace: openshift-sriov-network-operator
annotations: {}
spec:
configDaemonNodeSelector:
"node-role.kubernetes.io/$mcp": ""
# Injector and OperatorWebhook pods can be disabled (set to "false") below
# to reduce the number of management pods. It is recommended to start with the
# webhook and injector pods enabled, and only disable them after verifying the
# correctness of user manifests.
# If the injector is disabled, containers using sr-iov resources must explicitly assign
# them in the "requests"/"limits" section of the container spec, for example:
# containers:
# - name: my-sriov-workload-container
# resources:
# limits:
# openshift.io/<resource_name>: "1"
# requests:
# openshift.io/<resource_name>: "1"
enableInjector: false
enableOperatorWebhook: false
logLevel: 0SriovOperatorConfigForSNO.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovOperatorConfig
metadata:
name: default
namespace: openshift-sriov-network-operator
annotations: {}
spec:
configDaemonNodeSelector:
"node-role.kubernetes.io/$mcp": ""
# Injector and OperatorWebhook pods can be disabled (set to "false") below
# to reduce the number of management pods. It is recommended to start with the
# webhook and injector pods enabled, and only disable them after verifying the
# correctness of user manifests.
# If the injector is disabled, containers using sr-iov resources must explicitly assign
# them in the "requests"/"limits" section of the container spec, for example:
# containers:
# - name: my-sriov-workload-container
# resources:
# limits:
# openshift.io/<resource_name>: "1"
# requests:
# openshift.io/<resource_name>: "1"
enableInjector: false
enableOperatorWebhook: false
# Disable drain is needed for Single Node Openshift
disableDrain: true
logLevel: 0SriovSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: sriov-network-operator-subscription
namespace: openshift-sriov-network-operator
annotations: {}
spec:
channel: "stable"
name: sriov-network-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownSriovSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-sriov-network-operator
annotations:
workload.openshift.io/allowed: managementSriovSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: sriov-network-operators
namespace: openshift-sriov-network-operator
annotations: {}
spec:
targetNamespaces:
- openshift-sriov-network-operator3.2.4.4.2. クラスターチューニング参照 YAML
example-sno.yaml
# example-node1-bmh-secret & assisted-deployment-pull-secret need to be created under same namespace example-sno
---
apiVersion: ran.openshift.io/v1
kind: SiteConfig
metadata:
name: "example-sno"
namespace: "example-sno"
spec:
baseDomain: "example.com"
pullSecretRef:
name: "assisted-deployment-pull-secret"
clusterImageSetNameRef: "openshift-4.16"
sshPublicKey: "ssh-rsa AAAA..."
clusters:
- clusterName: "example-sno"
networkType: "OVNKubernetes"
# installConfigOverrides is a generic way of passing install-config
# parameters through the siteConfig. The 'capabilities' field configures
# the composable openshift feature. In this 'capabilities' setting, we
# remove all the optional set of components.
# Notes:
# - OperatorLifecycleManager is needed for 4.15 and later
# - NodeTuning is needed for 4.13 and later, not for 4.12 and earlier
# - Ingress is needed for 4.16 and later
installConfigOverrides: |
{
"capabilities": {
"baselineCapabilitySet": "None",
"additionalEnabledCapabilities": [
"NodeTuning",
"OperatorLifecycleManager",
"Ingress"
]
}
}
# It is strongly recommended to include crun manifests as part of the additional install-time manifests for 4.13+.
# The crun manifests can be obtained from source-crs/optional-extra-manifest/ and added to the git repo ie.sno-extra-manifest.
# extraManifestPath: sno-extra-manifest
clusterLabels:
# These example cluster labels correspond to the bindingRules in the PolicyGenTemplate examples
du-profile: "latest"
# These example cluster labels correspond to the bindingRules in the PolicyGenTemplate examples in ../policygentemplates:
# ../policygentemplates/common-ranGen.yaml will apply to all clusters with 'common: true'
common: true
# ../policygentemplates/group-du-sno-ranGen.yaml will apply to all clusters with 'group-du-sno: ""'
group-du-sno: ""
# ../policygentemplates/example-sno-site.yaml will apply to all clusters with 'sites: "example-sno"'
# Normally this should match or contain the cluster name so it only applies to a single cluster
sites: "example-sno"
clusterNetwork:
- cidr: 1001:1::/48
hostPrefix: 64
machineNetwork:
- cidr: 1111:2222:3333:4444::/64
serviceNetwork:
- 1001:2::/112
additionalNTPSources:
- 1111:2222:3333:4444::2
# Initiates the cluster for workload partitioning. Setting specific reserved/isolated CPUSets is done via PolicyTemplate
# please see Workload Partitioning Feature for a complete guide.
cpuPartitioningMode: AllNodes
# Optionally; This can be used to override the KlusterletAddonConfig that is created for this cluster:
#crTemplates:
# KlusterletAddonConfig: "KlusterletAddonConfigOverride.yaml"
nodes:
- hostName: "example-node1.example.com"
role: "master"
# Optionally; This can be used to configure desired BIOS setting on a host:
#biosConfigRef:
# filePath: "example-hw.profile"
bmcAddress: "idrac-virtualmedia+https://[1111:2222:3333:4444::bbbb:1]/redfish/v1/Systems/System.Embedded.1"
bmcCredentialsName:
name: "example-node1-bmh-secret"
bootMACAddress: "AA:BB:CC:DD:EE:11"
# Use UEFISecureBoot to enable secure boot
bootMode: "UEFI"
rootDeviceHints:
deviceName: "/dev/disk/by-path/pci-0000:01:00.0-scsi-0:2:0:0"
# disk partition at `/var/lib/containers` with ignitionConfigOverride. Some values must be updated. See DiskPartitionContainer.md for more details
ignitionConfigOverride: |
{
"ignition": {
"version": "3.2.0"
},
"storage": {
"disks": [
{
"device": "/dev/disk/by-id/wwn-0x6b07b250ebb9d0002a33509f24af1f62",
"partitions": [
{
"label": "var-lib-containers",
"sizeMiB": 0,
"startMiB": 250000
}
],
"wipeTable": false
}
],
"filesystems": [
{
"device": "/dev/disk/by-partlabel/var-lib-containers",
"format": "xfs",
"mountOptions": [
"defaults",
"prjquota"
],
"path": "/var/lib/containers",
"wipeFilesystem": true
}
]
},
"systemd": {
"units": [
{
"contents": "# Generated by Butane\n[Unit]\nRequires=systemd-fsck@dev-disk-by\\x2dpartlabel-var\\x2dlib\\x2dcontainers.service\nAfter=systemd-fsck@dev-disk-by\\x2dpartlabel-var\\x2dlib\\x2dcontainers.service\n\n[Mount]\nWhere=/var/lib/containers\nWhat=/dev/disk/by-partlabel/var-lib-containers\nType=xfs\nOptions=defaults,prjquota\n\n[Install]\nRequiredBy=local-fs.target",
"enabled": true,
"name": "var-lib-containers.mount"
}
]
}
}
nodeNetwork:
interfaces:
- name: eno1
macAddress: "AA:BB:CC:DD:EE:11"
config:
interfaces:
- name: eno1
type: ethernet
state: up
ipv4:
enabled: false
ipv6:
enabled: true
address:
# For SNO sites with static IP addresses, the node-specific,
# API and Ingress IPs should all be the same and configured on
# the interface
- ip: 1111:2222:3333:4444::aaaa:1
prefix-length: 64
dns-resolver:
config:
search:
- example.com
server:
- 1111:2222:3333:4444::2
routes:
config:
- destination: ::/0
next-hop-interface: eno1
next-hop-address: 1111:2222:3333:4444::1
table-id: 254DisableSnoNetworkDiag.yaml
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
annotations: {}
spec:
disableNetworkDiagnostics: trueReduceMonitoringFootprint.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
annotations: {}
data:
config.yaml: |
alertmanagerMain:
enabled: false
telemeterClient:
enabled: false
prometheusK8s:
retention: 24h09-openshift-marketplace-ns.yaml
# Taken from https://github.com/operator-framework/operator-marketplace/blob/53c124a3f0edfd151652e1f23c87dd39ed7646bb/manifests/01_namespace.yaml
# Update it as the source evolves.
apiVersion: v1
kind: Namespace
metadata:
annotations:
openshift.io/node-selector: ""
workload.openshift.io/allowed: "management"
labels:
openshift.io/cluster-monitoring: "true"
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: v1.25
pod-security.kubernetes.io/audit: baseline
pod-security.kubernetes.io/audit-version: v1.25
pod-security.kubernetes.io/warn: baseline
pod-security.kubernetes.io/warn-version: v1.25
name: "openshift-marketplace"DefaultCatsrc.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: default-cat-source
namespace: openshift-marketplace
annotations:
target.workload.openshift.io/management: '{"effect": "PreferredDuringScheduling"}'
spec:
displayName: default-cat-source
image: $imageUrl
publisher: Red Hat
sourceType: grpc
updateStrategy:
registryPoll:
interval: 1h
status:
connectionState:
lastObservedState: READYDisableOLMPprof.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: collect-profiles-config
namespace: openshift-operator-lifecycle-manager
annotations: {}
data:
pprof-config.yaml: |
disabled: TrueDisconnectedICSP.yaml
apiVersion: operator.openshift.io/v1alpha1
kind: ImageContentSourcePolicy
metadata:
name: disconnected-internal-icsp
annotations: {}
spec:
# repositoryDigestMirrors:
# - $mirrorsOperatorHub.yaml
apiVersion: config.openshift.io/v1
kind: OperatorHub
metadata:
name: cluster
annotations: {}
spec:
disableAllDefaultSources: true3.2.4.4.3. マシン設定参照 YAML
enable-crun-master.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: enable-crun-master
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/master: ""
containerRuntimeConfig:
defaultRuntime: crunenable-crun-worker.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: enable-crun-worker
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ""
containerRuntimeConfig:
defaultRuntime: crun99-crio-disable-wipe-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 99-crio-disable-wipe-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,W2NyaW9dCmNsZWFuX3NodXRkb3duX2ZpbGUgPSAiIgo=
mode: 420
path: /etc/crio/crio.conf.d/99-crio-disable-wipe.toml99-crio-disable-wipe-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 99-crio-disable-wipe-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,W2NyaW9dCmNsZWFuX3NodXRkb3duX2ZpbGUgPSAiIgo=
mode: 420
path: /etc/crio/crio.conf.d/99-crio-disable-wipe.toml06-kdump-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 06-kdump-enable-master
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- enabled: true
name: kdump.service
kernelArguments:
- crashkernel=512M06-kdump-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 06-kdump-enable-worker
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- enabled: true
name: kdump.service
kernelArguments:
- crashkernel=512M01-container-mount-ns-and-kubelet-conf-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: container-mount-namespace-and-kubelet-conf-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service01-container-mount-ns-and-kubelet-conf-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: container-mount-namespace-and-kubelet-conf-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service99-sync-time-once-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 99-sync-time-once-master
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- contents: |
[Unit]
Description=Sync time once
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
TimeoutStartSec=300
ExecCondition=/bin/bash -c 'systemctl is-enabled chronyd.service --quiet && exit 1 || exit 0'
ExecStart=/usr/sbin/chronyd -n -f /etc/chrony.conf -q
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
enabled: true
name: sync-time-once.service99-sync-time-once-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 99-sync-time-once-worker
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- contents: |
[Unit]
Description=Sync time once
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
TimeoutStartSec=300
ExecCondition=/bin/bash -c 'systemctl is-enabled chronyd.service --quiet && exit 1 || exit 0'
ExecStart=/usr/sbin/chronyd -n -f /etc/chrony.conf -q
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
enabled: true
name: sync-time-once.service03-sctp-machine-config-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: load-sctp-module-master
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,
verification: {}
filesystem: root
mode: 420
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
filesystem: root
mode: 420
path: /etc/modules-load.d/sctp-load.conf03-sctp-machine-config-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: load-sctp-module-worker
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,
verification: {}
filesystem: root
mode: 420
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
filesystem: root
mode: 420
path: /etc/modules-load.d/sctp-load.conf08-set-rcu-normal-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 08-set-rcu-normal-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKIwojIERpc2FibGUgcmN1X2V4cGVkaXRlZCBhZnRlciBub2RlIGhhcyBmaW5pc2hlZCBib290aW5nCiMKIyBUaGUgZGVmYXVsdHMgYmVsb3cgY2FuIGJlIG92ZXJyaWRkZW4gdmlhIGVudmlyb25tZW50IHZhcmlhYmxlcwojCgojIERlZmF1bHQgd2FpdCB0aW1lIGlzIDYwMHMgPSAxMG06Ck1BWElNVU1fV0FJVF9USU1FPSR7TUFYSU1VTV9XQUlUX1RJTUU6LTYwMH0KCiMgRGVmYXVsdCBzdGVhZHktc3RhdGUgdGhyZXNob2xkID0gMiUKIyBBbGxvd2VkIHZhbHVlczoKIyAgNCAgLSBhYnNvbHV0ZSBwb2QgY291bnQgKCsvLSkKIyAgNCUgLSBwZXJjZW50IGNoYW5nZSAoKy8tKQojICAtMSAtIGRpc2FibGUgdGhlIHN0ZWFkeS1zdGF0ZSBjaGVjawpTVEVBRFlfU1RBVEVfVEhSRVNIT0xEPSR7U1RFQURZX1NUQVRFX1RIUkVTSE9MRDotMiV9CgojIERlZmF1bHQgc3RlYWR5LXN0YXRlIHdpbmRvdyA9IDYwcwojIElmIHRoZSBydW5uaW5nIHBvZCBjb3VudCBzdGF5cyB3aXRoaW4gdGhlIGdpdmVuIHRocmVzaG9sZCBmb3IgdGhpcyB0aW1lCiMgcGVyaW9kLCByZXR1cm4gQ1BVIHV0aWxpemF0aW9uIHRvIG5vcm1hbCBiZWZvcmUgdGhlIG1heGltdW0gd2FpdCB0aW1lIGhhcwojIGV4cGlyZXMKU1RFQURZX1NUQVRFX1dJTkRPVz0ke1NURUFEWV9TVEFURV9XSU5ET1c6LTYwfQoKIyBEZWZhdWx0IHN0ZWFkeS1zdGF0ZSBhbGxvd3MgYW55IHBvZCBjb3VudCB0byBiZSAic3RlYWR5IHN0YXRlIgojIEluY3JlYXNpbmcgdGhpcyB3aWxsIHNraXAgYW55IHN0ZWFkeS1zdGF0ZSBjaGVja3MgdW50aWwgdGhlIGNvdW50IHJpc2VzIGFib3ZlCiMgdGhpcyBudW1iZXIgdG8gYXZvaWQgZmFsc2UgcG9zaXRpdmVzIGlmIHRoZXJlIGFyZSBzb21lIHBlcmlvZHMgd2hlcmUgdGhlCiMgY291bnQgZG9lc24ndCBpbmNyZWFzZSBidXQgd2Uga25vdyB3ZSBjYW4ndCBiZSBhdCBzdGVhZHktc3RhdGUgeWV0LgpTVEVBRFlfU1RBVEVfTUlOSU1VTT0ke1NURUFEWV9TVEFURV9NSU5JTVVNOi0wfQoKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKd2l0aGluKCkgewogIGxvY2FsIGxhc3Q9JDEgY3VycmVudD0kMiB0aHJlc2hvbGQ9JDMKICBsb2NhbCBkZWx0YT0wIHBjaGFuZ2UKICBkZWx0YT0kKCggY3VycmVudCAtIGxhc3QgKSkKICBpZiBbWyAkY3VycmVudCAtZXEgJGxhc3QgXV07IHRoZW4KICAgIHBjaGFuZ2U9MAogIGVsaWYgW1sgJGxhc3QgLWVxIDAgXV07IHRoZW4KICAgIHBjaGFuZ2U9MTAwMDAwMAogIGVsc2UKICAgIHBjaGFuZ2U9JCgoICggIiRkZWx0YSIgKiAxMDApIC8gbGFzdCApKQogIGZpCiAgZWNobyAtbiAibGFzdDokbGFzdCBjdXJyZW50OiRjdXJyZW50IGRlbHRhOiRkZWx0YSBwY2hhbmdlOiR7cGNoYW5nZX0lOiAiCiAgbG9jYWwgYWJzb2x1dGUgbGltaXQKICBjYXNlICR0aHJlc2hvbGQgaW4KICAgIColKQogICAgICBhYnNvbHV0ZT0ke3BjaGFuZ2UjIy19ICMgYWJzb2x1dGUgdmFsdWUKICAgICAgbGltaXQ9JHt0aHJlc2hvbGQlJSV9CiAgICAgIDs7CiAgICAqKQogICAgICBhYnNvbHV0ZT0ke2RlbHRhIyMtfSAjIGFic29sdXRlIHZhbHVlCiAgICAgIGxpbWl0PSR0aHJlc2hvbGQKICAgICAgOzsKICBlc2FjCiAgaWYgW1sgJGFic29sdXRlIC1sZSAkbGltaXQgXV07IHRoZW4KICAgIGVjaG8gIndpdGhpbiAoKy8tKSR0aHJlc2hvbGQiCiAgICByZXR1cm4gMAogIGVsc2UKICAgIGVjaG8gIm91dHNpZGUgKCsvLSkkdGhyZXNob2xkIgogICAgcmV0dXJuIDEKICBmaQp9CgpzdGVhZHlzdGF0ZSgpIHsKICBsb2NhbCBsYXN0PSQxIGN1cnJlbnQ9JDIKICBpZiBbWyAkbGFzdCAtbHQgJFNURUFEWV9TVEFURV9NSU5JTVVNIF1dOyB0aGVuCiAgICBlY2hvICJsYXN0OiRsYXN0IGN1cnJlbnQ6JGN1cnJlbnQgV2FpdGluZyB0byByZWFjaCAkU1RFQURZX1NUQVRFX01JTklNVU0gYmVmb3JlIGNoZWNraW5nIGZvciBzdGVhZHktc3RhdGUiCiAgICByZXR1cm4gMQogIGZpCiAgd2l0aGluICIkbGFzdCIgIiRjdXJyZW50IiAiJFNURUFEWV9TVEFURV9USFJFU0hPTEQiCn0KCndhaXRGb3JSZWFkeSgpIHsKICBsb2dnZXIgIlJlY292ZXJ5OiBXYWl0aW5nICR7TUFYSU1VTV9XQUlUX1RJTUV9cyBmb3IgdGhlIGluaXRpYWxpemF0aW9uIHRvIGNvbXBsZXRlIgogIGxvY2FsIHQ9MCBzPTEwCiAgbG9jYWwgbGFzdENjb3VudD0wIGNjb3VudD0wIHN0ZWFkeVN0YXRlVGltZT0wCiAgd2hpbGUgW1sgJHQgLWx0ICRNQVhJTVVNX1dBSVRfVElNRSBdXTsgZG8KICAgIHNsZWVwICRzCiAgICAoKHQgKz0gcykpCiAgICAjIERldGVjdCBzdGVhZHktc3RhdGUgcG9kIGNvdW50CiAgICBjY291bnQ9JChjcmljdGwgcHMgMj4vZGV2L251bGwgfCB3YyAtbCkKICAgIGlmIFtbICRjY291bnQgLWd0IDAgXV0gJiYgc3RlYWR5c3RhdGUgIiRsYXN0Q2NvdW50IiAiJGNjb3VudCI7IHRoZW4KICAgICAgKChzdGVhZHlTdGF0ZVRpbWUgKz0gcykpCiAgICAgIGVjaG8gIlN0ZWFkeS1zdGF0ZSBmb3IgJHtzdGVhZHlTdGF0ZVRpbWV9cy8ke1NURUFEWV9TVEFURV9XSU5ET1d9cyIKICAgICAgaWYgW1sgJHN0ZWFkeVN0YXRlVGltZSAtZ2UgJFNURUFEWV9TVEFURV9XSU5ET1cgXV07IHRoZW4KICAgICAgICBsb2dnZXIgIlJlY292ZXJ5OiBTdGVhZHktc3RhdGUgKCsvLSAkU1RFQURZX1NUQVRFX1RIUkVTSE9MRCkgZm9yICR7U1RFQURZX1NUQVRFX1dJTkRPV31zOiBEb25lIgogICAgICAgIHJldHVybiAwCiAgICAgIGZpCiAgICBlbHNlCiAgICAgIGlmIFtbICRzdGVhZHlTdGF0ZVRpbWUgLWd0IDAgXV07IHRoZW4KICAgICAgICBlY2hvICJSZXNldHRpbmcgc3RlYWR5LXN0YXRlIHRpbWVyIgogICAgICAgIHN0ZWFkeVN0YXRlVGltZT0wCiAgICAgIGZpCiAgICBmaQogICAgbGFzdENjb3VudD0kY2NvdW50CiAgZG9uZQogIGxvZ2dlciAiUmVjb3Zlcnk6IFJlY292ZXJ5IENvbXBsZXRlIFRpbWVvdXQiCn0KCnNldFJjdU5vcm1hbCgpIHsKICBlY2hvICJTZXR0aW5nIHJjdV9ub3JtYWwgdG8gMSIKICBlY2hvIDEgPiAvc3lzL2tlcm5lbC9yY3Vfbm9ybWFsCn0KCm1haW4oKSB7CiAgd2FpdEZvclJlYWR5CiAgZWNobyAiV2FpdGluZyBmb3Igc3RlYWR5IHN0YXRlIHRvb2s6ICQoYXdrICd7cHJpbnQgaW50KCQxLzM2MDApImgiLCBpbnQoKCQxJTM2MDApLzYwKSJtIiwgaW50KCQxJTYwKSJzIn0nIC9wcm9jL3VwdGltZSkiCiAgc2V0UmN1Tm9ybWFsCn0KCmlmIFtbICIke0JBU0hfU09VUkNFWzBdfSIgPSAiJHswfSIgXV07IHRoZW4KICBtYWluICIke0B9IgogIGV4aXQgJD8KZmkK
mode: 493
path: /usr/local/bin/set-rcu-normal.sh
systemd:
units:
- contents: |
[Unit]
Description=Disable rcu_expedited after node has finished booting by setting rcu_normal to 1
[Service]
Type=simple
ExecStart=/usr/local/bin/set-rcu-normal.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold = 2%
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=2%%
# Steady-state window = 120s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=120
# Steady-state minimum = 40
# Increasing this will skip any steady-state checks until the count rises above
# this number to avoid false positives if there are some periods where the
# count doesn't increase but we know we can't be at steady-state yet.
Environment=STEADY_STATE_MINIMUM=40
[Install]
WantedBy=multi-user.target
enabled: true
name: set-rcu-normal.service08-set-rcu-normal-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 08-set-rcu-normal-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKIwojIERpc2FibGUgcmN1X2V4cGVkaXRlZCBhZnRlciBub2RlIGhhcyBmaW5pc2hlZCBib290aW5nCiMKIyBUaGUgZGVmYXVsdHMgYmVsb3cgY2FuIGJlIG92ZXJyaWRkZW4gdmlhIGVudmlyb25tZW50IHZhcmlhYmxlcwojCgojIERlZmF1bHQgd2FpdCB0aW1lIGlzIDYwMHMgPSAxMG06Ck1BWElNVU1fV0FJVF9USU1FPSR7TUFYSU1VTV9XQUlUX1RJTUU6LTYwMH0KCiMgRGVmYXVsdCBzdGVhZHktc3RhdGUgdGhyZXNob2xkID0gMiUKIyBBbGxvd2VkIHZhbHVlczoKIyAgNCAgLSBhYnNvbHV0ZSBwb2QgY291bnQgKCsvLSkKIyAgNCUgLSBwZXJjZW50IGNoYW5nZSAoKy8tKQojICAtMSAtIGRpc2FibGUgdGhlIHN0ZWFkeS1zdGF0ZSBjaGVjawpTVEVBRFlfU1RBVEVfVEhSRVNIT0xEPSR7U1RFQURZX1NUQVRFX1RIUkVTSE9MRDotMiV9CgojIERlZmF1bHQgc3RlYWR5LXN0YXRlIHdpbmRvdyA9IDYwcwojIElmIHRoZSBydW5uaW5nIHBvZCBjb3VudCBzdGF5cyB3aXRoaW4gdGhlIGdpdmVuIHRocmVzaG9sZCBmb3IgdGhpcyB0aW1lCiMgcGVyaW9kLCByZXR1cm4gQ1BVIHV0aWxpemF0aW9uIHRvIG5vcm1hbCBiZWZvcmUgdGhlIG1heGltdW0gd2FpdCB0aW1lIGhhcwojIGV4cGlyZXMKU1RFQURZX1NUQVRFX1dJTkRPVz0ke1NURUFEWV9TVEFURV9XSU5ET1c6LTYwfQoKIyBEZWZhdWx0IHN0ZWFkeS1zdGF0ZSBhbGxvd3MgYW55IHBvZCBjb3VudCB0byBiZSAic3RlYWR5IHN0YXRlIgojIEluY3JlYXNpbmcgdGhpcyB3aWxsIHNraXAgYW55IHN0ZWFkeS1zdGF0ZSBjaGVja3MgdW50aWwgdGhlIGNvdW50IHJpc2VzIGFib3ZlCiMgdGhpcyBudW1iZXIgdG8gYXZvaWQgZmFsc2UgcG9zaXRpdmVzIGlmIHRoZXJlIGFyZSBzb21lIHBlcmlvZHMgd2hlcmUgdGhlCiMgY291bnQgZG9lc24ndCBpbmNyZWFzZSBidXQgd2Uga25vdyB3ZSBjYW4ndCBiZSBhdCBzdGVhZHktc3RhdGUgeWV0LgpTVEVBRFlfU1RBVEVfTUlOSU1VTT0ke1NURUFEWV9TVEFURV9NSU5JTVVNOi0wfQoKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKd2l0aGluKCkgewogIGxvY2FsIGxhc3Q9JDEgY3VycmVudD0kMiB0aHJlc2hvbGQ9JDMKICBsb2NhbCBkZWx0YT0wIHBjaGFuZ2UKICBkZWx0YT0kKCggY3VycmVudCAtIGxhc3QgKSkKICBpZiBbWyAkY3VycmVudCAtZXEgJGxhc3QgXV07IHRoZW4KICAgIHBjaGFuZ2U9MAogIGVsaWYgW1sgJGxhc3QgLWVxIDAgXV07IHRoZW4KICAgIHBjaGFuZ2U9MTAwMDAwMAogIGVsc2UKICAgIHBjaGFuZ2U9JCgoICggIiRkZWx0YSIgKiAxMDApIC8gbGFzdCApKQogIGZpCiAgZWNobyAtbiAibGFzdDokbGFzdCBjdXJyZW50OiRjdXJyZW50IGRlbHRhOiRkZWx0YSBwY2hhbmdlOiR7cGNoYW5nZX0lOiAiCiAgbG9jYWwgYWJzb2x1dGUgbGltaXQKICBjYXNlICR0aHJlc2hvbGQgaW4KICAgIColKQogICAgICBhYnNvbHV0ZT0ke3BjaGFuZ2UjIy19ICMgYWJzb2x1dGUgdmFsdWUKICAgICAgbGltaXQ9JHt0aHJlc2hvbGQlJSV9CiAgICAgIDs7CiAgICAqKQogICAgICBhYnNvbHV0ZT0ke2RlbHRhIyMtfSAjIGFic29sdXRlIHZhbHVlCiAgICAgIGxpbWl0PSR0aHJlc2hvbGQKICAgICAgOzsKICBlc2FjCiAgaWYgW1sgJGFic29sdXRlIC1sZSAkbGltaXQgXV07IHRoZW4KICAgIGVjaG8gIndpdGhpbiAoKy8tKSR0aHJlc2hvbGQiCiAgICByZXR1cm4gMAogIGVsc2UKICAgIGVjaG8gIm91dHNpZGUgKCsvLSkkdGhyZXNob2xkIgogICAgcmV0dXJuIDEKICBmaQp9CgpzdGVhZHlzdGF0ZSgpIHsKICBsb2NhbCBsYXN0PSQxIGN1cnJlbnQ9JDIKICBpZiBbWyAkbGFzdCAtbHQgJFNURUFEWV9TVEFURV9NSU5JTVVNIF1dOyB0aGVuCiAgICBlY2hvICJsYXN0OiRsYXN0IGN1cnJlbnQ6JGN1cnJlbnQgV2FpdGluZyB0byByZWFjaCAkU1RFQURZX1NUQVRFX01JTklNVU0gYmVmb3JlIGNoZWNraW5nIGZvciBzdGVhZHktc3RhdGUiCiAgICByZXR1cm4gMQogIGZpCiAgd2l0aGluICIkbGFzdCIgIiRjdXJyZW50IiAiJFNURUFEWV9TVEFURV9USFJFU0hPTEQiCn0KCndhaXRGb3JSZWFkeSgpIHsKICBsb2dnZXIgIlJlY292ZXJ5OiBXYWl0aW5nICR7TUFYSU1VTV9XQUlUX1RJTUV9cyBmb3IgdGhlIGluaXRpYWxpemF0aW9uIHRvIGNvbXBsZXRlIgogIGxvY2FsIHQ9MCBzPTEwCiAgbG9jYWwgbGFzdENjb3VudD0wIGNjb3VudD0wIHN0ZWFkeVN0YXRlVGltZT0wCiAgd2hpbGUgW1sgJHQgLWx0ICRNQVhJTVVNX1dBSVRfVElNRSBdXTsgZG8KICAgIHNsZWVwICRzCiAgICAoKHQgKz0gcykpCiAgICAjIERldGVjdCBzdGVhZHktc3RhdGUgcG9kIGNvdW50CiAgICBjY291bnQ9JChjcmljdGwgcHMgMj4vZGV2L251bGwgfCB3YyAtbCkKICAgIGlmIFtbICRjY291bnQgLWd0IDAgXV0gJiYgc3RlYWR5c3RhdGUgIiRsYXN0Q2NvdW50IiAiJGNjb3VudCI7IHRoZW4KICAgICAgKChzdGVhZHlTdGF0ZVRpbWUgKz0gcykpCiAgICAgIGVjaG8gIlN0ZWFkeS1zdGF0ZSBmb3IgJHtzdGVhZHlTdGF0ZVRpbWV9cy8ke1NURUFEWV9TVEFURV9XSU5ET1d9cyIKICAgICAgaWYgW1sgJHN0ZWFkeVN0YXRlVGltZSAtZ2UgJFNURUFEWV9TVEFURV9XSU5ET1cgXV07IHRoZW4KICAgICAgICBsb2dnZXIgIlJlY292ZXJ5OiBTdGVhZHktc3RhdGUgKCsvLSAkU1RFQURZX1NUQVRFX1RIUkVTSE9MRCkgZm9yICR7U1RFQURZX1NUQVRFX1dJTkRPV31zOiBEb25lIgogICAgICAgIHJldHVybiAwCiAgICAgIGZpCiAgICBlbHNlCiAgICAgIGlmIFtbICRzdGVhZHlTdGF0ZVRpbWUgLWd0IDAgXV07IHRoZW4KICAgICAgICBlY2hvICJSZXNldHRpbmcgc3RlYWR5LXN0YXRlIHRpbWVyIgogICAgICAgIHN0ZWFkeVN0YXRlVGltZT0wCiAgICAgIGZpCiAgICBmaQogICAgbGFzdENjb3VudD0kY2NvdW50CiAgZG9uZQogIGxvZ2dlciAiUmVjb3Zlcnk6IFJlY292ZXJ5IENvbXBsZXRlIFRpbWVvdXQiCn0KCnNldFJjdU5vcm1hbCgpIHsKICBlY2hvICJTZXR0aW5nIHJjdV9ub3JtYWwgdG8gMSIKICBlY2hvIDEgPiAvc3lzL2tlcm5lbC9yY3Vfbm9ybWFsCn0KCm1haW4oKSB7CiAgd2FpdEZvclJlYWR5CiAgZWNobyAiV2FpdGluZyBmb3Igc3RlYWR5IHN0YXRlIHRvb2s6ICQoYXdrICd7cHJpbnQgaW50KCQxLzM2MDApImgiLCBpbnQoKCQxJTM2MDApLzYwKSJtIiwgaW50KCQxJTYwKSJzIn0nIC9wcm9jL3VwdGltZSkiCiAgc2V0UmN1Tm9ybWFsCn0KCmlmIFtbICIke0JBU0hfU09VUkNFWzBdfSIgPSAiJHswfSIgXV07IHRoZW4KICBtYWluICIke0B9IgogIGV4aXQgJD8KZmkK
mode: 493
path: /usr/local/bin/set-rcu-normal.sh
systemd:
units:
- contents: |
[Unit]
Description=Disable rcu_expedited after node has finished booting by setting rcu_normal to 1
[Service]
Type=simple
ExecStart=/usr/local/bin/set-rcu-normal.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold = 2%
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=2%%
# Steady-state window = 120s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=120
# Steady-state minimum = 40
# Increasing this will skip any steady-state checks until the count rises above
# this number to avoid false positives if there are some periods where the
# count doesn't increase but we know we can't be at steady-state yet.
Environment=STEADY_STATE_MINIMUM=40
[Install]
WantedBy=multi-user.target
enabled: true
name: set-rcu-normal.service3.2.5. 通信事業者向け RAN DU 参照設定ソフトウェア仕様
以下の情報は、通信事業者向け RAN DU 参照デザイン仕様 (RDS) 検証済みソフトウェアバージョンを説明しています。
3.2.5.1. Telco RAN DU 4.16 の検証済みソフトウェアコンポーネント
Red Hat telco RAN DU 4.16 ソリューションは、次に示す OpenShift Container Platform のマネージドクラスターおよびハブクラスター用の Red Hat ソフトウェア製品を使用して検証されています。
| コンポーネント | ソフトウェアバージョン |
|---|---|
| マネージドクラスターのバージョン | 4.16 |
| Cluster Logging Operator | 6.0 |
| Local Storage Operator | 4.16 |
| PTP Operator | 4.16 |
| SRIOV Operator | 4.16 |
| Node Tuning Operator | 4.16 |
| Logging Operator | 4.16 |
| SRIOV-FEC Operator | 2.9 |
| コンポーネント | ソフトウェアバージョン |
|---|---|
| ハブクラスターのバージョン | 4.16 |
| GitOps ZTP プラグイン | 4.16 |
| Red Hat Advanced Cluster Management (RHACM) | 2.10, 2.11 |
| Red Hat OpenShift GitOps | 1.16 |
| Topology Aware Lifecycle Manager (TALM) | 4.16 |