Chapter 5. Networking
5.1. Networking
5.1.1. Overview
Kubernetes ensures that pods are able to network with each other, and allocates each pod an IP address from an internal network. This ensures all containers within the pod behave as if they were on the same host. Giving each pod its own IP address means that pods can be treated like physical hosts or virtual machines in terms of port allocation, networking, naming, service discovery, load balancing, application configuration, and migration.
Creating links between pods is unnecessary, and it is not recommended that your pods talk to one another directly using the IP address. Instead, it is recommended that you create a service, then interact with the service.
5.1.2. OpenShift Container Platform DNS
If you are running multiple services, such as frontend and backend services for use with multiple pods, in order for the frontend pods to communicate with the backend services, environment variables are created for user names, service IPs, and more. If the service is deleted and recreated, a new IP address can be assigned to the service, and requires the frontend pods to be recreated in order to pick up the updated values for the service IP environment variable. Additionally, the backend service has to be created before any of the frontend pods to ensure that the service IP is generated properly, and that it can be provided to the frontend pods as an environment variable.
For this reason, OpenShift Container Platform has a built-in DNS so that the services can be reached by the service DNS as well as the service IP/port. OpenShift Container Platform supports split DNS by running SkyDNS on the master that answers DNS queries for services. The master listens to port 53 by default.
When the node starts, the following message indicates the Kubelet is correctly resolved to the master:
0308 19:51:03.118430 4484 node.go:197] Started Kubelet for node openshiftdev.local, server at 0.0.0.0:10250 I0308 19:51:03.118459 4484 node.go:199] Kubelet is setting 10.0.2.15 as a DNS nameserver for domain "local"
0308 19:51:03.118430 4484 node.go:197] Started Kubelet for node
openshiftdev.local, server at 0.0.0.0:10250
I0308 19:51:03.118459 4484 node.go:199] Kubelet is setting 10.0.2.15 as a
DNS nameserver for domain "local"If the second message does not appear, the Kubernetes service may not be available.
On a node host, each container’s nameserver has the master name added to the front, and the default search domain for the container will be .<pod_namespace>.cluster.local. The container will then direct any nameserver queries to the master before any other nameservers on the node, which is the default behavior for Docker-formatted containers. The master will answer queries on the .cluster.local domain that have the following form:
| Object Type | Example |
|---|---|
| Default | <pod_namespace>.cluster.local |
| Services | <service>.<pod_namespace>.svc.cluster.local |
| Endpoints | <name>.<namespace>.endpoints.cluster.local |
This prevents having to restart frontend pods in order to pick up new services, which would create a new IP for the service. This also removes the need to use environment variables, because pods can use the service DNS. Also, as the DNS does not change, you can reference database services as db.local in configuration files. Wildcard lookups are also supported, because any lookups resolve to the service IP, and removes the need to create the backend service before any of the frontend pods, since the service name (and hence DNS) is established upfront.
This DNS structure also covers headless services, where a portal IP is not assigned to the service and the kube-proxy does not load-balance or provide routing for its endpoints. Service DNS can still be used and responds with multiple A records, one for each pod of the service, allowing the client to round-robin between each pod.
5.2. OpenShift SDN
5.2.1. Overview
OpenShift Container Platform uses a software-defined networking (SDN) approach to provide a unified cluster network that enables communication between pods across the OpenShift Container Platform cluster. This pod network is established and maintained by the OpenShift SDN, which configures an overlay network using Open vSwitch (OVS).
OpenShift SDN provides three SDN plug-ins for configuring the pod network:
- The ovs-subnet plug-in is the original plug-in, which provides a "flat" pod network where every pod can communicate with every other pod and service.
The ovs-multitenant plug-in provides project-level isolation for pods and services. Each project receives a unique Virtual Network ID (VNID) that identifies traffic from pods assigned to the project. Pods from different projects cannot send packets to or receive packets from pods and services of a different project.
However, projects that receive VNID 0 are more privileged in that they are allowed to communicate with all other pods, and all other pods can communicate with them. In OpenShift Container Platform clusters, the default project has VNID 0. This facilitates certain services, such as the load balancer, to communicate with all other pods in the cluster and vice versa.
- The ovs-networkpolicy plug-in allows project administrators to configure their own isolation policies using NetworkPolicy objects.
Information on configuring the SDN on masters and nodes is available in Configuring the SDN.
5.2.2. Design on Masters
On an OpenShift Container Platform master, OpenShift SDN maintains a registry of nodes, stored in etcd. When the system administrator registers a node, OpenShift SDN allocates an unused subnet from the cluster network and stores this subnet in the registry. When a node is deleted, OpenShift SDN deletes the subnet from the registry and considers the subnet available to be allocated again.
In the default configuration, the cluster network is the 10.128.0.0/14 network (i.e. 10.128.0.0 - 10.131.255.255), and nodes are allocated /23 subnets (i.e., 10.128.0.0/23, 10.128.2.0/23, 10.128.4.0/23, and so on). This means that the cluster network has 512 subnets available to assign to nodes, and a given node is allocated 510 addresses that it can assign to the containers running on it. The size and address range of the cluster network are configurable, as is the host subnet size.
If the subnet extends into the next higher octet, it is rotated so that the subnet bits with 0s in the shared octet are allocated first. For example, if the network is 10.1.0.0/16, with hostsubnetlength=6, then the subnet of 10.1.0.0/26 and 10.1.1.0/26, through to 10.1.255.0/26 are allocated before 10.1.0.64/26, 10.1.1.64/26 are filled. This ensures that the subnet is easier to follow.
Note that the OpenShift SDN on a master does not configure the local (master) host to have access to any cluster network. Consequently, a master host does not have access to pods via the cluster network, unless it is also running as a node.
When using the ovs-multitenant plug-in, the OpenShift SDN master also watches for the creation and deletion of projects, and assigns VXLAN VNIDs to them, which are later used by the nodes to isolate traffic correctly.
5.2.3. Design on Nodes
On a node, OpenShift SDN first registers the local host with the SDN master in the aforementioned registry so that the master allocates a subnet to the node.
Next, OpenShift SDN creates and configures three network devices:
-
br0: the OVS bridge device that pod containers will be attached to. OpenShift SDN also configures a set of non-subnet-specific flow rules on this bridge. -
tun0: an OVS internal port (port 2 onbr0). This gets assigned the cluster subnet gateway address, and is used for external network access. OpenShift SDN configures netfilter and routing rules to enable access from the cluster subnet to the external network via NAT. -
vxlan_sys_4789: The OVS VXLAN device (port 1 onbr0), which provides access to containers on remote nodes. Referred to asvxlan0in the OVS rules.
Each time a pod is started on the host, OpenShift SDN:
- assigns the pod a free IP address from the node’s cluster subnet.
-
attaches the host side of the pod’s veth interface pair to the OVS bridge
br0. - adds OpenFlow rules to the OVS database to route traffic addressed to the new pod to the correct OVS port.
- in the case of the ovs-multitenant plug-in, adds OpenFlow rules to tag traffic coming from the pod with the pod’s VNID, and to allow traffic into the pod if the traffic’s VNID matches the pod’s VNID (or is the privileged VNID 0). Non-matching traffic is filtered out by a generic rule.
OpenShift SDN nodes also watch for subnet updates from the SDN master. When a new subnet is added, the node adds OpenFlow rules on br0 so that packets with a destination IP address in the remote subnet go to vxlan0 (port 1 on br0) and thus out onto the network. The ovs-subnet plug-in sends all packets across the VXLAN with VNID 0, but the ovs-multitenant plug-in uses the appropriate VNID for the source container.
5.2.4. Packet Flow
Suppose you have two containers, A and B, where the peer virtual Ethernet device for container A’s eth0 is named vethA and the peer for container B’s eth0 is named vethB.
If the Docker service’s use of peer virtual Ethernet devices is not already familiar to you, see Docker’s advanced networking documentation.
Now suppose first that container A is on the local host and container B is also on the local host. Then the flow of packets from container A to container B is as follows:
eth0 (in A’s netns)
Next, suppose instead that container A is on the local host and container B is on a remote host on the cluster network. Then the flow of packets from container A to container B is as follows:
eth0 (in A’s netns)
Finally, if container A connects to an external host, the traffic looks like:
eth0 (in A’s netns)
Almost all packet delivery decisions are performed with OpenFlow rules in the OVS bridge br0, which simplifies the plug-in network architecture and provides flexible routing. In the case of the ovs-multitenant plug-in, this also provides enforceable network isolation.
5.2.5. Network Isolation
You can use the ovs-multitenant plug-in to achieve network isolation. When a packet exits a pod assigned to a non-default project, the OVS bridge br0 tags that packet with the project’s assigned VNID. If the packet is directed to another IP address in the node’s cluster subnet, the OVS bridge only allows the packet to be delivered to the destination pod if the VNIDs match.
If a packet is received from another node via the VXLAN tunnel, the Tunnel ID is used as the VNID, and the OVS bridge only allows the packet to be delivered to a local pod if the tunnel ID matches the destination pod’s VNID.
Packets destined for other cluster subnets are tagged with their VNID and delivered to the VXLAN tunnel with a tunnel destination address of the node owning the cluster subnet.
As described before, VNID 0 is privileged in that traffic with any VNID is allowed to enter any pod assigned VNID 0, and traffic with VNID 0 is allowed to enter any pod. Only the default OpenShift Container Platform project is assigned VNID 0; all other projects are assigned unique, isolation-enabled VNIDs. Cluster administrators can optionally control the pod network for the project using the administrator CLI.
5.3. Available SDN plug-ins
OpenShift Container Platform supports the Kubernetes Container Network Interface (CNI) as the interface between the OpenShift Container Platform and Kubernetes. Software defined network (SDN) plug-ins match network capabilities to your networking needs. Additional plug-ins that support the CNI interface can be added as needed.
5.3.1. OpenShift SDN
OpenShift SDN is installed and configured by default as part of the Ansible-based installation procedure. See the OpenShift SDN section for more information.
5.3.2. Third-Party SDN plug-ins
5.3.2.1. Cisco ACI SDN
The Cisco ACI CNI plug-in for OpenShift Container Platform provides integration between the Cisco Application Policy Infrastructure Controller (Cisco APIC) controller and one or more OpenShift Container Platform clusters connected to a Cisco ACI fabric.
This integration is implemented across two main functional areas:
- The Cisco ACI CNI plug-in extends the ACI fabric capabilities to OpenShift Container Platform clusters in order to provide IP address management, networking, load balancing, and security functions for OpenShift Container Platform workloads. The Cisco ACI CNI plug-in connects all OpenShift Container Platform Pods to the integrated VXLAN overlay provided by Cisco ACI.
- The Cisco ACI CNI plug-in models the entire OpenShift Container Platform cluster as a VMM domain on the Cisco APIC. This provides APIC with access to the inventory of resources of the OpenShift Container Platform cluster, including the number of OpenShift Container Platform nodes, OpenShift Container Platform namespaces, services, deployments, Pods, their IP and MAC addresses, interfaces they are using, and so on. APIC uses this information to automatically correlate physical and virtual resources in order to simplify operations.
The Cisco ACI CNI plug-in is designed to be transparent for OpenShift Container Platform developers and administrators and to integrate seamlessly from an operational standpoint.
For more information, see Cisco ACI CNI Plugin for Red Hat OpenShift Container Platform Architecture and Design Guide.
5.3.2.2. Flannel SDN
flannel is a virtual networking layer designed specifically for containers. OpenShift Container Platform can use it for networking containers instead of the default software-defined networking (SDN) components. This is useful if running OpenShift Container Platform within a cloud provider platform that also relies on SDN, such as OpenStack, and you want to avoid encapsulating packets twice through both platforms.
Architecture
OpenShift Container Platform runs flannel in host-gw mode, which maps routes from container to container. Each host within the network runs an agent called flanneld, which is responsible for:
- Managing a unique subnet on each host
- Distributing IP addresses to each container on its host
- Mapping routes from one container to another, even if on different hosts
Each flanneld agent provides this information to a centralized etcd store so other agents on hosts can route packets to other containers within the flannel network.
The following diagram illustrates the architecture and data flow from one container to another using a flannel network:
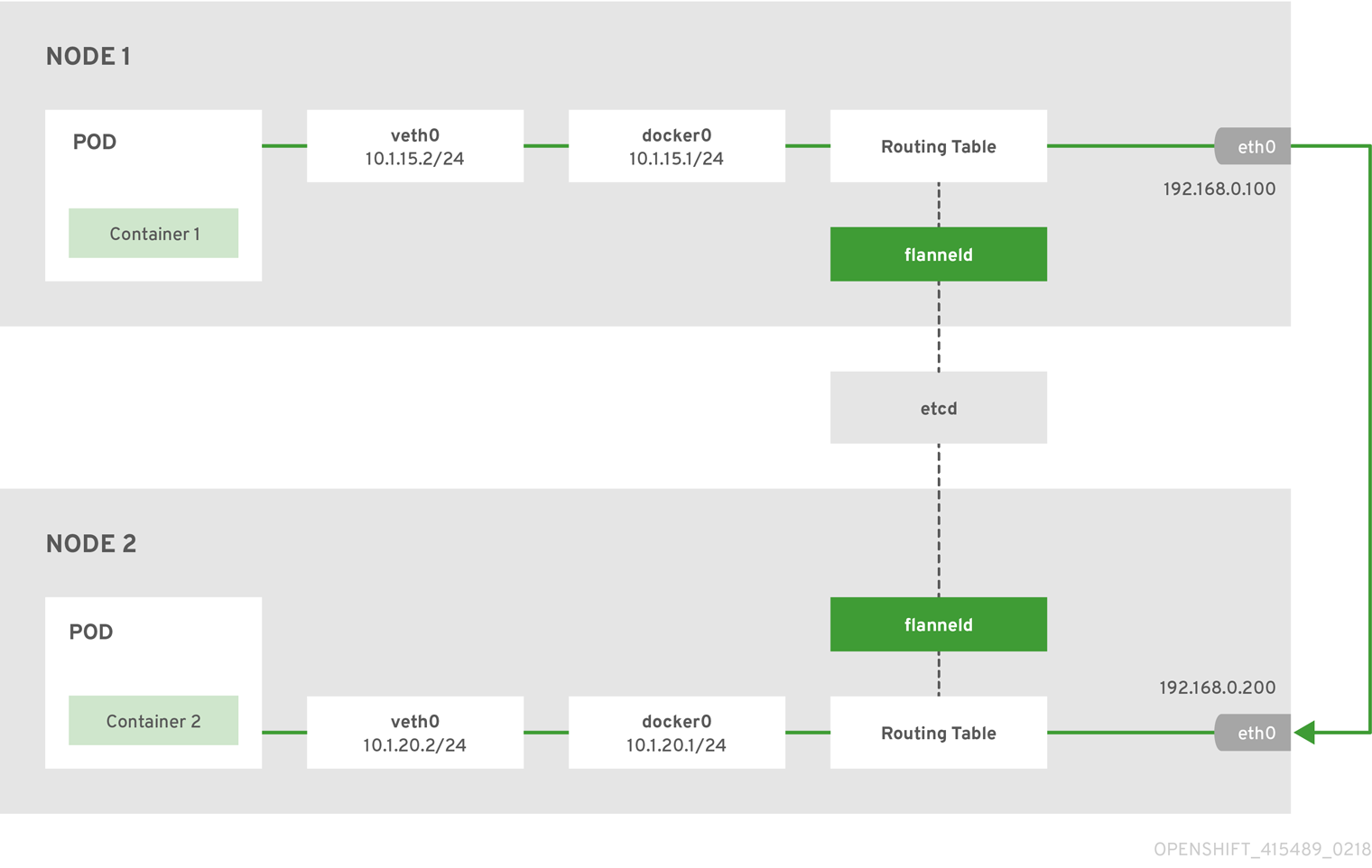
Node 1 would contain the following routes:
default via 192.168.0.100 dev eth0 proto static metric 100 10.1.15.0/24 dev docker0 proto kernel scope link src 10.1.15.1 10.1.20.0/24 via 192.168.0.200 dev eth0
default via 192.168.0.100 dev eth0 proto static metric 100
10.1.15.0/24 dev docker0 proto kernel scope link src 10.1.15.1
10.1.20.0/24 via 192.168.0.200 dev eth0Node 2 would contain the following routes:
default via 192.168.0.200 dev eth0 proto static metric 100 10.1.20.0/24 dev docker0 proto kernel scope link src 10.1.20.1 10.1.15.0/24 via 192.168.0.100 dev eth0
default via 192.168.0.200 dev eth0 proto static metric 100
10.1.20.0/24 dev docker0 proto kernel scope link src 10.1.20.1
10.1.15.0/24 via 192.168.0.100 dev eth05.3.2.3. NSX-T SDN
The VMware NSX-T ™ Data Center provides a policy-based overlay network reproducing the complete set of Layer 2 through Layer 7 networking services (such as switching, routing, access control, fire-walling, and QoS) in software for native OpenShift Container Platform networking capabilities.
The NSX-T components can be installed and configured as part of the Ansible installation procedure, which integrates an OpenShift Container Platform SDN into a data-center-wide NSX-T virtualised network connecting bare metal, virtual machines, and OpenShift Container Platform pods. See the Installation section for information on how to install and deploy OpenShift Container Platform with VMware NSX-T.
The NSX-T Container Plug-In (NCP) integrates OpenShift Container Platform into an NSX-T Manager, which is typically configured for the entire data center.
For information on the NSX-T Data Center architecture and administration, see the VMware NSX-T Data Center v2.4 documentation and the NSX-T NCP configuration guides.
5.3.2.4. Nuage SDN
Nuage Networks' SDN solution delivers highly scalable, policy-based overlay networking for pods in an OpenShift Container Platform cluster. Nuage SDN can be installed and configured as a part of the Ansible-based installation procedure. See the Advanced Installation section for information on how to install and deploy OpenShift Container Platform with Nuage SDN.
Nuage Networks provides a highly scalable, policy-based SDN platform called Virtualized Services Platform (VSP). Nuage VSP uses an SDN Controller, along with the open source Open vSwitch for the data plane.
Nuage uses overlays to provide policy-based networking between OpenShift Container Platform and other environments consisting of VMs and bare metal servers. The platform’s real-time analytics engine enables visibility and security monitoring for OpenShift Container Platform applications.
Nuage VSP integrates with OpenShift Container Platform to allows business applications to be quickly turned up and updated by removing the network lag faced by DevOps teams.
Figure 5.1. Nuage VSP Integration with OpenShift Container Platform

There are two specific components responsible for the integration.
- The nuage-openshift-monitor service, which runs as a separate service on the OpenShift Container Platform master node.
- The vsp-openshift plug-in, which is invoked by the OpenShift Container Platform runtime on each of the nodes of the cluster.
Nuage Virtual Routing and Switching software (VRS) is based on open source Open vSwitch and is responsible for the datapath forwarding. The VRS runs on each node and gets policy configuration from the controller.
Nuage VSP Terminology
Figure 5.2. Nuage VSP Building Blocks
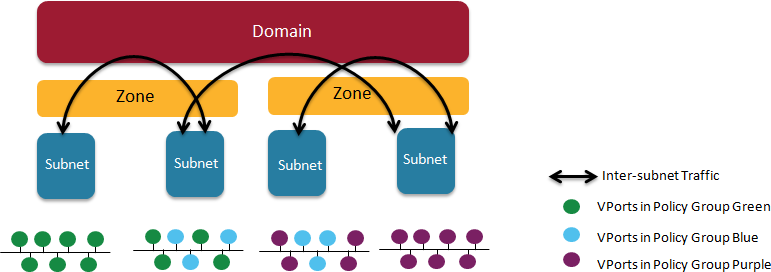
- Domains: An organization contains one or more domains. A domain is a single "Layer 3" space. In standard networking terminology, a domain maps to a VRF instance.
- Zones: Zones are defined under a domain. A zone does not map to anything on the network directly, but instead acts as an object with which policies are associated such that all endpoints in the zone adhere to the same set of policies.
- Subnets: Subnets are defined under a zone. A subnet is a specific Layer 2 subnet within the domain instance. A subnet is unique and distinct within a domain, that is, subnets within a Domain are not allowed to overlap or to contain other subnets in accordance with the standard IP subnet definitions.
- VPorts: A VPort is a new level in the domain hierarchy, intended to provide more granular configuration. In addition to containers and VMs, VPorts are also used to attach Host and Bridge Interfaces, which provide connectivity to Bare Metal servers, Appliances, and Legacy VLANs.
- Policy Group: Policy Groups are collections of VPorts.
Mapping of Constructs
Many OpenShift Container Platform concepts have a direct mapping to Nuage VSP constructs:
Figure 5.3. Nuage VSP and OpenShift Container Platform mapping
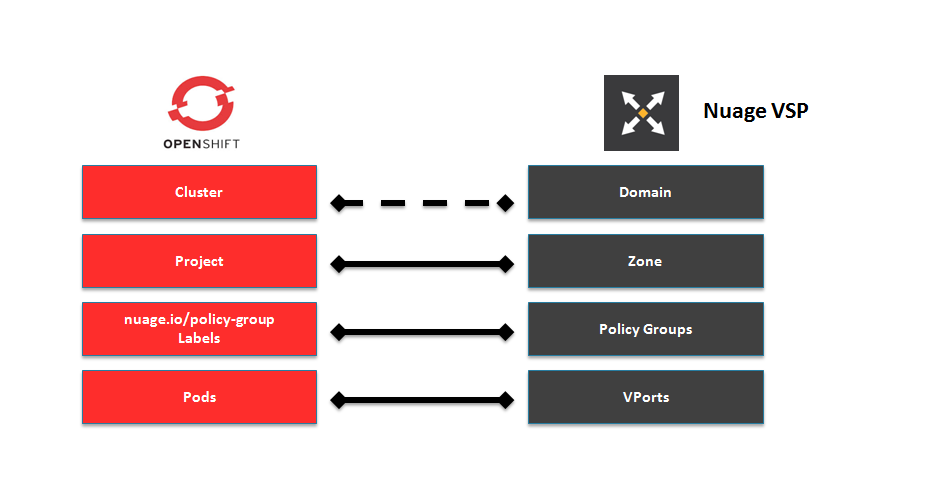
A Nuage subnet is not mapped to an OpenShift Container Platform node, but a subnet for a particular project can span multiple nodes in OpenShift Container Platform.
A pod spawning in OpenShift Container Platform translates to a virtual port being created in VSP. The vsp-openshift plug-in interacts with the VRS and gets a policy for that virtual port from the VSD via the VSC. Policy Groups are supported to group multiple pods together that must have the same set of policies applied to them. Currently, pods can only be assigned to policy groups using the operations workflow where a policy group is created by the administrative user in VSD. The pod being a part of the policy group is specified by means of nuage.io/policy-group label in the specification of the pod.
Integration Components
Nuage VSP integrates with OpenShift Container Platform using two main components:
- nuage-openshift-monitor
- vsp-openshift plugin
nuage-openshift-monitor
nuage-openshift-monitor is a service that monitors the OpenShift Container Platform API server for creation of projects, services, users, user-groups, etc.
In case of a Highly Available (HA) OpenShift Container Platform cluster with multiple masters, nuage-openshift-monitor process runs on all the masters independently without any change in functionality.
For the developer workflow, nuage-openshift-monitor also auto-creates VSD objects by exercising the VSD REST API to map OpenShift Container Platform constructs to VSP constructs. Each cluster instance maps to a single domain in Nuage VSP. This allows a given enterprise to potentially have multiple cluster installations - one per domain instance for that Enterprise in Nuage. Each OpenShift Container Platform project is mapped to a zone in the domain of the cluster on the Nuage VSP. Whenever nuage-openshift-monitor sees an addition or deletion of the project, it instantiates a zone using the VSDK APIs corresponding to that project and allocates a block of subnet for that zone. Additionally, the nuage-openshift-monitor also creates a network macro group for this project. Likewise, whenever nuage-openshift-monitor sees an addition ordeletion of a service, it creates a network macro corresponding to the service IP and assigns that network macro to the network macro group for that project (user provided network macro group using labels is also supported) to enable communication to that service.
For the developer workflow, all pods that are created within the zone get IPs from that subnet pool. The subnet pool allocation and management is done by nuage-openshift-monitor based on a couple of plug-in specific parameters in the master-config file. However the actual IP address resolution and vport policy resolution is still done by VSD based on the domain/zone that gets instantiated when the project is created. If the initial subnet pool is exhausted, nuage-openshift-monitor carves out an additional subnet from the cluster CIDR to assign to a given project.
For the operations workflow, the users specify Nuage recognized labels on their application or pod specification to resolve the pods into specific user-defined zones and subnets. However, this cannot be used to resolve pods in the zones or subnets created via the developer workflow by nuage-openshift-monitor.
In the operations workflow, the administrator is responsible for pre-creating the VSD constructs to map the pods into a specific zone/subnet as well as allow communication between OpenShift entities (ACL rules, policy groups, network macros, and network macro groups). Detailed description of how to use Nuage labels is provided in the Nuage VSP Openshift Integration Guide.
vsp-openshift Plug-in
The vsp-openshift networking plug-in is called by the OpenShift Container Platform runtime on each OpenShift Container Platform node. It implements the network plug-in init and pod setup, teardown, and status hooks. The vsp-openshift plug-in is also responsible for allocating the IP address for the pods. In particular, it communicates with the VRS (the forwarding engine) and configures the IP information onto the pod.
5.3.3. Kuryr SDN for OpenShift Container Platform
Kuryr (or more specifically Kuryr-Kubernetes) is an SDN solution built using CNI and OpenStack Neutron. Its advantages include being able to use a wide range of Neutron SDN backends and providing interconnectivity between Kubernetes pods and OpenStack virtual machines (VMs).
Kuryr-Kubernetes and OpenShift Container Platform integration is primarily designed for OpenShift Container Platform clusters running on OpenStack VMs.
5.3.3.1. OpenStack Deployment Requirements
Kuryr SDN has some requirements regarding configuration of OpenStack it will be using. In particular:
- Minimal service set is Keystone and Neutron.
- It works with Octavia.
- Trunk ports extension must be enabled.
- Neutron must use the Open vSwitch firewall driver.
5.3.3.2. kuryr-controller
kuryr-controller is a service responsible for watching OpenShift Container Platform API for new pods being spawned and creating Neutron resources for them. For example, when a pod gets created, kuryr-controller will notice that and call OpenStack Neutron to create a new port. Then, information about that port (or VIF) is saved into the pod’s annotations. kuryr-controller is also able to use precreated port pools for faster pod creation.
Currently, kuryr-controller must be run as a single service instance, so it is modeled in OpenShift Container Platform as Deployment with replicas=1. It requires access to the underlying OpenStack service APIs.
5.3.3.3. kuryr-cni
kuryr-cni container serves two roles in Kuryr-Kubernetes deployment. It is responsible for installing and configuring Kuryr CNI script on OpenShift Container Platform nodes and running kuryr-daemon service that is networking the Pods on the host. This means that kuryr-cni container needs to run on every OpenShift Container Platform node, so it is modeled as DaemonSet.
OpenShift Container Platform CNI will call the Kuryr CNI script every time a new pod is spawned on or deleted from an OpenShift Container Platform host. The script fetches the container ID of the local kuryr-cni from Docker API and executes Kuryr CNI plug-in binary through docker exec passing all the CNI call arguments. The plug-in then calls kuryr-daemon over local HTTP socket, again passing all the parameters.
kuryr-daemon service is responsible for watching for Pod’s annotations about Neutron VIFs created for them. When CNI request for given Pod is received daemon either has VIF information in memory already or waits for the annotation to appear on Pod definition. Once VIF info in known all the networking operations happen.
5.4. Available router plug-ins
A router can be assigned to a node to control traffic in an OpenShift Container Platform cluster. OpenShift Container Platform uses HAProxy as the default router, but options are available.
5.4.1. The HAProxy Template Router
The HAProxy template router implementation is the reference implementation for a template router plug-in. It uses the openshift3/ose-haproxy-router repository to run an HAProxy instance alongside the template router plug-in.
The template router has two components:
- A wrapper that watches endpoints and routes and causes a HAProxy reload based on changes
- A controller that builds the HAProxy configuration file based on routes and endpoints
The HAProxy router uses version 1.8.1.
The controller and HAProxy are housed inside a pod, which is managed by a deployment configuration. The process of setting up the router is automated by the oc adm router command.
The controller watches the routes and endpoints for changes, as well as HAProxy’s health. When a change is detected, it builds a new haproxy-config file and restarts HAProxy. The haproxy-config file is constructed based on the router’s template file and information from OpenShift Container Platform.
The HAProxy template file can be customized as needed to support features that are not currently supported by OpenShift Container Platform. The HAProxy manual describes all of the features supported by HAProxy.
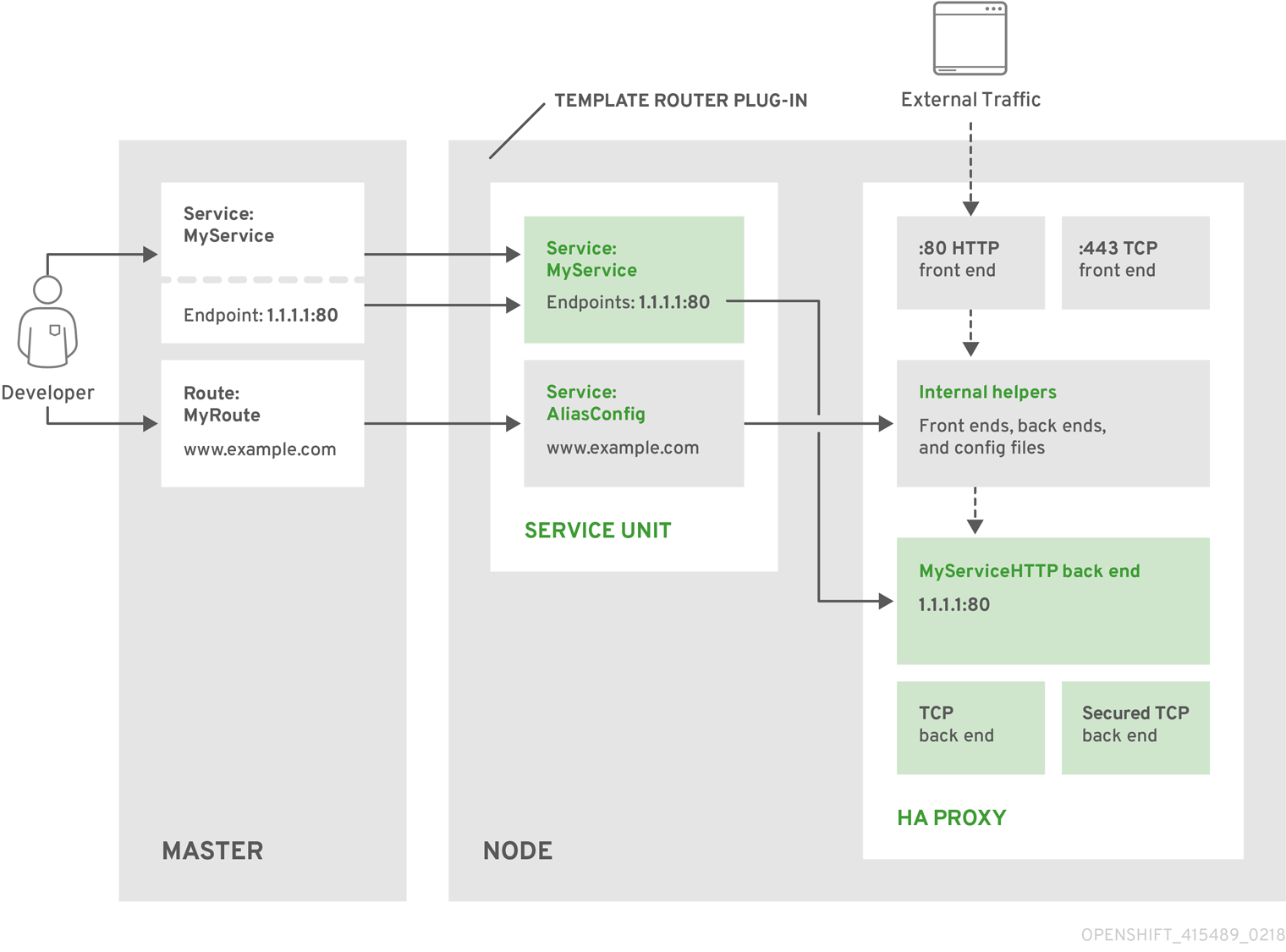
The following diagram illustrates how data flows from the master through the plug-in and finally into an HAProxy configuration:
Figure 5.4. HAProxy Router Data Flow
HAProxy Template Router Metrics
The HAProxy router exposes or publishes metrics in Prometheus format for consumption by external metrics collection and aggregation systems (e.g. Prometheus, statsd). The router can be configured to provide HAProxy CSV format metrics, or provide no router metrics at all.
The metrics are collected from both the router controller and from HAProxy every five seconds. The router metrics counters start at zero when the router is deployed and increase over time. The HAProxy metrics counters are reset to zero every time haproxy is reloaded. The router collects HAProxy statistics for each frontend, back end, and server. To reduce resource usage when there are more than 500 servers, the back ends are reported instead of the servers because a back end can have multiple servers.
The statistics are a subset of the available HAProxy statistics.
The following HAProxy metrics are collected on a periodic basis and converted to Prometheus format. For every front end the "F" counters are collected. When the counters are collected for each back end and the "S" server counters are collected for each server. Otherwise, the "B" counters are collected for each back end and no server counters are collected.
See router environment variables for more information.
In the following table:
Column 1 - Index from HAProxy CSV statistics
Column 2
| F | Front end metrics |
| b | Back end metrics when not showing Server metrics due to the Server Threshold, |
| B | Back end metrics when showing Server metrics |
| S | Server metrics. |
Column 3 - The counter
Column 4 - Counter description
| Index | Usage | Counter | Description |
| 2 | bBS | current_queue | Current number of queued requests not assigned to any server. |
| 4 | FbS | current_sessions | Current number of active sessions. |
| 5 | FbS | max_sessions | Maximum observed number of active sessions. |
| 7 | FbBS | connections_total | Total number of connections. |
| 8 | FbS | bytes_in_total | Current total of incoming bytes. |
| 9 | FbS | bytes_out_total | Current total of outgoing bytes. |
| 13 | bS | connection_errors_total | Total of connection errors. |
| 14 | bS | response_errors_total | Total of response errors. |
| 17 | bBS | up | Current health status of the back end (1 = UP, 0 = DOWN). |
| 21 | S | check_failures_total | Total number of failed health checks. |
| 24 | S | downtime_seconds_total | Total downtime in seconds.", nil), |
| 33 | FbS | current_session_rate | Current number of sessions per second over last elapsed second. |
| 35 | FbS | max_session_rate | Maximum observed number of sessions per second. |
| 40 | FbS | http_responses_total | Total of HTTP responses, code 2xx |
| 43 | FbS | http_responses_total | Total of HTTP responses, code 5xx |
| 60 | bS | http_average_response_latency_milliseconds | of the last 1024 requests in milliseconds. |
The router controller scrapes the following items. These are only available with Prometheus format metrics.
| Name | Description |
| template_router_reload_seconds | Measures the time spent reloading the router in seconds. |
| template_router_write_config_seconds | Measures the time spent writing out the router configuration to disk in seconds. |
| haproxy_exporter_up | Was the last scrape of haproxy successful. |
| haproxy_exporter_csv_parse_failures | Number of errors while parsing CSV. |
| haproxy_exporter_scrape_interval | The time in seconds before another scrape is allowed, proportional to size of data. |
| haproxy_exporter_server_threshold | Number of servers tracked and the current threshold value. |
| haproxy_exporter_total_scrapes | Current total HAProxy scrapes. |
| http_request_duration_microseconds | The HTTP request latencies in microseconds. |
| http_request_size_bytes | The HTTP request sizes in bytes. |
| http_response_size_bytes | The HTTP response sizes in bytes. |
| openshift_build_info | A metric with a constant '1' value labeled by major, minor, git commit & git version from which OpenShift was built. |
| ssh_tunnel_open_count | Counter of SSH tunnel total open attempts |
| ssh_tunnel_open_fail_count | Counter of SSH tunnel failed open attempts |
5.5. Port Forwarding
5.5.1. Overview
OpenShift Container Platform takes advantage of a feature built-in to Kubernetes to support port forwarding to pods. This is implemented using HTTP along with a multiplexed streaming protocol such as SPDY or HTTP/2.
Developers can use the CLI to port forward to a pod. The CLI listens on each local port specified by the user, forwarding via the described protocol.
5.5.2. Server Operation
The Kubelet handles port forward requests from clients. Upon receiving a request, it upgrades the response and waits for the client to create port forwarding streams. When it receives a new stream, it copies data between the stream and the pod’s port.
Architecturally, there are options for forwarding to a pod’s port. The supported implementation currently in OpenShift Container Platform invokes nsenter directly on the node host to enter the pod’s network namespace, then invokes socat to copy data between the stream and the pod’s port. However, a custom implementation could include running a "helper" pod that then runs nsenter and socat, so that those binaries are not required to be installed on the host.
5.6. Remote Commands
5.6.1. Overview
OpenShift Container Platform takes advantage of a feature built into Kubernetes to support executing commands in containers. This is implemented using HTTP along with a multiplexed streaming protocol such as SPDY or HTTP/2.
Developers can use the CLI to execute remote commands in containers.
5.6.2. Server Operation
The Kubelet handles remote execution requests from clients. Upon receiving a request, it upgrades the response, evaluates the request headers to determine what streams (stdin, stdout, and/or stderr) to expect to receive, and waits for the client to create the streams.
After the Kubelet has received all the streams, it executes the command in the container, copying between the streams and the command’s stdin, stdout, and stderr, as appropriate. When the command terminates, the Kubelet closes the upgraded connection, as well as the underlying one.
Architecturally, there are options for running a command in a container. The supported implementation currently in OpenShift Container Platform invokes nsenter directly on the node host to enter the container’s namespaces prior to executing the command. However, custom implementations could include using docker exec, or running a "helper" container that then runs nsenter so that nsenter is not a required binary that must be installed on the host.
5.7. Routes
5.7.1. Overview
An OpenShift Container Platform route exposes a service at a host name, such as www.example.com, so that external clients can reach it by name.
DNS resolution for a host name is handled separately from routing. Your administrator may have configured a DNS wildcard entry that will resolve to the OpenShift Container Platform node that is running the OpenShift Container Platform router. If you are using a different host name you may need to modify its DNS records independently to resolve to the node that is running the router.
Each route consists of a name (limited to 63 characters), a service selector, and an optional security configuration.
5.7.2. Routers
An OpenShift Container Platform administrator can deploy routers to nodes in an OpenShift Container Platform cluster, which enable routes created by developers to be used by external clients. The routing layer in OpenShift Container Platform is pluggable, and several router plug-ins are provided and supported by default.
See the Configuring Clusters guide for information on configuring a router.
A router uses the service selector to find the service and the endpoints backing the service. When both router and service provide load balancing, OpenShift Container Platform uses the router load balancing. A router detects relevant changes in the IP addresses of its services and adapts its configuration accordingly. This is useful for custom routers to communicate modifications of API objects to an external routing solution.
The path of a request starts with the DNS resolution of a host name to one or more routers. The suggested method is to define a cloud domain with a wildcard DNS entry pointing to one or more virtual IP (VIP) addresses backed by multiple router instances. Routes using names and addresses outside the cloud domain require configuration of individual DNS entries.
When there are fewer VIP addresses than routers, the routers corresponding to the number of addresses are active and the rest are passive. A passive router is also known as a hot-standby router. For example, with two VIP addresses and three routers, you have an "active-active-passive" configuration. See High Availability for more information on router VIP configuration.
Routes can be sharded among the set of routers. Administrators can set up sharding on a cluster-wide basis and users can set up sharding for the namespace in their project. Sharding allows the operator to define multiple router groups. Each router in the group serves only a subset of traffic.
OpenShift Container Platform routers provide external host name mapping and load balancing of service end points over protocols that pass distinguishing information directly to the router; the host name must be present in the protocol in order for the router to determine where to send it.
Router plug-ins assume they can bind to host ports 80 (HTTP) and 443 (HTTPS), by default. This means that routers must be placed on nodes where those ports are not otherwise in use. Alternatively, a router can be configured to listen on other ports by setting the ROUTER_SERVICE_HTTP_PORT and ROUTER_SERVICE_HTTPS_PORT environment variables.
Because a router binds to ports on the host node, only one router listening on those ports can be on each node if the router uses host networking (the default). Cluster networking is configured such that all routers can access all pods in the cluster.
Routers support the following protocols:
- HTTP
- HTTPS (with SNI)
- WebSockets
- TLS with SNI
WebSocket traffic uses the same route conventions and supports the same TLS termination types as other traffic.
For a secure connection to be established, a cipher common to the client and server must be negotiated. As time goes on, new, more secure ciphers become available and are integrated into client software. As older clients become obsolete, the older, less secure ciphers can be dropped. By default, the router supports a broad range of commonly available clients. The router can be configured to use a selected set of ciphers that support desired clients and do not include the less secure ciphers.
5.7.2.1. Template Routers
A template router is a type of router that provides certain infrastructure information to the underlying router implementation, such as:
- A wrapper that watches endpoints and routes.
- Endpoint and route data, which is saved into a consumable form.
- Passing the internal state to a configurable template and executing the template.
- Calling a reload script.
5.7.3. Available Router Plug-ins
See the Available router plug-ins section for the verified available router plug-ins.
Instructions on deploying these routers are available in Deploying a Router.
5.7.4. Sticky Sessions
Implementing sticky sessions is up to the underlying router configuration. The default HAProxy template implements sticky sessions using the balance source directive, which balances based on the source IP. In addition, the template router plug-in provides the service name and namespace to the underlying implementation. This can be used for more advanced configuration, such as implementing stick-tables that synchronize between a set of peers.
Sticky sessions ensure that all traffic from a user’s session go to the same pod, creating a better user experience. While satisfying the user’s requests, the pod caches data, which can be used in subsequent requests. For example, for a cluster with five back-end pods and two load-balanced routers, you can ensure that the same pod receives the web traffic from the same web browser regardless of the router that handles it.
While returning routing traffic to the same pod is desired, it cannot be guaranteed. However, you can use HTTP headers to set a cookie to determine the pod used in the last connection. When the user sends another request to the application the browser re-sends the cookie and the router knows where to send the traffic.
Cluster administrators can turn off stickiness for passthrough routes separately from other connections, or turn off stickiness entirely.
By default, sticky sessions for passthrough routes are implemented using the source load balancing strategy. The default can be changed for all passthrough routes by using the ROUTER_TCP_BALANCE_SCHEMEenvironment variable, and for individual routes by using the haproxy.router.openshift.io/balance route specific annotation.
Other types of routes use the leastconn load balancing strategy by default, which can be changed by using the ROUTER_LOAD_BALANCE_ALGORITHM environment variable. It can be changed for individual routes by using the haproxy.router.openshift.io/balance route specific annotation.
Cookies cannot be set on passthrough routes, because the HTTP traffic cannot be seen. Instead, a number is calculated based on the source IP address, which determines the back-end.
If back-ends change, the traffic could head to the wrong server, making it less sticky, and if you are using a load-balancer (which hides the source IP) the same number is set for all connections and traffic is sent to the same pod.
In addition, the template router plug-in provides the service name and namespace to the underlying implementation. This can be used for more advanced configuration such as implementing stick-tables that synchronize between a set of peers.
Specific configuration for this router implementation is stored in the haproxy-config.template file located in the /var/lib/haproxy/conf directory of the router container. The file may be customized.
The source load balancing strategy does not distinguish between external client IP addresses; because of the NAT configuration, the originating IP address (HAProxy remote) is the same. Unless the HAProxy router is running with hostNetwork: true, all external clients will be routed to a single pod.
5.7.5. Router Environment Variables
For all the items outlined in this section, you can set environment variables in the deployment config for the router to alter its configuration, or use the oc set env command:
oc set env <object_type>/<object_name> KEY1=VALUE1 KEY2=VALUE2
$ oc set env <object_type>/<object_name> KEY1=VALUE1 KEY2=VALUE2For example:
oc set env dc/router ROUTER_SYSLOG_ADDRESS=127.0.0.1 ROUTER_LOG_LEVEL=debug
$ oc set env dc/router ROUTER_SYSLOG_ADDRESS=127.0.0.1 ROUTER_LOG_LEVEL=debug| Variable | Default | Description |
|---|---|---|
|
| The contents of a default certificate to use for routes that don’t expose a TLS server cert; in PEM format. | |
|
|
A path to a directory that contains a file named tls.crt. If tls.crt is not a PEM file which also contains a private key, it is first combined with a file named tls.key in the same directory. The PEM-format contents are then used as the default certificate. Only used if | |
|
|
A path to default certificate to use for routes that don’t expose a TLS server cert; in PEM format. Only used if | |
|
|
|
If |
|
| A label selector to apply to namespaces to watch, empty means all. | |
|
| A label selector to apply to projects to watch, emtpy means all. | |
|
| The path to the reload script to use to reload the router. | |
|
|
A comma-separated list of domains that the host name in a route can only be part of. Any subdomain in the domain can be used. Option | |
|
| String to specify how the endpoints should be processed while using the template function processEndpointsForAlias. Valid values are ["shuffle", ""]. "shuffle" will randomize the elements upon every call. Default behavior returns in pre-determined order. | |
|
|
|
If set to |
|
| Specifies cookie name to override the internally generated default name. The name must consist of any combination of upper and lower case letters, digits, "_", and "-". The default is the hashed internal key name for the route. | |
|
| "text/html text/plain text/css" | A space separated list of mime types to compress. |
|
|
A comma-separated list of domains that the host name in a route can not be part of. No subdomain in the domain can be used either. Overrides option | |
|
|
If | |
|
| 0.0.0.0:1936 | Sets the listening address for router metrics. |
|
| warning | The log level to send to the syslog server. |
|
| 20000 | Maximum number of concurrent connections. |
|
| 500 | |
|
|
Metrics collected in CSV format. For example, | |
|
| 5s | |
|
| 5s | |
|
| haproxy | Generate metrics for the HAProxy router. (haproxy is the only supported value) |
|
|
A comma-separated list of domain names. If a route’s domain name matches the host in a route, the host name is ignored and the pattern defined in | |
|
|
If set | |
|
| 443 | Port to listen for HTTPS requests. |
|
| 80 | Port to listen for HTTP requests. |
|
| public | The name that the router identifies itself in the in route status. |
|
| The (optional) host name of the router shown in the in route status. | |
|
|
The namespace the router identifies itself in the in route status. Required if | |
|
| 10443 | Internal port for some front-end to back-end communication (see note below). |
|
| 10444 | Internal port for some front-end to back-end communication (see note below). |
|
| The template that should be used to generate the host name for a route without spec.host (e.g. ${name}-${namespace}.myapps.mycompany.com). | |
|
| Address to send log messages. Disabled if empty. | |
|
| If set, override the default log format used by underlying router implementation. Its value should conform with underlying router implementation’s specification. | |
|
| source |
load balancing strategy. for multiple endpoints for pass-through routes. Available options are |
|
| Specifies the number of threads for the haproxy router. | |
|
| leastconn |
load balancing strategy. for routes with multiple endpoints. Available options are |
|
| A label selector to apply to the routes to watch, empty means all. | |
|
| The password needed to access router stats (if the router implementation supports it). | |
|
| Port to expose statistics on (if the router implementation supports it). If not set, stats are not exposed. | |
|
| The user name needed to access router stats (if the router implementation supports it). | |
|
|
| The path to the HAProxy template file (in the container image). |
|
|
When set to | |
|
|
When set to | |
|
|
Set to | |
|
| ||
|
| intermediate | Specify the set of ciphers supported by bind. |
|
|
When set to | |
|
| 3600 | Specifies how often to commit changes made with the dynamic configuration manager. This causes the underlying template router implementation to reload the configuration. |
|
| Set to the namespace that contain the routes that serve as blueprints for the dynamic configuration manager. This allows the dynamic configuration manager to support custom routes with any custom annotations, certificates, or configuration files. | |
|
| Set to a label selector to apply to the routes in the blueprint route namespace. This allows you to specify the routes in a namespace that can serve as blueprints for the dynamic configuration manager. | |
|
| 10 |
Specifies the size of the pre-allocated pool for each route blueprint that is managed by the dynamic configuration manager. This can be overriden on an individual route basis using the |
|
| 5 | Specifies the maximum number of dynamic servers added to each route for use by the dynamic configuration manager. |
If you want to run multiple routers on the same machine, you must change the ports that the router is listening on, ROUTER_SERVICE_SNI_PORT and ROUTER_SERVICE_NO_SNI_PORT. These ports can be anything you want as long as they are unique on the machine. These ports will not be exposed externally.
Router timeout variables
TimeUnits are represented by a number followed by the unit: us *(microseconds), ms (milliseconds, default), s (seconds), m (minutes), h *(hours), d (days).
The regular expression is: [1-9][0-9]*(us\|ms\|s\|m\|h\|d)
|
| 5000ms | Length of time between subsequent liveness checks on backends. |
|
| 1s | Controls the TCP FIN timeout period for the client connecting to the route. If the FIN sent to close the connection is not answered within the given time, HAProxy will close the connection. This is harmless if set to a low value and uses fewer resources on the router. |
|
| 30s | Length of time that a client has to acknowledge or send data. |
|
| 5s | The maximum connect time. |
|
| 1s | Controls the TCP FIN timeout from the router to the pod backing the route. |
|
| 30s | Length of time that a server has to acknowledge or send data. |
|
| 1h | Length of time for TCP or WebSocket connections to remain open. If you have websockets/tcp connections (and any time HAProxy is reloaded), the old HAProxy processes will stay for that period. |
|
| 300s |
Set the maximum time to wait for a new HTTP request to appear. If this is set too low, it can cause problems with browsers and applications not expecting a small |
|
| 10s | Length of time the transmission of an HTTP request can take. |
|
| 5s | The minimum frequency the router is allowed to reload to accept new changes. |
|
| 5s | Timeout for the gathering of HAProxy metrics. |
Some effective timeout values can be the sum of certain variables, rather than the specific expected timeout.
For example: ROUTER_SLOWLORIS_HTTP_KEEPALIVE adjusts timeout http-keep-alive, and is set to 300s by default, but haproxy also waits on tcp-request inspect-delay, which is set to 5s. In this case, the overall timeout would be 300s plus 5s.
5.7.6. Load-balancing Strategy
When a route has multiple endpoints, HAProxy distributes requests to the route among the endpoints based on the selected load-balancing strategy. This applies when no persistence information is available, such as on the first request in a session.
The strategy can be one of the following:
-
roundrobin: Each endpoint is used in turn, according to its weight. This is the smoothest and fairest algorithm when the server’s processing time remains equally distributed. -
leastconn: The endpoint with the lowest number of connections receives the request. Round-robin is performed when multiple endpoints have the same lowest number of connections. Use this algorithm when very long sessions are expected, such as LDAP, SQL, TSE, or others. Not intended to be used with protocols that typically use short sessions such as HTTP. -
source: The source IP address is hashed and divided by the total weight of the running servers to designate which server will receive the request. This ensures that the same client IP address will always reach the same server as long as no server goes down or up. If the hash result changes due to the number of running servers changing, many clients will be directed to different servers. This algorithm is generally used with passthrough routes.
The ROUTER_TCP_BALANCE_SCHEME environment variable sets the default strategy for passthrough routes. The ROUTER_LOAD_BALANCE_ALGORITHM environment variable sets the default strategy for the router for the remaining routes. A route specific annotation, haproxy.router.openshift.io/balance, can be used to control specific routes.
5.7.7. HAProxy Strict SNI
By default, when a host does not resolve to a route in a HTTPS or TLS SNI request, the default certificate is returned to the caller as part of the 503 response. This exposes the default certificate and can pose security concerns because the wrong certificate is served for a site. The HAProxy strict-sni option to bind suppresses use of the default certificate.
The ROUTER_STRICT_SNI environment variable controls bind processing. When set to true or TRUE, strict-sni is added to the HAProxy bind. The default setting is false.
The option can be set when the router is created or added later.
oc adm router --strict-sni
$ oc adm router --strict-sni
This sets ROUTER_STRICT_SNI=true.
5.7.8. Router Cipher Suite
Each client (for example, Chrome 30, or Java8) includes a suite of ciphers used to securely connect with the router. The router must have at least one of the ciphers for the connection to be complete:
| Profile | Oldest compatible client |
|---|---|
| modern | Firefox 27, Chrome 30, IE 11 on Windows 7, Edge, Opera 17, Safari 9, Android 5.0, Java 8 |
| intermediate | Firefox 1, Chrome 1, IE 7, Opera 5, Safari 1, Windows XP IE8, Android 2.3, Java 7 |
| old | Windows XP IE6, Java 6 |
See the Security/Server Side TLS reference guide for more information.
By default, the router selects the intermediate profile and sets ciphers based on this profile. When a profile is selected, only the ciphers are set. The TLS version is not governed by the profile.
You can select a different profile by using the --ciphers option when creating a router, or by changing the ROUTER_CIPHERS environment variable with the values modern, intermediate, or old for an existing router. Alternatively, a set of ":" separated ciphers can be provided. The ciphers must be from the set displayed by:
openssl ciphers
openssl ciphers5.7.9. Route Host Names
In order for services to be exposed externally, an OpenShift Container Platform route allows you to associate a service with an externally-reachable host name. This edge host name is then used to route traffic to the service.
When multiple routes from different namespaces claim the same host, the oldest route wins and claims it for the namespace. If additional routes with different path fields are defined in the same namespace, those paths are added. If multiple routes with the same path are used, the oldest takes priority.
A consequence of this behavior is that if you have two routes for a host name: an older one and a newer one. If someone else has a route for the same host name that they created between when you created the other two routes, then if you delete your older route, your claim to the host name will no longer be in effect. The other namespace now claims the host name and your claim is lost.
A Route with a Specified Host:
- 1
- Specifies the externally-reachable host name used to expose a service.
A Route Without a Host:
If a host name is not provided as part of the route definition, then OpenShift Container Platform automatically generates one for you. The generated host name is of the form:
<route-name>[-<namespace>].<suffix>
<route-name>[-<namespace>].<suffix>The following example shows the OpenShift Container Platform-generated host name for the above configuration of a route without a host added to a namespace mynamespace:
Generated Host Name
no-route-hostname-mynamespace.router.default.svc.cluster.local
no-route-hostname-mynamespace.router.default.svc.cluster.local - 1
- The generated host name suffix is the default routing subdomain router.default.svc.cluster.local.
A cluster administrator can also customize the suffix used as the default routing subdomain for their environment.
5.7.10. Route Types
Routes can be either secured or unsecured. Secure routes provide the ability to use several types of TLS termination to serve certificates to the client. Routers support edge, passthrough, and re-encryption termination.
Unsecured Route Object YAML Definition
Unsecured routes are simplest to configure, as they require no key or certificates, but secured routes offer security for connections to remain private.
A secured route is one that specifies the TLS termination of the route. The available types of termination are described below.
5.7.10.1. Path Based Routes
Path based routes specify a path component that can be compared against a URL (which requires that the traffic for the route be HTTP based) such that multiple routes can be served using the same host name, each with a different path. Routers should match routes based on the most specific path to the least; however, this depends on the router implementation. The host name and path are passed through to the backend server so it should be able to successfully answer requests for them. For example: a request to http://example.com/foo/ that goes to the router will result in a pod seeing a request to http://example.com/foo/.
The following table shows example routes and their accessibility:
| Route | When Compared to | Accessible |
|---|---|---|
| www.example.com/test | www.example.com/test | Yes |
| www.example.com | No | |
| www.example.com/test and www.example.com | www.example.com/test | Yes |
| www.example.com | Yes | |
| www.example.com | www.example.com/test | Yes (Matched by the host, not the route) |
| www.example.com | Yes |
An Unsecured Route with a Path:
- 1
- The path is the only added attribute for a path-based route.
Path-based routing is not available when using passthrough TLS, as the router does not terminate TLS in that case and cannot read the contents of the request.
5.7.10.2. Secured Routes
Secured routes specify the TLS termination of the route and, optionally, provide a key and certificate(s).
TLS termination in OpenShift Container Platform relies on SNI for serving custom certificates. Any non-SNI traffic received on port 443 is handled with TLS termination and a default certificate (which may not match the requested host name, resulting in validation errors).
Secured routes can use any of the following three types of secure TLS termination.
Edge Termination
With edge termination, TLS termination occurs at the router, prior to proxying traffic to its destination. TLS certificates are served by the front end of the router, so they must be configured into the route, otherwise the router’s default certificate will be used for TLS termination.
A Secured Route Using Edge Termination
- 1 2
- The name of the object, which is limited to 63 characters.
- 3
- The
terminationfield isedgefor edge termination. - 4
- The
keyfield is the contents of the PEM format key file. - 5
- The
certificatefield is the contents of the PEM format certificate file. - 6
- An optional CA certificate may be required to establish a certificate chain for validation.
Because TLS is terminated at the router, connections from the router to the endpoints over the internal network are not encrypted.
Edge-terminated routes can specify an insecureEdgeTerminationPolicy that enables traffic on insecure schemes (HTTP) to be disabled, allowed or redirected. The allowed values for insecureEdgeTerminationPolicy are: None or empty (for disabled), Allow or Redirect. The default insecureEdgeTerminationPolicy is to disable traffic on the insecure scheme. A common use case is to allow content to be served via a secure scheme but serve the assets (example images, stylesheets and javascript) via the insecure scheme.
A Secured Route Using Edge Termination Allowing HTTP Traffic
A Secured Route Using Edge Termination Redirecting HTTP Traffic to HTTPS
Passthrough Termination
With passthrough termination, encrypted traffic is sent straight to the destination without the router providing TLS termination. Therefore no key or certificate is required.
A Secured Route Using Passthrough Termination
The destination pod is responsible for serving certificates for the traffic at the endpoint. This is currently the only method that can support requiring client certificates (also known as two-way authentication).
Passthrough routes can also have an insecureEdgeTerminationPolicy. The only valid values are None (or empty, for disabled) or Redirect.
Re-encryption Termination
Re-encryption is a variation on edge termination where the router terminates TLS with a certificate, then re-encrypts its connection to the endpoint which may have a different certificate. Therefore the full path of the connection is encrypted, even over the internal network. The router uses health checks to determine the authenticity of the host.
A Secured Route Using Re-Encrypt Termination
- 1 2
- The name of the object, which is limited to 63 characters.
- 3
- The
terminationfield is set toreencrypt. Other fields are as in edge termination. - 4
- Required for re-encryption.
destinationCACertificatespecifies a CA certificate to validate the endpoint certificate, securing the connection from the router to the destination pods. If the service is using a service signing certificate, or the administrator has specified a default CA certificate for the router and the service has a certificate signed by that CA, this field can be omitted.
If the destinationCACertificate field is left empty, the router automatically leverages the certificate authority that is generated for service serving certificates, and is injected into every pod as /var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt. This allows new routes that leverage end-to-end encryption without having to generate a certificate for the route. This is useful for custom routers or the F5 router, which might not allow the destinationCACertificate unless the administrator has allowed it.
Re-encrypt routes can have an insecureEdgeTerminationPolicy with all of the same values as edge-terminated routes.
5.7.11. Router Sharding
In OpenShift Container Platform, each route can have any number of labels in its metadata field. A router uses selectors (also known as a selection expression) to select a subset of routes from the entire pool of routes to serve. A selection expression can also involve labels on the route’s namespace. The selected routes form a router shard. You can create and modify router shards independently from the routes, themselves.
This design supports traditional sharding as well as overlapped sharding. In traditional sharding, the selection results in no overlapping sets and a route belongs to exactly one shard. In overlapped sharding, the selection results in overlapping sets and a route can belong to many different shards. For example, a single route may belong to a SLA=high shard (but not SLA=medium or SLA=low shards), as well as a geo=west shard (but not a geo=east shard).
Another example of overlapped sharding is a set of routers that select based on namespace of the route:
| Router | Selection | Namespaces |
|---|---|---|
| router-1 |
|
|
| router-2 |
|
|
| router-3 |
|
|
Both router-2 and router-3 serve routes that are in the namespaces Q*, R*, S*, T*. To change this example from overlapped to traditional sharding, we could change the selection of router-2 to K* — P*, which would eliminate the overlap.
When routers are sharded, a given route is bound to zero or more routers in the group. The route binding ensures uniqueness of the route across the shard. Uniqueness allows secure and non-secure versions of the same route to exist within a single shard. This implies that routes now have a visible life cycle that moves from created to bound to active.
In the sharded environment the first route to hit the shard reserves the right to exist there indefinitely, even across restarts.
During a green/blue deployment a route may be selected in multiple routers. An OpenShift Container Platform application administrator may wish to bleed traffic from one version of the application to another and then turn off the old version.
Sharding can be done by the administrator at a cluster level and by the user at a project/namespace level. When namespace labels are used, the service account for the router must have cluster-reader permission to permit the router to access the labels in the namespace.
For two or more routes that claim the same host name, the resolution order is based on the age of the route and the oldest route would win the claim to that host. In the case of sharded routers, routes are selected based on their labels matching the router’s selection criteria. There is no consistent way to determine when labels are added to a route. So if an older route claiming an existing host name is "re-labelled" to match the router’s selection criteria, it will replace the existing route based on the above mentioned resolution order (oldest route wins).
5.7.12. Alternate Backends and Weights
A route is usually associated with one service through the to: token with kind: Service. All of the requests to the route are handled by endpoints in the service based on the load balancing strategy.
It is possible to have as many as four services supporting the route. The portion of requests that are handled by each service is governed by the service weight.
The first service is entered using the to: token as before, and up to three additional services can be entered using the alternateBackend: token. Each service must be kind: Service which is the default.
Each service has a weight associated with it. The portion of requests handled by the service is weight / sum_of_all_weights. When a service has more than one endpoint, the service’s weight is distributed among the endpoints with each endpoint getting at least 1. If the service weight is 0 each of the service’s endpoints will get 0.
The weight must be in the range 0-256. The default is 100. When the weight is 0, the service does not participate in load-balancing but continues to serve existing persistent connections.
When using alternateBackends also use the roundrobin load balancing strategy to ensure requests are distributed as expected to the services based on weight. roundrobin can be set for a route using a route annotation, or for the router in general using an environment variable.
The following is an example route configuration using alternate backends for A/B deployments.
A Route with alternateBackends and weights:
- 1
- This route uses
roundrobinload balancing strategy. - 2
- The first service name is
service-namewhich may have 0 or more pods - 4 6
- The alternateBackend services may also have 0 or more pods
- 3 5 7
- The total
weightis 40.service-namewill get 20/40 or 1/2 of the requests,service-name2andservice-name3will each get 1/4 of the requests, assuming each service has 1 or more endpoints.
5.7.13. Route-specific Annotations
Using environment variables, a router can set the default options for all the routes it exposes. An individual route can override some of these defaults by providing specific configurations in its annotations.
Route Annotations
For all the items outlined in this section, you can set annotations on the route definition for the route to alter its configuration
| Variable | Description | Environment Variable Used as Default |
|---|---|---|
|
|
Sets the load-balancing algorithm. Available options are |
|
|
|
Disables the use of cookies to track related connections. If set to | |
|
| Specifies an optional cookie to use for this route. The name must consist of any combination of upper and lower case letters, digits, "_", and "-". The default is the hashed internal key name for the route. | |
|
| Sets the maximum number of connections that are allowed to a backing pod from a router. Note: if there are multiple pods, each can have this many connections. But if you have multiple routers, there is no coordination among them, each may connect this many times. If not set, or set to 0, there is no limit. | |
|
|
Setting | |
|
| Limits the number of concurrent TCP connections shared by an IP address. | |
|
| Limits the rate at which an IP address can make HTTP requests. | |
|
| Limits the rate at which an IP address can make TCP connections. | |
|
| Sets a server-side timeout for the route. (TimeUnits) |
|
|
| Sets the interval for the back-end health checks. (TimeUnits) |
|
|
| Sets a whitelist for the route. | |
|
| Sets a Strict-Transport-Security header for the edge terminated or re-encrypt route. | |
|
| Sets a value to restrict cookies. The values are:
This value is applicable to re-encrypt and edge routes only. For more information, see the SameSite cookies documentation. |
A Route Setting Custom Timeout
- 1
- Specifies the new timeout with HAProxy supported units (us, ms, s, m, h, d). If unit not provided, ms is the default.
Setting a server-side timeout value for passthrough routes too low can cause WebSocket connections to timeout frequently on that route.
5.7.14. Route-specific IP Whitelists
You can restrict access to a route to a select set of IP addresses by adding the haproxy.router.openshift.io/ip_whitelist annotation on the route. The whitelist is a space-separated list of IP addresses and/or CIDRs for the approved source addresses. Requests from IP addresses that are not in the whitelist are dropped.
Some examples:
When editing a route, add the following annotation to define the desired source IP’s. Alternatively, use oc annotate route <name>.
Allow only one specific IP address:
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10Allow several IP addresses:
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10 192.168.1.11 192.168.1.12
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10 192.168.1.11 192.168.1.12Allow an IP CIDR network:
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.0/24
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.0/24Allow mixed IP addresses and IP CIDR networks:
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 180.5.61.153 192.168.1.0/24 10.0.0.0/8
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 180.5.61.153 192.168.1.0/24 10.0.0.0/85.7.15. Creating Routes Specifying a Wildcard Subdomain Policy
A wildcard policy allows a user to define a route that covers all hosts within a domain (when the router is configured to allow it). A route can specify a wildcard policy as part of its configuration using the wildcardPolicy field. Any routers run with a policy allowing wildcard routes will expose the route appropriately based on the wildcard policy.
Learn how to configure HAProxy routers to allow wildcard routes.
A Route Specifying a Subdomain WildcardPolicy
5.7.16. Route Status
The route status field is only set by routers. If changes are made to a route so that a router no longer serves a specific route, the status becomes stale. The routers do not clear the route status field. To remove the stale entries in the route status, use the clear-route-status script.
5.7.17. Denying or Allowing Certain Domains in Routes
A router can be configured to deny or allow a specific subset of domains from the host names in a route using the ROUTER_DENIED_DOMAINS and ROUTER_ALLOWED_DOMAINS environment variables.
|
| Domains listed are not allowed in any indicated routes. |
|
| Only the domains listed are allowed in any indicated routes. |
The domains in the list of denied domains take precedence over the list of allowed domains. Meaning OpenShift Container Platform first checks the deny list (if applicable), and if the host name is not in the list of denied domains, it then checks the list of allowed domains. However, the list of allowed domains is more restrictive, and ensures that the router only admits routes with hosts that belong to that list.
For example, to deny the [*.]open.header.test, [*.]openshift.org and [*.]block.it routes for the myrouter route, run the following two commands:
oc adm router myrouter ...
$ oc adm router myrouter ...oc set env dc/myrouter ROUTER_DENIED_DOMAINS="open.header.test, openshift.org, block.it"
$ oc set env dc/myrouter ROUTER_DENIED_DOMAINS="open.header.test, openshift.org, block.it"
This means that myrouter will admit the following based on the route’s name:
oc expose service/<name> --hostname="foo.header.test"
$ oc expose service/<name> --hostname="foo.header.test"oc expose service/<name> --hostname="www.allow.it"
$ oc expose service/<name> --hostname="www.allow.it"oc expose service/<name> --hostname="www.openshift.test"
$ oc expose service/<name> --hostname="www.openshift.test"
However, myrouter will deny the following:
oc expose service/<name> --hostname="open.header.test"
$ oc expose service/<name> --hostname="open.header.test"oc expose service/<name> --hostname="www.open.header.test"
$ oc expose service/<name> --hostname="www.open.header.test"oc expose service/<name> --hostname="block.it"
$ oc expose service/<name> --hostname="block.it"oc expose service/<name> --hostname="franco.baresi.block.it"
$ oc expose service/<name> --hostname="franco.baresi.block.it"oc expose service/<name> --hostname="openshift.org"
$ oc expose service/<name> --hostname="openshift.org"oc expose service/<name> --hostname="api.openshift.org"
$ oc expose service/<name> --hostname="api.openshift.org"
Alternatively, to block any routes where the host name is not set to [*.]stickshift.org or [*.]kates.net, run the following two commands:
oc adm router myrouter ...
$ oc adm router myrouter ...oc set env dc/myrouter ROUTER_ALLOWED_DOMAINS="stickshift.org, kates.net"
$ oc set env dc/myrouter ROUTER_ALLOWED_DOMAINS="stickshift.org, kates.net"
This means that the myrouter router will admit:
oc expose service/<name> --hostname="stickshift.org"
$ oc expose service/<name> --hostname="stickshift.org"oc expose service/<name> --hostname="www.stickshift.org"
$ oc expose service/<name> --hostname="www.stickshift.org"oc expose service/<name> --hostname="kates.net"
$ oc expose service/<name> --hostname="kates.net"oc expose service/<name> --hostname="api.kates.net"
$ oc expose service/<name> --hostname="api.kates.net"oc expose service/<name> --hostname="erno.r.kube.kates.net"
$ oc expose service/<name> --hostname="erno.r.kube.kates.net"
However, myrouter will deny the following:
oc expose service/<name> --hostname="www.open.header.test"
$ oc expose service/<name> --hostname="www.open.header.test"oc expose service/<name> --hostname="drive.ottomatic.org"
$ oc expose service/<name> --hostname="drive.ottomatic.org"oc expose service/<name> --hostname="www.wayless.com"
$ oc expose service/<name> --hostname="www.wayless.com"oc expose service/<name> --hostname="www.deny.it"
$ oc expose service/<name> --hostname="www.deny.it"To implement both scenarios, run the following two commands:
oc adm router adrouter ...
$ oc adm router adrouter ...oc set env dc/adrouter ROUTER_ALLOWED_DOMAINS="okd.io, kates.net" \
ROUTER_DENIED_DOMAINS="ops.openshift.org, metrics.kates.net"
$ oc set env dc/adrouter ROUTER_ALLOWED_DOMAINS="okd.io, kates.net" \
ROUTER_DENIED_DOMAINS="ops.openshift.org, metrics.kates.net"
This will allow any routes where the host name is set to [*.]openshift.org or [*.]kates.net, and not allow any routes where the host name is set to [*.]ops.openshift.org or [*.]metrics.kates.net.
Therefore, the following will be denied:
oc expose service/<name> --hostname="www.open.header.test"
$ oc expose service/<name> --hostname="www.open.header.test"oc expose service/<name> --hostname="ops.openshift.org"
$ oc expose service/<name> --hostname="ops.openshift.org"oc expose service/<name> --hostname="log.ops.openshift.org"
$ oc expose service/<name> --hostname="log.ops.openshift.org"oc expose service/<name> --hostname="www.block.it"
$ oc expose service/<name> --hostname="www.block.it"oc expose service/<name> --hostname="metrics.kates.net"
$ oc expose service/<name> --hostname="metrics.kates.net"oc expose service/<name> --hostname="int.metrics.kates.net"
$ oc expose service/<name> --hostname="int.metrics.kates.net"However, the following will be allowed:
oc expose service/<name> --hostname="openshift.org"
$ oc expose service/<name> --hostname="openshift.org"oc expose service/<name> --hostname="api.openshift.org"
$ oc expose service/<name> --hostname="api.openshift.org"oc expose service/<name> --hostname="m.api.openshift.org"
$ oc expose service/<name> --hostname="m.api.openshift.org"oc expose service/<name> --hostname="kates.net"
$ oc expose service/<name> --hostname="kates.net"oc expose service/<name> --hostname="api.kates.net"
$ oc expose service/<name> --hostname="api.kates.net"5.7.18. Support for Kubernetes ingress objects
The Kubernetes ingress object is a configuration object determining how inbound connections reach internal services. OpenShift Container Platform has support for these objects using a ingress controller configuration file.
This controller watches ingress objects and creates one or more routes to satisfy the conditions of the ingress object. The controller is also responsible for keeping the ingress object and generated route objects synchronized. This includes giving generated routes permissions on the secrets associated with the ingress object.
For example, an ingress object configured as:
generates the following route object:
- 1
- The name is generated by the route objects, with the ingress name as a prefix.
In order for a route to be created, an ingress object must have a host, service, and path.
5.7.19. Disabling the Namespace Ownership Check
Hosts and subdomains are owned by the namespace of the route that first makes the claim. Other routes created in the namespace can make claims on the subdomain. All other namespaces are prevented from making claims on the claimed hosts and subdomains. The namespace that owns the host also owns all paths associated with the host, for example www.abc.xyz/path1.
For example, if the host www.abc.xyz is not claimed by any route. Creating route r1 with host www.abc.xyz in namespace ns1 makes namespace ns1 the owner of host www.abc.xyz and subdomain abc.xyz for wildcard routes. If another namespace, ns2, tries to create a route with say a different path www.abc.xyz/path1/path2, it would fail because a route in another namespace (ns1 in this case) owns that host.
With wildcard routes the namespace that owns the subdomain owns all hosts in the subdomain. If a namespace owns subdomain abc.xyz as in the above example, another namespace cannot claim z.abc.xyz.
By disabling the namespace ownership rules, you can disable these restrictions and allow hosts (and subdomains) to be claimed across namespaces.
If you decide to disable the namespace ownership checks in your router, be aware that this allows end users to claim ownership of hosts across namespaces. While this change can be desirable in certain development environments, use this feature with caution in production environments, and ensure that your cluster policy has locked down untrusted end users from creating routes.
For example, with ROUTER_DISABLE_NAMESPACE_OWNERSHIP_CHECK=true, if namespace ns1 creates the oldest route r1 www.abc.xyz, it owns only the hostname (+ path). Another namespace can create a wildcard route even though it does not have the oldest route in that subdomain (abc.xyz) and we could potentially have other namespaces claiming other non-wildcard overlapping hosts (for example, foo.abc.xyz, bar.abc.xyz, baz.abc.xyz) and their claims would be granted.
Any other namespace (for example, ns2) can now create a route r2 www.abc.xyz/p1/p2, and it would be admitted. Similarly another namespace (ns3) can also create a route wildthing.abc.xyz with a subdomain wildcard policy and it can own the wildcard.
As this example demonstrates, the policy ROUTER_DISABLE_NAMESPACE_OWNERSHIP_CHECK=true is more lax and allows claims across namespaces. The only time the router would reject a route with the namespace ownership disabled is if the host+path is already claimed.
For example, if a new route rx tries to claim www.abc.xyz/p1/p2, it would be rejected as route r2 owns that host+path combination. This is true whether route rx is in the same namespace or other namespace since the exact host+path is already claimed.
This feature can be set during router creation or by setting an environment variable in the router’s deployment configuration.
Set During Router Creation
oc adm router ... --disable-namespace-ownership-check=true
$ oc adm router ... --disable-namespace-ownership-check=trueSet Environment Variable in Router Deployment Configuration
oc set env dc/router ROUTER_DISABLE_NAMESPACE_OWNERSHIP_CHECK=true
$ oc set env dc/router ROUTER_DISABLE_NAMESPACE_OWNERSHIP_CHECK=true